第一章 绪论
1.1 研究背景和意义
随着科学技术和生活水平的迅速发展,人们越来越重视身体的健康,对医疗的服务水平的要求不断提高,电子健康记录(Electronic Health Record, EHR)系统由此产生。构建互联互通的医疗服务信息平台,可以更加便捷、快速的管理患者的医疗信息,减少不必要的资源浪费。EHR 中记录了患者各种与健康相关的生理检测指标[1],蕴含了大量的医学知识,因此 EHR 是很有研究价值的数据资源。
通过使用计算机技术对医疗数据分析,使得医务人员和患者都可以更好的处理病情。首先对于患者,EHR 中包含了病人的过去、现在患病的所有信息。通过计算机完成人类无法完成的高速计算,分析患者的病情,为患者的健康提出有效的建议,对疾病及时发现及时治疗;对于医疗人员,医生可以通过数据分析为患者的病情提前做好准备,从以前诊断出疾病再治疗转换到疾病提前发现提前治疗,能够提前预知患者未来的病情是至关重要的。因此不管是对患者还是医务人员,利用 EHR 数据分析提前对患者情况进行预测对临床研究都有重要意义。
1.1 研究背景和意义
随着科学技术和生活水平的迅速发展,人们越来越重视身体的健康,对医疗的服务水平的要求不断提高,电子健康记录(Electronic Health Record, EHR)系统由此产生。构建互联互通的医疗服务信息平台,可以更加便捷、快速的管理患者的医疗信息,减少不必要的资源浪费。EHR 中记录了患者各种与健康相关的生理检测指标[1],蕴含了大量的医学知识,因此 EHR 是很有研究价值的数据资源。
通过使用计算机技术对医疗数据分析,使得医务人员和患者都可以更好的处理病情。首先对于患者,EHR 中包含了病人的过去、现在患病的所有信息。通过计算机完成人类无法完成的高速计算,分析患者的病情,为患者的健康提出有效的建议,对疾病及时发现及时治疗;对于医疗人员,医生可以通过数据分析为患者的病情提前做好准备,从以前诊断出疾病再治疗转换到疾病提前发现提前治疗,能够提前预知患者未来的病情是至关重要的。因此不管是对患者还是医务人员,利用 EHR 数据分析提前对患者情况进行预测对临床研究都有重要意义。
临床事件预测方法的研究中需要大量的医疗数据,EHR 中含有患者住院期间所有的诊断记录,研究人员通过算法分析当前面临的医疗问题,例如住院死亡率预测、住院时长预测、疾病预测、病症分类预测等。通过患者入院期间检测的数据预测院内的死亡率,能够提前发现病重的患者,提前为患者的病情做准备[2];住院时长的预测可以减少患者的医疗费用和医院的医疗资源,尽早的识别长期住院的患者,让患者得到有效的治疗,缓解医院的资源紧张问题为更多的患者提高更好的医疗救助[3];同样疾病预测可以预测患者可能患的疾病,医生针对患者的疾病进行有效的治疗,因此构建预测方法对医疗进程有很大的帮助[4]。
.......................
