1 绪论
1.1 研究工作的背景与意义
在现代社会中,对于人体的研究是当前科学家与各位学者所研究的重点,而对于研究人体的行为则是对于人的研究中的重中之重。在现实中对于人体行为的识别有很多待解决的困难点,例如人体姿态多样性的识别,当人体在做瑜伽或者进行地板翻滚动作时,人体的姿态与平时人体常态下的姿态是截然不同的,而人们多样的服饰也会影响在实验中对于人体骨架提取的效果。在现阶段中针对这些困难点,研究学者们化繁为简,将人体简化为线状的骨架来进行提取,这样可以一定程度上快速进行识别进而分析人体的动作与行为,也为过后其他方向的视觉研究方向奠定了研究基础。
在传统时期科技水平落后,电子计算机等科技产品还未广泛应用,人们对于人体动作的研究只能靠简单的人工工具设计来进行度量,或者是通过人们本身的眼力与经验来进行人体行为的判断,这样的研究方法损耗了大量的人力以及金钱,所以传统时期也即信息时代未来临之前,对于人体行为的识别有许多不足。
1.1 研究工作的背景与意义
在现代社会中,对于人体的研究是当前科学家与各位学者所研究的重点,而对于研究人体的行为则是对于人的研究中的重中之重。在现实中对于人体行为的识别有很多待解决的困难点,例如人体姿态多样性的识别,当人体在做瑜伽或者进行地板翻滚动作时,人体的姿态与平时人体常态下的姿态是截然不同的,而人们多样的服饰也会影响在实验中对于人体骨架提取的效果。在现阶段中针对这些困难点,研究学者们化繁为简,将人体简化为线状的骨架来进行提取,这样可以一定程度上快速进行识别进而分析人体的动作与行为,也为过后其他方向的视觉研究方向奠定了研究基础。
在传统时期科技水平落后,电子计算机等科技产品还未广泛应用,人们对于人体动作的研究只能靠简单的人工工具设计来进行度量,或者是通过人们本身的眼力与经验来进行人体行为的判断,这样的研究方法损耗了大量的人力以及金钱,所以传统时期也即信息时代未来临之前,对于人体行为的识别有许多不足。
随着电子计算机的快速发展,科技水平指数级的增高,信息时代来临使得电脑处理数据的水平越来越迅速,一定程度上解放了人力,节约了时间,并且相对于个人判断所有的主观性与经验性,电子计算机对于识别的精度与客观性具有非常大的优势,因此相关对于人体动作的识别在处于高速发展的阶段。
在实际的行为分析中,人们会对计算机所识别的人体动作作为判断的基准,接着赋予特定动作以特殊含义,比如在实际监控场景中,摄像头会捕捉人体的动作来判断人们是否在进行危险动作或者多人斗殴,针对小孩的监控会识别是否在进行不安全的攀爬等,而在运动领域与舞蹈领域,专家会根据识别的人体骨架图来对运动员或者舞蹈演员的动作进行判断或与标准行为的对比来进行打分,运动员与舞蹈演员也可以根据分析结果来对自己的动作进行纠正与改进。
............................
3 基于图片的多人骨架提取................................ 17在实际的行为分析中,人们会对计算机所识别的人体动作作为判断的基准,接着赋予特定动作以特殊含义,比如在实际监控场景中,摄像头会捕捉人体的动作来判断人们是否在进行危险动作或者多人斗殴,针对小孩的监控会识别是否在进行不安全的攀爬等,而在运动领域与舞蹈领域,专家会根据识别的人体骨架图来对运动员或者舞蹈演员的动作进行判断或与标准行为的对比来进行打分,运动员与舞蹈演员也可以根据分析结果来对自己的动作进行纠正与改进。
............................
1.2 国内外研究现状及难点
1.2.1 国内外研究现状
在 1973 年,Fischler 和 Elschlager 提出图形结构(PS,Pictorial Structures)[1],也是最早提出的人体骨架模型,这种模型能很好的表征人体的结构特点,也能快速的从图片中获取人体识别图,其经典程度在现阶段大多对于人体骨架提取的方案都是基于此模型进行后续的研究,例如 Andriluka[2]等人就将此模型进行实际应用,对人体在图片中检测其二维骨架信息。但是随着深度相机的发展,针对深度图像对于人体骨架的提取取得了长足的进步,但是深度图片的获取需要昂贵的设备,在考虑廉价性等因素,大多数针对此问题的研究使用 RGB 图像来进行处理。
对于人体骨节点在 RGB 图片中提取主要分为两个时间段,一是传统时期,这个时间段通常采用人工设计特征利用图模型来进行关键点的检测。二是深度学习时期,这个时间点主要使用卷积神经网络来进行关节点的提取。
传统方法时期在手工设计特征提取主要的方法有:HOG、形状内容描述子[3]、其他方法的综合[4]。而传统方法建模采用的最多就是树结构模型[5-7],这种方法会把人体的关键点表示成图节点,但是这种方法过于依赖单个模型的准确性。基于此思路过后的建模方法是将多个人体的建模模型进行整合[8-14],有的研究者也在加一些循环的边来加强模型检测的鲁棒性[15-19]。但是有些研究者开始分析本源,他们对树形结构的建模产生怀疑,于是使用非树的结构进行人体建模,比如对人体关键点之间的相似性进行检测、或者采用其他图模型建模等[20-24]。
相较于传统时期的方法,在近几年,随着电脑硬件水平的提高,电子计算机计算能力飞速发展,图像处理技术也随着显卡的发展 GPU 等的进步有了明显的提高,现有的研究者也大多使用深度学习的方法来处理之前使用传统方法的研究,其中卷积神经网络是深度学习中最常用的方法,也是最有效的方法之一。卷积神经网络相较于传统的神经网络更加的高效与方便,其优越性在于不用人们手工的去设计方案和提取特征,而是根据设计者的目标需要自动的学习输入的图片中所想要的特征。在二十世纪九十年代,卷积神经网络最先被研究者 LeCun[25]等应用到图片处理,当时使用卷积神经网络对手写数字进行识别,接下来后续的研究者 Krizhevsky 和 Hinton 将此方法应用在了图片的分类上[26],并相较于之前的方法取得了较好的效果。因为良好的针对图片特征的提取[27],现在对于图片中人体骨架的研究[28-30]大多使用此方法。
..............................
