本文是一篇计算机论文,笔者认为文本分类是文本数据挖掘技术的一个重要组成部分,是处理和组织大量错综复杂的文本数据的重要技术,可以在一定程度上解决信息数据杂乱无章的问题,实现信息分流,帮助用户快速准确地定位到有效信息的所在。
1 绪论
1.1 研究背景与意义
如今,数据信息总量呈指数增长,大量信息以数字文本的形式呈现,倘若仅凭借传统人工方法对这些文本数据进行组织和管理,不但需要耗费大量的物力和人力,而且也难以实现。这迫使人们寻找一种新的技术,能够高效、精准地组织和管理这些冗杂的信息,使真正有效的信息数据清晰明了地呈现出来,文本挖掘技术便是解决这一问题的有效途径。文本分类是文本信息挖掘的基本功能,也是处理和组织文本数据的核心技术,能够有效地辅助人们组织和分类信息数据,使信息杂乱的问题在较大程度上得到解决,对于信息的高效管理及有效利用都具有很强的现实的意义,以致文本分类技术成为了数据挖掘领域的重要研究方向之一。文本分类如今已经应用到多个领域中,如话题检测、垃圾邮件过滤、短信过滤、作者识别、网页分类和情感分析等。越来越多的学者都投入到了文本分类的研究之中,出现了许多新的或改进的文本分类方法和技术。与此同时,文本分类技术的飞速发展也带来了前所未遇的困难和挑战,在理论和实践上文本分类技术的研究仍存在很大的发展空间。
文本分类技术主要涉及有文本预处理、降维、特征加权、构造分类器、分类性能评价等多个过程。由于文本数据信息的非结构化的特性,在操作这类数据信息之前需要对其进行预处理工作。文本预处理可以把非结构化的文本数据信息转化成结构化的形式,同时在一定程度上减少特征词数量。但文本在经过预处理之后,特征词的数量依旧很多,特征空间的维数仍然过于庞大,即便是规模很小的语料库,其特征词数量也会很轻易的达到几万甚至几十万。这不仅会耗费巨大的存储空间和运行时间,而且一些噪声特征会对文本分类造成一定的干扰,最终影响分类的准确度和效率。因此,还需要更进一步地减少特征词的数量,降低特征空间的维数。如何从原始特征空间中选择出具有较强类别区分能力的特征词就是特征选择的目的。特征选择是文本分类中的一个重要问题,能够不牺牲分类性能的情况下缩减特征空间大小,同时避免过度拟合现象的产生。其主要思想是按照某种规则从原本的高维特征集合空间中将对文本分类没有多大贡献的特征词删除,选取出一部分最为有效的、最具有代表性的特征词构成新的特征子集。通过特征选择这一步骤,一些和需求无关的特征词会被剔除,使文本特征集合空间的维数得到大幅度降低,进而提高文本分类的效率和精度。
......................
1.2 研究现状
1.2.1 文本分类研究现状
文本分类在国际上的研究开始的较早,可以追溯到 20 世纪 50 年代。1957 年,美国IBM 公司的 H.P.Luhn 首次提出将词频统计的思想用于文本分类研究,这使自动文本分类领域有了里程碑式地突破。随后 M.E.Maron 于 1960 年在 Journal of ACM 上发表了有关于自动文本分类的第一篇文章,即“On relevance,probabilistic indexing and information retrieval”。论文中探讨了关键词自动分类技术,该论文的发表预示着自动文本分类时代的到来。在文本表示方面,G.Salton 等人提出了空间向量模型(vector space model,VSM),将文本特征抽象为特征空间向量,如今该模型因其简洁有效性而被广泛运用于文本的表示当中。此后,众多学者如 K.sparch 和 R.M.Needham 等都在该领域进行了大量研究且卓有成效。
总体来说,国外对文本分类的研究大致分为三个阶段:
(1)20 世纪 80 年代之前:基于知识工程的文本自动分类系统。该阶段主要是对文本自动分类的可行性进行探究。
(2)20 世纪 80 年代到 90 年代:基于统计的机器学习文本自动分类系统。在这一阶段,对文本分类技术的研究主要集中于理论研究同时进行实验分析。根据领域专家人工建立的知识形成规则产生分类器,结合传统知识工程技术对文本进行分类成为主流。
(3)20 世纪 90 年代以后:基于语义的文本自动分类系统。这一阶段文本自动分类技术已经较为成熟,人们开始将分类的理论与实际相结合,进入自动分类的实用性阶段。
.........................
2 相关理论
2.1 基础理论
文本分类(Text Categorization,也作 Text Classification,缩写为 TC)是指根据大量已标注类别属性的文本集合,将待分类的未知类别的文本自动地划分到某一类或某几类的过程。
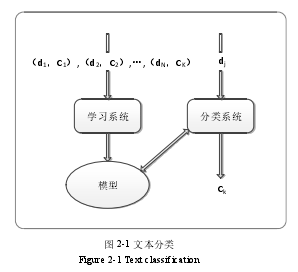
文本表示:文本数据的结构通常具有复杂、多元化的特点,然而计算机无法像人类一样可以直接对文本的内容产生感性认知,因此,需要采用某种规则来量化这些文本数据,使机器能够直接处理它们。选择怎样的语言元素作为特征词,以及选择哪种模型来结构化表征文本对象是文本表示模块需要解决的问题。
降维:经过预处理和文本表示等操作后,特征数量规模依旧十分庞大。为了实现有效的文本分类,需要从特征集合中选取出对类别最具有区分能力的特征词,达到缩减特征维度的目的,以降低文本分类过程中的时空复杂度,提高分类器的分类性能。降维通常包括特征提取和特征选择两种方法。
特征加权:在降维后需要对特征词进行加权处理,依据不同的权重计算规则得到的权值不同,一个合理有效的加权算法可以对不同质量的特征词赋予不同的权重值,从而提高分类的准确率。
构造分类器:如何构造出一个合适且高效文本分类器是文本分类方法中一个重要的研究内容。在设计分类器时,首先需要足够数量的已知类别属性的样本集合作为训练集,通过对训练集的分析学习训练出分类器,然后用训练得到的分类器实现对待分类对象的分类工作。
.......................