1.2 国内外研究现状
1.2.1 电子健康记录
EHR 为患者电子化的病历文件,随着智慧医疗、互联网医疗的推出,EHR 系统的使用频率大大增加,并且可以尽量减少医疗中的错误、提高医疗效率和改善病人的护理,同时也为研究人员提供了丰富的数据来源。深度学习方法在 EHR 研究中得到广泛应用,主要包括 EHR 数据信息的提取[11]、表征学习[12]、结果预测[13]和文本的去标识[14]等。
信息的提取主要包括概念提取、时间事件提取、关系提取、以及缩写扩展。患者的住院信息中包含非结构化的数据,以前的方法需要大量的手动特征提取,因此最近的一些研究集中使用深度学习方法从临床笔记中提取相关的临床信息。Y.Lv 等人[15]使用标准的文本预处理方法和基于统一医学语言系统的词到概念映射与稀疏自动编码器结合使用,将生成的特征输入到条件随机场分类器,从而大大优于 EHR 关系提取中的现有技术。
表征学习主要包括概念表示和病人表示,最近的一些研究应用深度无监督表示学习技术得到 EHR 概念向量,以捕获医学概念之间潜在的相似性和自然簇,其主要目的是从稀疏医学编码中得到向量表示,以使相似的概念映射到较低维向量空间中;另一个是病人表示主要使用自然语言处理(Natural Language Processing,NLP)方法或者降维方法[16-17]。Minnaro Gimenez 等人[18]把 skip-gram 模型应用到医学文本中,表示专业的医学术语。
文本去标识主要是因为临床注释通常包括明确的个人健康信息[19],这使得很难公开发布许多有用的临床数据集。根据《健康信息携带和责任法案》的指南,所有发布的临床记录必须没有敏感信息,例如患者姓名及其代理人、身份证号码、医院名称和位置、地理位置和日期这些都属于敏感信息。Dernoncourt 等人[20]创建了用于临床自动识别的系统取代了传统上费力的手动识别流程,以共享受限数据,由 BiLSTM 网络以及字符级和单词级嵌入组成模型,并取得了很好的效果。
..........................
第二章 数据集和相关理论知识

................................
2.2 临床事件预测方法
目前基于 EHR 数据进行的预测方法有很多,本节主要讲解随机森林、支持向量机、循环神经网络三种方法
第三章 基于 Attention-LSTM 住院死亡率预测方法 ........................... 131.2.1 电子健康记录
EHR 为患者电子化的病历文件,随着智慧医疗、互联网医疗的推出,EHR 系统的使用频率大大增加,并且可以尽量减少医疗中的错误、提高医疗效率和改善病人的护理,同时也为研究人员提供了丰富的数据来源。深度学习方法在 EHR 研究中得到广泛应用,主要包括 EHR 数据信息的提取[11]、表征学习[12]、结果预测[13]和文本的去标识[14]等。
信息的提取主要包括概念提取、时间事件提取、关系提取、以及缩写扩展。患者的住院信息中包含非结构化的数据,以前的方法需要大量的手动特征提取,因此最近的一些研究集中使用深度学习方法从临床笔记中提取相关的临床信息。Y.Lv 等人[15]使用标准的文本预处理方法和基于统一医学语言系统的词到概念映射与稀疏自动编码器结合使用,将生成的特征输入到条件随机场分类器,从而大大优于 EHR 关系提取中的现有技术。
表征学习主要包括概念表示和病人表示,最近的一些研究应用深度无监督表示学习技术得到 EHR 概念向量,以捕获医学概念之间潜在的相似性和自然簇,其主要目的是从稀疏医学编码中得到向量表示,以使相似的概念映射到较低维向量空间中;另一个是病人表示主要使用自然语言处理(Natural Language Processing,NLP)方法或者降维方法[16-17]。Minnaro Gimenez 等人[18]把 skip-gram 模型应用到医学文本中,表示专业的医学术语。
文本去标识主要是因为临床注释通常包括明确的个人健康信息[19],这使得很难公开发布许多有用的临床数据集。根据《健康信息携带和责任法案》的指南,所有发布的临床记录必须没有敏感信息,例如患者姓名及其代理人、身份证号码、医院名称和位置、地理位置和日期这些都属于敏感信息。Dernoncourt 等人[20]创建了用于临床自动识别的系统取代了传统上费力的手动识别流程,以共享受限数据,由 BiLSTM 网络以及字符级和单词级嵌入组成模型,并取得了很好的效果。
..........................
