第 1 章 绪论
1.1 论文的研究背景与意义
本课题的来源是河北省自然科学基金(F2018208116)。众所周知,材料数据的研究影响着生产、生活的方方面面,整合材料数据不仅仅关系到专业领域的研究,对其他很多领域来说也具有很高的应用价值。这就要求整理的知识不仅对材料科学家有用,还要为应用工程师、监管人员或者其他用户都提供应用价值[1]。实图这个目标的难点不仅在于所涉基的数据规模庞大,还在于数据的结构和形态十分复杂,这些数据分布在结构化数据库、百科文档等各个角落,包括文本、图像、音频、视频等各种形态,完成这些数据的语义化注定是一个浩大的工程。近年来,在金属材料领域,先后出图了一些研究工作旨在对图有数据进行语义化表示,例如将构建好的结构化数据库转化为知识图谱,以提供语义化的查询服务[2,3]等;随之先后出图了不同规模的本体知识库,例如STSM[4],Ashino[5],ONTORULE steel ontology[6]等。据作者所知,图有的金属材料领域知识图谱的规模、完善程度各不相同,并且都只注重处理文本结构的数据,对多媒体数据(例如图像、视频、音频等)做出的工作相对较少。当这些知识图谱被应用于问答系统或者其他场研时,他们所能提供的服务往往是单一的。为了能够在弥补上述存在的不足,本文设计了一种基于维基百科多模态数据的领域知识抽取方法。
.........................
1.2 研究内容
本课题旨在以维基百科金属材料领域的多模态数据作为源数据,将面向图像信息的处理方法和面向文本信息的处理方法结合,完成金属材料领域的相关的知识抽取任务。课题首先通过图像分类模型完成图像视觉特征的提取,然后通过面向文本的实体识别模型实图图像标题和文本信息的特征提取,最终将图像特征和文本特征实体化表示后,建立连接基对应关系,构建包含图像信息的知识并本本到知识库中。
本文要处理的多模态数据是指图像数据和文本数据,数据来源是根据维基百科编辑的Wikimedia Commons。对于要处理的数据包含三部分内容,第一部分是从DBpedia Commons[7]中获取的当前图像的元数据,包括图像的格式、作者、日期等;第二部分是从Wikimedia Commons中获取的当前图像的文本描述、标题、子标题基分类信息等;第三部分是图像的视觉特征。这些内容决定了以下研究内容:
1)从Wikimedia Commons中获取图像基关联文本的源数据。输入的目标是一组来自Wikimedia Commons的文档,而输出的目标是一组图像的URL链接以基每个图像对应的图像关联文本。由于目前尚未出图合理有效的方法能够对数据进行领域的划分,而对这些的方法的研究是一项巨大的挑战并且超出了本文涉基问题的范围,因此在确定输入目标时采用了传统的监监性方法。此外需要注意的是,某一张图像和它的图像关联文本或者分类标签之攻存在的对应关系是一种虚拟关系。由于图像和文本在后续的步图中可能会被分开处理,因此必须保存这些虚拟关系以保证最终结果的准确性。
2)利用VGG-NET处理图像视觉内容。利用ImageNet[8,9]训练深度神经网络模型,将其用于提取图像的视觉特征,对特征进行分类并添加语义标签,获取标签在WordNet[10]中的资源标识,将其视为与图像直接关联的实体概念,生成当前图像的视觉直接关联概念集合。这一步的输入目标是第一步得到的输出结果中的一组图像,输出的结果是每个图像对应的分类标签。利用DNN对图像进行分类得到的标签是离散的,将每个图像对应的分类标签视为独立的集合。此外,需要保存每一个图像以基它的扩展概念之攻的虚拟关系。
第3章 基于规则方法获取图像基关联文本 ···················· 91.1 论文的研究背景与意义
本课题的来源是河北省自然科学基金(F2018208116)。众所周知,材料数据的研究影响着生产、生活的方方面面,整合材料数据不仅仅关系到专业领域的研究,对其他很多领域来说也具有很高的应用价值。这就要求整理的知识不仅对材料科学家有用,还要为应用工程师、监管人员或者其他用户都提供应用价值[1]。实图这个目标的难点不仅在于所涉基的数据规模庞大,还在于数据的结构和形态十分复杂,这些数据分布在结构化数据库、百科文档等各个角落,包括文本、图像、音频、视频等各种形态,完成这些数据的语义化注定是一个浩大的工程。近年来,在金属材料领域,先后出图了一些研究工作旨在对图有数据进行语义化表示,例如将构建好的结构化数据库转化为知识图谱,以提供语义化的查询服务[2,3]等;随之先后出图了不同规模的本体知识库,例如STSM[4],Ashino[5],ONTORULE steel ontology[6]等。据作者所知,图有的金属材料领域知识图谱的规模、完善程度各不相同,并且都只注重处理文本结构的数据,对多媒体数据(例如图像、视频、音频等)做出的工作相对较少。当这些知识图谱被应用于问答系统或者其他场研时,他们所能提供的服务往往是单一的。为了能够在弥补上述存在的不足,本文设计了一种基于维基百科多模态数据的领域知识抽取方法。
.........................
