计算机应用论文2018年精选范文一:保定广电网络施工项目管理信息系统的设计与实现
第 1 章 引言
1.1 选题背景及意义
保定广电网络公司在日常运行中,对于网络施工项目的管理是至关重要的一项工作,在广电网络公司增强自身竞争实力、践行社会责任的发展进程中,怎样合理进行施工项目管理是重中之重。当前,随着信息技术发展与应用的逐步深入,不少企业在日常管理方面引进先进的 IT 技术来提升项目管理水平、增强项目管理效率,夯实公司的综合竞争力。保定广电网络公司的施工项目管理是一项政策性、系统性强的工作,涉及公司内多个部门。因此公司统筹领导,相关部门分工负责,形成多部门协同、分级管理的机制,明确公司施工项目、财务、人事、资产、档案、纪检监察和审计等职能部门和项目负责人的权责,强化二级单位管理,加强分工与合作,将责任落到实处,形成“统一领导、协同合作、责任到人”的管理机制。怎样对广电网络施工项目的各类信息进行管理,对施工项目的完成质量进行验收,为保定广电网络公司的决策提供数据依据,是当前公司发展的重心,能够协助公司提升综合实力。如何积极引入适合的信息技术,构建保定广电网络公司的施工项目管理平台,是一个关乎公司发展的关键问题。
保定广电网络公司是经河北省政府批准,以广电网络资产为基础,以资本为纽带,通过行政推动、市场运作的方式,由保定区域广电企事业单位以广电网络资产评估入股的方式共同发起,于 2005 年 7 月 12 日正式挂牌成立,主营全市广播电视传输基本业务和高清电视、交互电视、有线宽带、数据专网等增值业务。按照《公司法》和《公司章程》,集团公司建立健全了由股东会、董事会、监事会和经理层组成的法人治理结构和现代企业管理体系,做到产权清晰、责权明确、政企分开、管理科学。保定广电网络公司实现施工项目管理的信息化,是一个必然的趋势。引入信息技术的管理模式一方面能够极大地减轻施工项目管理人员的工作量,使管理过程标准化和简单化,另一方面也能够借助先进的数据库管理系统提升管理的效率和准确率,提升项目管理水平。
结合施工项目管理工作的新形势、新特点和新要求,逐步完善涉及公司施工项目活动全过程及人财物各方面的管理办法、制度以及科学合理的工作流程,最终形成既有利于充分调动施工项目人员积极性,又具约束力,界限分明、程序规范、简洁易行、覆盖纵向横向项目的分级分类管理制度体系。可以说构建基于信息系统的广电网络施工项目管理模式是公司提升项目管理水平的必经之路。
.......................
1.2 国内外发展现状
在国外,有不少拥有技术实力的科研机构和公司都参与到项目管理信息系统的开发中,尤其是北美和日本一些发达国家的公司,一直以来都和软件开发机构进行合作,探讨开发适合公司项目管理需求的实用系统。对于施工项目管理信息系统的研究,国外已经开展多年。早在 1980 年代,国外一些机构便结合当时计算机技术和数据库技术的发展,开始将一些重要的施工项目管理功能转移到计算机处理模式。
在一些发达国家及地区,例如美国、欧洲等,随着硬件和软件的进步升级,对于施工项目管理系统的发展主要历经了以下几个阶段:最初是基于普通数据库的施工项目业绩统计系统、后来发展为施工项目信息更新系统、状态管理系统以及目前的引入智能化理论的决策支持系统。经过多年的发展,无论是公司的软硬件环境还是施工项目管理信息系统的易用性均已经发展到比较先进的阶段。通过施工项目管理系统,能够基本上涵盖施工项目管理中的主要流程和事务,从而使公司的管理模式发生了质的变化。
从信息系统的发展模式方面,目前绝大部分系统已经由最初的基于 C/S 的管理系统发展为如今的基于 B/S 的系统,从而实现了数据信息的存储集成化和操作分布化,而信息系统中的观念也逐步趋于完善,能够在很大程度上提升公司的施工项目管理效率和准确性,并能够与各类其他的系统实现数据互联互通,实现了信息的共享。当前,国外不少公司为了持续提升施工项目管理水平及效率,已经在将一些 ERP 的设计理念加入进去,从而开发出更具系统性的产品。可见在多年的技术发展和使用实践中,国外不少国家已经积累了较为丰富的系统开发经验,并且仍然处在不断改进的过程中。
应该指出的是,在我国,不少公司的管理模式和国外相比有所不同,因此其设计理念和方法虽然可以被我国借鉴,但应该将其完全转化为适应我国施工项目环境的系统,而不是直接使用。随着经济社会的发展以及各大公司之间竞争,一些公司已经开始使用施工项目管理系统,从最初的信息系统雏形发展至今,已经近 20 年。我国的信息技术应用在施工项目管理方面始于上世纪八十年代末,一些有条件的公司逐渐将计算机管理模式应用在项目管理、业绩管理、验收管理之中。
.....................