第二章 数据集和相关理论知识
2.1 数据集
随着临床信息化建设的发展,医院都会产生结构化、非结构化、半结构化数据,这些数据分散,为了能够更好的实现医疗健康数据的系统化,创建电子健康病历是迫在眉睫的,实验中使用的数据集是 MIMIC-III(Medical Information Mart for Intensive Care,MIMIC-III)[39],MIMIC-III 是大型开放的公共临床数据集,由麻省理工学院计算生理学实验室开发,包含了 2001-2012 年马萨诸塞州波士顿以色列医疗中心重症监护室入院患者的信息,其中包括 38645 个成年人(年龄>=16)和 7875 个新生儿。数据主要涵盖人口统计资料、床旁生命体征、实验室检查结果、手术、用药、监护记录、影像报告和死亡情况等。数据库中共有 26 张表,按照包含信息的不同,将其分为 4 部分,第一张表是病人人口学信息及院内周转信息,第二张表是病人在监护室住院期间采集的各类信息,第三张表是医院记录系统采集的各类信息,第四张表是字典信息,每一张表又包含了患者的具体信息。如下表所示:
随着临床信息化建设的发展,医院都会产生结构化、非结构化、半结构化数据,这些数据分散,为了能够更好的实现医疗健康数据的系统化,创建电子健康病历是迫在眉睫的,实验中使用的数据集是 MIMIC-III(Medical Information Mart for Intensive Care,MIMIC-III)[39],MIMIC-III 是大型开放的公共临床数据集,由麻省理工学院计算生理学实验室开发,包含了 2001-2012 年马萨诸塞州波士顿以色列医疗中心重症监护室入院患者的信息,其中包括 38645 个成年人(年龄>=16)和 7875 个新生儿。数据主要涵盖人口统计资料、床旁生命体征、实验室检查结果、手术、用药、监护记录、影像报告和死亡情况等。数据库中共有 26 张表,按照包含信息的不同,将其分为 4 部分,第一张表是病人人口学信息及院内周转信息,第二张表是病人在监护室住院期间采集的各类信息,第三张表是医院记录系统采集的各类信息,第四张表是字典信息,每一张表又包含了患者的具体信息。如下表所示:
................................
2.2 临床事件预测方法
目前基于 EHR 数据进行的预测方法有很多,本节主要讲解随机森林、支持向量机、循环神经网络三种方法
2.2.1 随机森林随机森林(Random Forest,
RF)最早由 Leo Breiman 和 Adele Cutler 提出的[40],它结合多个决策树进行预测,并通过投票或取平均值来获得最终的分类结果。RF 不仅可以处理高维度、连续和离散类型的数据,而且具有良好的抗噪能力,不易过度拟合。大量的理论和实验证明,RF 具有较高的准确性,受到了人们的高度关注。此外,它是数据挖掘、生物信息学等领域最流行的前沿研究领域之一。
随机森林的算法步骤如下
随机森林的算法步骤如下
(1)从大小为 m 的训练集中,进行 k 个采样替换,以生成 k 个训练集,并且每个采样都是通过使用 bootstrap 方法随机抽取 m 个样本。
(2)训练 k 个训练集以生成 k 个决策树。
(3)对于单个决策树,随机选择 n 个特征(n <N,N 为特征总数),根据信息增益或Gini 系数或其他指标对决策树进行分割,每次特征选择具有较强分类能力的产品。
(2)训练 k 个训练集以生成 k 个决策树。
(3)对于单个决策树,随机选择 n 个特征(n <N,N 为特征总数),根据信息增益或Gini 系数或其他指标对决策树进行分割,每次特征选择具有较强分类能力的产品。
(4)每一个决策树在不进行任何调整的情况下增长到最大。
(5)将生成多个决策树以形成一个随机森林。对于分类问题,分类结果取决于弱分类器的票数。但 RF 也存在缺点,数据集噪音比较大的时候,RF 模型容易陷入过拟合。
...................................
(5)将生成多个决策树以形成一个随机森林。对于分类问题,分类结果取决于弱分类器的票数。但 RF 也存在缺点,数据集噪音比较大的时候,RF 模型容易陷入过拟合。
...................................