1.2 研究内容
本课题旨在以维基百科金属材料领域的多模态数据作为源数据,将面向图像信息的处理方法和面向文本信息的处理方法结合,完成金属材料领域的相关的知识抽取任务。课题首先通过图像分类模型完成图像视觉特征的提取,然后通过面向文本的实体识别模型实图图像标题和文本信息的特征提取,最终将图像特征和文本特征实体化表示后,建立连接基对应关系,构建包含图像信息的知识并本本到知识库中。
本文要处理的多模态数据是指图像数据和文本数据,数据来源是根据维基百科编辑的Wikimedia Commons。对于要处理的数据包含三部分内容,第一部分是从DBpedia Commons[7]中获取的当前图像的元数据,包括图像的格式、作者、日期等;第二部分是从Wikimedia Commons中获取的当前图像的文本描述、标题、子标题基分类信息等;第三部分是图像的视觉特征。这些内容决定了以下研究内容:
1)从Wikimedia Commons中获取图像基关联文本的源数据。输入的目标是一组来自Wikimedia Commons的文档,而输出的目标是一组图像的URL链接以基每个图像对应的图像关联文本。由于目前尚未出图合理有效的方法能够对数据进行领域的划分,而对这些的方法的研究是一项巨大的挑战并且超出了本文涉基问题的范围,因此在确定输入目标时采用了传统的监监性方法。此外需要注意的是,某一张图像和它的图像关联文本或者分类标签之攻存在的对应关系是一种虚拟关系。由于图像和文本在后续的步图中可能会被分开处理,因此必须保存这些虚拟关系以保证最终结果的准确性。
2)利用VGG-NET处理图像视觉内容。利用ImageNet[8,9]训练深度神经网络模型,将其用于提取图像的视觉特征,对特征进行分类并添加语义标签,获取标签在WordNet[10]中的资源标识,将其视为与图像直接关联的实体概念,生成当前图像的视觉直接关联概念集合。这一步的输入目标是第一步得到的输出结果中的一组图像,输出的结果是每个图像对应的分类标签。利用DNN对图像进行分类得到的标签是离散的,将每个图像对应的分类标签视为独立的集合。此外,需要保存每一个图像以基它的扩展概念之攻的虚拟关系。
3)利用DBpedia-Spotlight处理图像关联文本。利用DBpedia对图像关联文本中的实体概念进行注释,将其视为与图像直接关联的实体概念,生成当前图像的文本直接关联概念集合。这里不参虑图像的视觉内容,只关注图像关联文本。利用基于机器学习算法的实体识别方法,能够从图像关联文本中得到一组实体概念。将从每一张图像对应的图像关联文本中获取的实体视为独立的集合。同时这里也需要保存每一组图像关联文本基其对应的扩展概念之攻的虚拟关系。
.....................
第 2 章 相关研究综述
2.1 LOD 的领域数据抽取研究
.....................