2 相关理论和技术
2.1 卷积神经网络概述
卷积神经网络是一类包含卷积计算且具有深度结构的前馈神经网络,对卷积神经网络的研究始于二十世纪 80 至 90 年代,时间延迟网络和 LeNet-5[48]是最早出现的卷积神经网络。在二十一世纪后,随着深度学习理论的提出和数值计算设备的改进,卷积神经网络得到了快速发展并被大量应用于计算机视觉、自然语言处理等领域。本小节从卷积神经网络结构与训练方法以及优化算法三个方面对卷积神经网络进行阐述。
2.1.1 卷积神经网络

..........................
2.2 常用卷积神经网络
2.2.1 VGG-Net
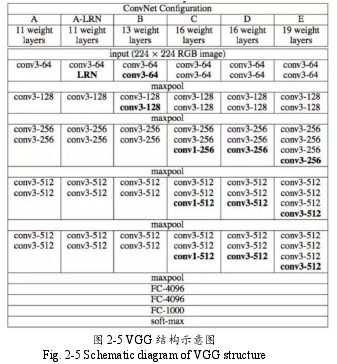
VGG-Net[50]在 2014 年提出,该网络在一定程度上论证了卷积神经网络的层数与识别的效果有很大的关系,常用基于此网络使用的模型有 VGG-16 与 VGG-19,但两者本质原理没有区别。VGG 主要的特点是使用 33? 的卷积核代替之前网络使用的大卷积核,这样设计的原因是在感受野相同的情况下加深网络的深度。
1.2.1 国内外研究现状
在 1973 年,Fischler 和 Elschlager 提出图形结构(PS,Pictorial Structures)[1],也是最早提出的人体骨架模型,这种模型能很好的表征人体的结构特点,也能快速的从图片中获取人体识别图,其经典程度在现阶段大多对于人体骨架提取的方案都是基于此模型进行后续的研究,例如 Andriluka[2]等人就将此模型进行实际应用,对人体在图片中检测其二维骨架信息。但是随着深度相机的发展,针对深度图像对于人体骨架的提取取得了长足的进步,但是深度图片的获取需要昂贵的设备,在考虑廉价性等因素,大多数针对此问题的研究使用 RGB 图像来进行处理。
对于人体骨节点在 RGB 图片中提取主要分为两个时间段,一是传统时期,这个时间段通常采用人工设计特征利用图模型来进行关键点的检测。二是深度学习时期,这个时间点主要使用卷积神经网络来进行关节点的提取。
传统方法时期在手工设计特征提取主要的方法有:HOG、形状内容描述子[3]、其他方法的综合[4]。而传统方法建模采用的最多就是树结构模型[5-7],这种方法会把人体的关键点表示成图节点,但是这种方法过于依赖单个模型的准确性。基于此思路过后的建模方法是将多个人体的建模模型进行整合[8-14],有的研究者也在加一些循环的边来加强模型检测的鲁棒性[15-19]。但是有些研究者开始分析本源,他们对树形结构的建模产生怀疑,于是使用非树的结构进行人体建模,比如对人体关键点之间的相似性进行检测、或者采用其他图模型建模等[20-24]。
相较于传统时期的方法,在近几年,随着电脑硬件水平的提高,电子计算机计算能力飞速发展,图像处理技术也随着显卡的发展 GPU 等的进步有了明显的提高,现有的研究者也大多使用深度学习的方法来处理之前使用传统方法的研究,其中卷积神经网络是深度学习中最常用的方法,也是最有效的方法之一。卷积神经网络相较于传统的神经网络更加的高效与方便,其优越性在于不用人们手工的去设计方案和提取特征,而是根据设计者的目标需要自动的学习输入的图片中所想要的特征。在二十世纪九十年代,卷积神经网络最先被研究者 LeCun[25]等应用到图片处理,当时使用卷积神经网络对手写数字进行识别,接下来后续的研究者 Krizhevsky 和 Hinton 将此方法应用在了图片的分类上[26],并相较于之前的方法取得了较好的效果。因为良好的针对图片特征的提取[27],现在对于图片中人体骨架的研究[28-30]大多使用此方法。
..............................