第 2 章 相关理论概述及项目的开发方法
2.1 广电网络施工项目管理信息系统概述
广电网络施工项目管理是一个涉及多方面管理的系统工程,它包含了工程、安全、合同、收费、维护等多个管理职能,涵盖了企业管理的多个方面。同时也是一个庞大的施工管理体系,从项目洽谈提出需求,到工程项目立项、开工审批,直至设计、施工、验收、财务结算,及至后续的线路维护,个人用户安装、迁移,用户信息维护、物料管理等等环节。这不仅仅是一个技术工程,更是一项包括人力物料管理的社会工程。
广电网络施工项目管理信息系统通过局域网和远程工作中相结合,实现数据信息的及时交流和共享。它是由人、系统终端、服务器组成,为广电网络施工项目信息的采集,及时交流共享、储存提供的保证。它能及时反映工程建设进度情况,用户入户率及安装情况,为公司提供准确详尽的工作进度,为下一步工程建设统筹提供了可靠依据。
.........................
2.2 广电网络施工项目管理信息系统开发方式选择
结合广电网络施工项目的具体情况,施工项目管理信息系统的实现可以有如下几种方式,体现在表 2.1 中:
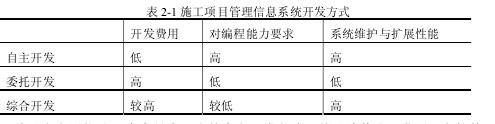
鉴于广电网络公司本身具有一定的自主开发能力,并且随着公司发展,在软件的维护与延续开发上有很大扩展空间,主要选择自主开发,利用现有软件包建立起适合企业应用和公司发展的管理程序。
在基本上确定了系统目标后,采用结构化生命周期法对本系统进行概要设计、详细设计,直至系统设计的实现、测试和运行。
......................
第 3 章 项目管理信息系统的需求分析 .................. 8
3.1 系统概述 ........................ 8
3.2 项目建设流程 ................ 9
3.1.1 工程立项 .............. 9
3.1.2 工程建设 ................ 9
第 4 章 项目管理系统的设计 .............. 23
4.1 系统开发技术及环境 ................ 23
4.1.1 J2EE 概述 .................. 23
4.1.2 MVC 开发架构 ...................... 23
第 5 章 项目系统的实现 ................ 40
5.1 系统开发和运行环境 ............. 40
5.2 功能模块的实现 ................. 40
5.3 本章小结 ..................... 45
第 5 章 项目系统的实现
结合系统实现的软件要求,本章将着重阐述主要功能模块的实现方法,根据施工项目管理系统的概要设计,使用 J2EE 和 SQLServer 实现管理系统的主要模块。
5.1 功能模块的实现
(1)施工项目信息管理功能的实现
本功能的目的是为满足保定广电网络公司对各类项目基本数据进行维护需求。此功能能够支持用户进行施工项目基本信息查询、对变动信息进行编辑维护、对不再具有项目完成关系的公司信息进行删除等。下图所示为增加施工项目信息的操作界面。

由界面图可知,具有“施工项目信息增添权限”的系统用户在登录施工项目管理系统,并选择“施工项目信息管理”模块功能后,可以对新的施工项目信息进行添加,包括序号、项目来源、研究年限、项目名称、验收日期、完成单位、项目经理、项目级别、项目类型、录入情况。这些数据将和其他信息一起,作为对施工项目进行验收的依据。
......................