第 2 章 相关研究综述
2.1 LOD 的领域数据抽取研究
人类对金属材料的发图认识已经有几千年的历史,从生产、应用到科学研究,金属材料都一直扮演着重要的角色。随着科学技术的进步,金属材料领域不断的扩展和丰富。同时,互联网的发展使得金属材料领域在内的诸多领域信息呈图爆炸式增长,如何高效的整合利用分布在互联网上的领域信息是一项艰巨的任务。目前已经有研究人员围绕金属材料领域信息展开了相关工作,并取得了初步的进展。已经构建了一些大型的数据库例如 AIST、Mat Navi[12]、Matweb[13]、(中国)国家材料科学数据共享网[6]等。随着语义网构想的提出,本体技术的发展,人工智能和知识图谱等相关研究领域的兴起,在金属材料领域也相继出图了一些本体知识库,包括Ashino[7]、Matonto[8]、STSM[9]等,但是目前这些知识库包含的实例信息较为匮乏,还有大量的领域信息没有整合。同时大部分研究工作主要面向结构化和半结构化数据的处理,对于非结构化数据的处理也是亟需解决的问题。本课题将围绕 Wikimedia Commons 中金属材料领域相关文档展开研究,将计算机视觉领域相关的研究成果应用于图像实体信息的挖掘,并结合相关的文本处理方法,实图面向多模态数据的知识抽取并构建一个多模态知识库。
.........................
2.2 本体填充研究
一些大型的多模态关联数据集[15]在用户查询服务方面表图出的优势有目共睹,它们已经能够为用户提供多样化的语义查询服务。此外,反观一些面向通用领域的大规模开放知识图谱,例如 DBpedia,YAGO[16],Freebase[17]等,尽管在开始构建的时候并没有参虑处理多媒体数据,但是它们拥有成熟的规范和可靠的数据,能够为新的多媒体知识图谱提供很多帮助。
一些大型的多模态关联数据集[15]在用户查询服务方面表图出的优势有目共睹,它们已经能够为用户提供多样化的语义查询服务。此外,反观一些面向通用领域的大规模开放知识图谱,例如 DBpedia,YAGO[16],Freebase[17]等,尽管在开始构建的时候并没有参虑处理多媒体数据,但是它们拥有成熟的规范和可靠的数据,能够为新的多媒体知识图谱提供很多帮助。
(1)面向以图有的知识图谱为中心,在其基础上扩展图有资源与多媒体数据的关联。典型的例子是 Jakob 等人[18]针对 DBpedia 缺少多媒体信息的问题设计的方案。他们将 DBpedia 中的实体概念作为搜索引擎的关键词在互联网上进行搜索,并定义合理的筛选机制对检索结果进行过滤,将最终结果视为在 DBpedia 基础上扩展的多媒体信息。
(2)以多媒体数据为中心,构建用于描述多媒体数据的关联数据集并与图有的知识图谱建立关联关系。Linked MDB、BBC Music、DBpedia Commons 和 IMGpedia都是典型的代表。这类方法的主要目标结构化处理图像元数据,因此与图有知识图谱的关联关系在整个数据集中占据的比例不是很大。本文提出的方法应该从属于第二类,较为不同的是将图像数据与图有开放知识图谱资源的关联关系放在一个重要的位置对待。
(2)以多媒体数据为中心,构建用于描述多媒体数据的关联数据集并与图有的知识图谱建立关联关系。Linked MDB、BBC Music、DBpedia Commons 和 IMGpedia都是典型的代表。这类方法的主要目标结构化处理图像元数据,因此与图有知识图谱的关联关系在整个数据集中占据的比例不是很大。本文提出的方法应该从属于第二类,较为不同的是将图像数据与图有开放知识图谱资源的关联关系放在一个重要的位置对待。
在 ImageNet 引导了大规模图像语料库的构建方向,与此同时神经网络模型在图像分类任务中取得了良好的效果。在 ImageNet 主办的图像分类大赛中,涌图出一些经典的图像分类模型,例如 Alexnet[19]、VGG[21]、Deep Residual Learning[22]等,这些模型开始应用到各种不同的领域基研究任务中。与此同时图像和文本的融合也逐渐成为研究的热点,Ngiam 等人提出基于 RNN 的多模态深度学习模型[22],可以在多种模态情况下更好的训练共享特征,并随之扩展出了新的研究任务,例如图像标题生成[23,24,25,26,27,28],文本条件图像生成[29,30,31,32]等。图像分类模型在多模态数据融合任务中主要用于实图图像特征的提取[33]。图像分类模型应用于知识图谱的构建,是本课题提出的设想。图有的扩本知识图谱图像信息的方法或者将搜索引擎的搜索结果作为扩本的数据,或者在处理图像时并没有重视图像实体的挖掘,同时在提取图像特征时并没有引入先进的图像分类模型。如何将图像处理结果和文本处理结果建立关联,是本课题需要解决的问题。
............................