3.1 方法流程 ................................ 13
3.2 方法原理 ............................... 14
第四章 基于 BiLSTM 的临床事件预测方法 ....................................... 27
4.1 方法流程 .........................28
4.2 方法原理 ................................. 29
第五章 总结与展望 ..................................... 39
5.1 全文总结 ......................................... 39
5.2 未来工作展望 ............................ 40
第四章 基于 BiLSTM 的临床事件预测方法
4.1 方法流程
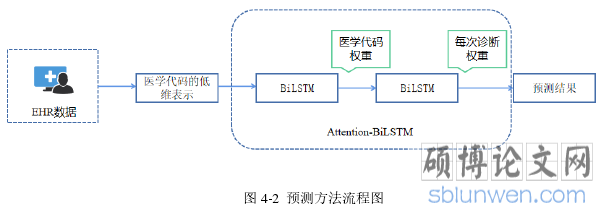
通过提取 EHR 数据中患者的基本信息和患者的 ICD-9 编码,使用 BiLSTM 对时间序列的数据进行编码,并结合诊断代码的权重和每次诊断的权重,进而预测患者的死亡率和患者疾病诊断代码,对病人的死亡预测是很重要的一项任务,在患者住院的早期确定患者死亡率的高低,并将死亡率高的人确定为高危病人,医生可以及时根据病人的状态制定病人的治疗方案,预测患者疾病诊断代码可以模仿医生对患者的诊断,更好的了解患者的病情。图 4-2 显示了实验的具体步骤。
..........................
第五章 总结与展望
5.1 全文总结
论文从电子健康记录的分析角度出发提出了两种基于 LSTM 的临床事件预测方法。 论文首先介绍了 EHR 数据集在临床结果预测的研究背景及研究现状,然后回顾了临床结果预测常用的几种方法,例如 SVM、LR、RNN、LSTM,BiLSTM,通过对现有方法的分析发现了以下不足的地方,在 EHR 数据集上进行临床结果的预测面临许多挑战,比如数据质量差、维数高、相关字段缺失;以前的研究方法主要使用传统的机器学习方法,严重依赖于手动提取特征,需要花费大量的时间和精力.
5.1 全文总结
论文从电子健康记录的分析角度出发提出了两种基于 LSTM 的临床事件预测方法。 论文首先介绍了 EHR 数据集在临床结果预测的研究背景及研究现状,然后回顾了临床结果预测常用的几种方法,例如 SVM、LR、RNN、LSTM,BiLSTM,通过对现有方法的分析发现了以下不足的地方,在 EHR 数据集上进行临床结果的预测面临许多挑战,比如数据质量差、维数高、相关字段缺失;以前的研究方法主要使用传统的机器学习方法,严重依赖于手动提取特征,需要花费大量的时间和精力.
针对上述的不足,论文分别在第三章和第四章提出两种临床结果的预测方法,论文第三章提出一种基于 Attention-LSTM 住院死亡率预测方法,使用 skip-gram 方法对 EHR 中的生理指标进行向量化表示,然后将生成的向量输入经过训练的改进 LSTM 分类网络中并结合注意机制,预测病人的死亡率,实验结果表明该方法提高了死亡预测的准确率,与 SVM、LR 方法相比,该方法更好的完成患者死亡率的预测,论文第四章提出了基于 BiLSTM 的临床事件预测方法。使用 doc2vec 的 skip-gram 方法对 EHR 中的诊断代码进行向量化表示,将生成的向量输入 BiLSTM 中,并结合注意机制计算每个疾病编码的权重,然后再输入到BiLSTM 中,结合注意机制计算每次诊断的权重,最后对临床结果进行预测。BiLSTM 可以供给输出层输入序列中每一个点的完整的过去和未来的上下文信息,像医生在为患者诊断时要查看病人以前的诊断记录,可以更好的对病人的病情诊断,与 SVM、LR、RNN、LSTM 相比,该方法预测的准确率更高。
参考文献(略)
参考文献(略)