2 相关理论和技术
2.1 卷积神经网络概述
卷积神经网络是一类包含卷积计算且具有深度结构的前馈神经网络,对卷积神经网络的研究始于二十世纪 80 至 90 年代,时间延迟网络和 LeNet-5[48]是最早出现的卷积神经网络。在二十一世纪后,随着深度学习理论的提出和数值计算设备的改进,卷积神经网络得到了快速发展并被大量应用于计算机视觉、自然语言处理等领域。本小节从卷积神经网络结构与训练方法以及优化算法三个方面对卷积神经网络进行阐述。
2.1.1 卷积神经网络
..........................
2.2 常用卷积神经网络
2.2.1 VGG-Net
VGG-Net[50]在 2014 年提出,该网络在一定程度上论证了卷积神经网络的层数与识别的效果有很大的关系,常用基于此网络使用的模型有 VGG-16 与 VGG-19,但两者本质原理没有区别。VGG 主要的特点是使用 33? 的卷积核代替之前网络使用的大卷积核,这样设计的原因是在感受野相同的情况下加深网络的深度。
VGG 网络主要的优点是结构简洁,VGG-16 只由 13 个卷积层和三个全连接层组成,VGG 网络还侧面的验证了网络深度越深,网络整体的精度也会随之升高。但 VGG 网络也有其的不足之处,主要的缺点是 VGG 网络会占用过大的计算机资源,参数量过多,在训练时训练时间过长。
.........................3.1 多人提取算法概论.................................... 17
3.1.1 自顶向下............................ 17
3.1.2 自底向上................................ 18
4 基于视频的多人骨架提取.................................. 33
4.1 视频中关节点检测......................................... 33
4.2 基于 RNN 的多人骨架提取算法.....................................33
5 全文总结与展望............................ 49
5.1 本文总结......................................... 49
5.2 未来工作................................... 49
4 基于视频的多人骨架提取
4.1 视频中关节点检测
在实际生活中对于多人骨架识别领域在视频中的应用价值高于基于图片的识别。相对于静态图片,针对视频的识别更加的复杂。视频的信息量远高于图片,识别难度较大。现阶段使用的方法大多寻找视频中单帧所包含的空间场景也即空间信息,还有寻找相邻帧之间携带的目标运动信息也即时间信息。
传统方法中对视频的识别往往工作量过多,需要人工进行特征提取设计。深度学习方法能够直接利用原始视频进行端到端的训练,为视频行为识别提供了高效的特征表示。
本章主要采用两种方法来针对视频中的多人人体进行骨架提取,在第一个方法中引入改进的 RNN[62]也即 GRU[63]来学习视频中时序的信息来优化视频的识别效果;在第二个方法中将视频的多人骨架提取与目标识别跟踪方法进行联系,使用 IOU 跟踪算法[64]来寻找视频帧于帧之间的关系,最终得到识别效果。
...........................
5 全文总结与展望
5.1 本文总结
人体骨架提取是计算机视觉领域的一个非常重要的研究项目,它在人机交互,视频监控、行人识别、人体姿态骨架等领域起着重要作用。在目前阶段,基于图片针对单人的骨架提取有了很高很精准的识别效果,但是在识别多人的场景下,识别难度会有指数级的提高,现阶段在此方面的识别还有很大的提高空间。
本文中总结了一些针对单人以及多人识别现阶段比较优秀的算法,针对静态图片的多人骨架提取,本文首先分析了自上而下和自底向上两种针对多人骨架提取的研究方法的差异,并在自底向上方向探讨了人体关节点的提取以及亲和域向量对关节点分配的优化,并在现有识别效果较好的深度学习模型残差网络的基础上进行了针对此课题的细节上的改进,最后以 MPII 图数据库作为数据集,对比得出此方法在此领域有良好的识别效果。
接下来本文探讨了针对视频的多人骨架提取算法。视频在某方面跟静态图片的识别有非常多的相似性,视频在某一方面可以看作多帧图片在时间域上的连续,所以寻找多帧之间在时间域上的关系对于视频识别有着重要关系。本文主要使用了两种方案对此问题进行研究。在第一个方案中基于之前针对静态图片的识别方法的基础上,探讨了 RNN 对于人体关节点在时空域上的优化,并使用了改进的 RNN 模型 GRU 来做为寻找关节点联系的模型。在第二个方案中在单帧图片中采用自底向上的思路,利用 Faster R-CNN 进行人体检测框的检测,并在人体检测框中进行各人的骨架提取,接下来利用 IOU 跟踪算法寻找帧于帧在时空域上的联系来优化识别的效果,通过在 PoseTrack 数据集上做对比实验,两种方法都取得了良好的识别效果,最终对两种方案在运行效率与速度上进行了分析。
参考文献(略)