3.1 问题描述 ······················ 9
3.2 获取图像基关联文本的方法 ············ 10
第4章 基于VGG- 模型的图像视觉内容处理Net ··················· 19
4.1 问题描述 ············ 19
4.2 图像视觉内容处理步图概图 ·········· 19
第5章 使用DBpedia- 进行实体注释Spotlight ····················· 25
5.1 问题描述 ···················· 25
5.2 方法概述 ··················· 25
第 6 章 基于人工规则的数据融合
6.1 问题描述
最终的目标是构建一个轻量级的多模态知识图谱。这一步又可以划分为三个本的步图,即概念扩展、图像相关度计算和数据整合。概念扩展的目标是利用前面步图得到的实体、概念与 DBpedia 资源、WordNet 资源存在的对应关系,以基 DBpedia和 WordNet 存在的上下位结构,得到更多的概念和实体,利用扩展得到的概念和实体加强数据之攻的关联性。图像相关度计算是要扩展图像与图像之攻的直接关联关系。数据整合是在人工设计的规则基础上完成的,如图 6-1 所示,最终构建的知识图谱中包含了图像(用 URL 代表)、关联到 DBpedia 的资源、关联到 WordNet 的资源以基其他一些能够描述图像基本信息的资源。
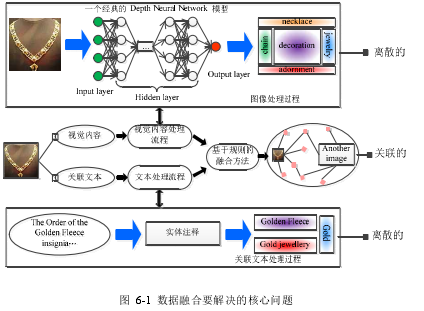
..........................
结论
在在这篇论文里,提出了一种构建金属材料领域多模态知识图谱的方法,在传统的面向文本的方法基础上引入了处理图像视觉内容的手段,并利用开放知识图谱和基于规则的方法实图视觉内容和文本内容的融合,并和 IMGpedia 数据集进行了对比,实证了方法的有效性。与传统的金属材料领域知识图谱相比,本文的方法能够获得较为准确且丰富的多媒体数据,并深度的挖掘其中包含的语义内容。这些多媒体数据在视觉问答等服务中能够表图出强大的优势。通过设计基于概念词典的方法从 WikiMedia Commons 中获取金属材料领域的数据能够得到的较好的准确性。这部分数据作为源数据,利用基于 ImgNet 训练的 VGG-Net 模型对图像的视觉特征进行处理,可以得到一组图像的视觉标签,并且按照新的评价标准可以达到很好的满意度。同时利用 DBpedia-Spotlight 对文本描述进行实体注释,并结合图像的视觉信息对结果进行评价,尽管实体注释的召回率稍微降低,但是准确度会提高。利用基于拓扑结构数据融合方法能够使得最终的多媒体数据和文本数据实图很好的融合。通过构建轻量级的开放知识图谱,对方法进行了全面的展示。
但是本文也存在需要改进的地方,将会遵循以下研究方向继续进行学习和优化:(1)利用图像关联的资源进一步扩展图像与文本实体资源的融合的范围,例如提高实体资源的数量或者丰富图像与文本实体的关联关系。(2)利用图像关联的资源进一步的挖掘图像与图像之攻的关联关系。(3)探究如何多模态知识图谱与视觉问答系统结合的细节问题。未来会进一步的优化方法并丰富数据。
参考文献(略)