2.2 文本预处理
文本预处理是文本分类的基础工作,有效的文本预处理可以减少原始数据集合中的噪声,使文本分类快速高效地执行。文本预处理通常包括去除格式标记、分词、词干提取、去停用词等步骤,下面将对这些方法进行简要介绍。
(1)去除格式标记
通常情况下,不同语料库有着自己特定的存储格式,文本中除了有用的文本信息以外,还会存在一些与分类无关的标记,例如标点符号、数字、图片、动画、甚至乱码等。对于一些由超文本标记语言(HTML)构成的语料库,除了标题正文等有效内容外,还存在着大量格式标签等无用标记。这些冗余的标记与文本内容无关,对文本的分类没有任何帮助,应当去除。
(2)分词
与英文等类似语种清晰明了的单词分割相比,中文、日文等东方语种没有空格这一天然的切分标志,多以“字”为基本构造单位,而“词”作为文本信息的最小载体单元,具有更明显、更充足的语义信息。因此,在中文文本分类中,更倾向于以“词”作为分类的特征词。分词就是为了将文本正确地划分成“词”单元。分词质量的好坏会直接影响到文本分类的最终结果。
......................
3 基于分词频文档频率的特征选择算法 ........................ 17
3.1 相关特征选择算法 ....................... 17
3.2 STF-DF 算法 ...................... 19
4 基于分词频逆类频率的特征选择算法 ................. 33
4.1 相关特征选择算法 ................... 33
4.2 STF-ICF 算法 .............. 33
5 总结与展望.......................... 45
5.1 工作总结 ............................... 45
5.2 工作展望 ............................ 45
4 基于分词频逆类频率的特征选择算法
4.1 STF-ICF 算法
4.1.1算法研究动机
在 2.5.2 节中介绍到,逆文档频率 IDF 常用于表示特征词对文档的区分能力,如果特征词在语料库中的众多文档中都出现,即文档频率很高,那么就说明该特征词对于文档的区分能力很弱。IDF 在区分特征词所在文档与其他文档的能力方面具有较好的效果,被广泛应用于文本分类领域,但是该方法存在一定缺陷,即忽略了对于文本分类来说十分重要的类别信息。逆类频率 ICF很好的弥补了这个缺陷,类似于逆文档频率,逆类频率常用来表示特征词对类别的区分能力,如果特征词在语料库中的大多数类别中都出现,即类别频率很高,那么就说明该特征词对于类别的区分能力很差。逆类频率计算公式如下:

...........................
5 总结与展望
5.1 工作总结
随着互联网技术的迅猛普及,大量的电子文本信息涌现在网上,这些文本数据虽然丰富了人们的生活,但是也产生了许多无用信息,导致了数据规模庞大但实际有效信息却十分匾乏的现象。在这种情况下,用户想要在海量的数据中找寻到真正有效的信息,犹如大海捞针,困难重重。因此,文本数据的合理有效应用是当前信息科学技术领域面临的一大挑战。文本分类是文本数据挖掘技术的一个重要组成部分,是处理和组织大量错综复杂的文本数据的重要技术,可以在一定程度上解决信息数据杂乱无章的问题,实现信息分流,帮助用户快速准确地定位到有效信息的所在。
论文主要工作有以下几个方面:
(1)分析了文本分类的研究背景和意义,对文本分类及特征选择技术的国内外研究现状做了详细阐述,并以提高分类的性能为主线对文本分类过程中的各项相关技术,包括文本预处理、降维、特征加权、构造分类器和分类性能评估等做了较完整的介绍。
(2)提出了分词频和分词频文档频率两个全新的概念,设计并实现了一种基于分词频文档频率的特征选择算法(STF-DF)。该算法在进行特征选择时,充分考虑了不同词频的同一个特征词对分类的影响。实验阶段,选择朴素贝叶斯和 KNN 两种分类算法在20NewsGroups,Classic3 和 WebKB 三种常见数据集上进行实验验证。采用1micro− F 和精确率两种评价指标,与 DF、IG、CHI、t-test、CMFS 和 NDM 六种特征选择算法进行对比。实验结果显示,STF-DF 算法具有良好的分类性能。
(3)设计并实现了一种基于分词频逆类频率的特征选择算法(STF-ICF),该算法在分词频的理论基础上,提出分词频类别频率和加权平均类别频率两个全新的概念。在进行特征选择时,该算法弥补了逆类频率 ICF 方法的不足之处,更准确得对特征词的重要程度进行衡量。实验阶段,采用朴素贝叶斯分类器在 WAP、K1a、K1b、RE0 和 RE1 五种数据集上将 STF-ICF 算法与 DF、CMFS、DFS 以及 OCFS 进行对比。实验结果表明,STF-ICF 算法在1micro− F 及精确率两方面表现优秀,是一种有效的特征选择方法。
参考文献(略)
基于分词频的特征选择算法在文本分类中的计算机软件研究
论文价格:免费
论文用途:其他
编辑:硕博论文网
点击次数:
如果您有论文相关需求,可以通过下面的方式联系我们
点击联系客服