第 6 章 总结与展望
6.1 总结
本文主要工作为: 对广电网络施工项目管理系统的用户需求进行分析,阐述信息系统开发的可行性,结合保定广电网络公司施工项目管理实际进行业务需求分析,在此基础上进行功能需求与非功能需求分析。
结合需求分析,对系统进行设计,包括系统层次设计、系统功能概要设计与系统详细设计,具体功能包括广电网络施工项目信息管理、验收项目管理、验收指标管理、验收报表管理、验收结果管理、系统用户管理、项目发布信息管理、信息检索模块设计,含有软件流程图以及类与方法的设计等。
结合系统设计,对系统的实现进行阐述,包括主要模块的实现,含有软件实现界面以及核心代码等。
参考文献(略)
计算机应用论文2018年精选范文二:基于高通量数据的转录调控预测分析与调控网络构建研究
第 1 章 绪 论
1.1 课题背景和意义
1.1.1 研究背景
人类关注并研究生物大分子在生物细胞中的结构与功能由来已久。沃森(J.Watson) 和克里克(F.Crick)对 DNA 双螺旋结构以及碱基互补配对原则的发现奠定了分子生物学的基础。克里克于 1954 年提出了遗传信息传递的中心法则(Central dogma):DNA 可以自身复制或作为模板合成 RNA,RNA 可以自身复制也可以作为合成蛋白质的模板。这一中心法则不仅指出了转录调控在生命体中的核心作用,更对分子生物学和生物信息学的发展都起到了提纲挈领的指导作用。
随着高通量测序技术的快速发展,科研人员可获得的生物数据日益增长,生物信息学的主要研究方向也相应的从生物数据的获取向生物数据的功能注释与作用解释转变。在后基因组时代,随着功能基因组学(Functional Genomics)的提出,人们更加关注于序列背后所隐藏的功能及与疾病之间的关系。转录因子(Transcription Factor 简称 TF)作为调控元件广泛参与了人体中基因的表达调控,近期的研究表明,转录因子还更广泛的参与了对非编码 RNA 如microRNA 和 lncRNA 的调控。深入了解人体中编码蛋白基因和非编码蛋白基因所受到的广泛而多样的转录调控、调控因素的时空分布情况、调控因素之间的相互关系与作用,对深入了解疾病形成的原因、确定疾病诊断的生物标记以及寻找新的治疗靶点等具有重要而不可替代的作用和重大意义。
1.1.2 研究的目的与意义
对基因表达的调控包含着一系列的过程,主要包括转录、选择性剪切、转录后调控、翻译等步骤。转录因子与 DNA 核苷酸的结合具有倾向性,往往倾向于同基因上游的启动子区或染色质中的增强子区域结合,这些结合位置被称为转录因子结合位点(Transcription Factor Binding Sites 简称 TFBS)。作为调控基因表达最起始环节的转录调控是对基因表达最根本的调控方式。转录因子在转录过程中的调控作用是非常重要而基本的,其中很多调控机制如 TF 的远距离调控、TFs 之间相互协作与影响等至今仍然不是十分清楚。通过计算的方法对转录因子结合位点进行预测,能够加深对转录过程、转录调控网络的相互作用的本质理解,为深入揭示人类疾病致病机理提供新的理论依据。
1.2 相关生物学背景
现代细胞分子生物学的研究往往围绕着中心法则展开。所谓中心法则(Central dogma of molecular biology)是指遗传信息的传递过程是从 DNA 到RNA 再到蛋白质的过程。具体而言在生物体内,DNA 可以自我复制,还可以通过转录过程(Transcription)将自身的信息传递到转录形成的 RNA 中;RNA也可以自身复制,或者通过逆转录过程(Reverse Transcription)将自身信息传递给 DNA,更普遍的生物过程是 RNA 通过翻译过程产生蛋白质。
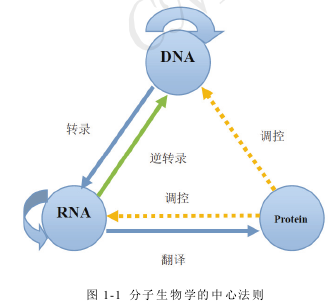
中心法则概括了生物学中信息传递与交互的本质过程,在这一过程中居于中心地位,起到承上启下作用的就是转录过程,只有通过转录、翻译,DNA所携带的信息才能真正表达为蛋白质,起到生物学作用。因此,对转录过程本身、转录因子对基因及其他生物元件的调控作用、以及转录过程受到哪些因素的调控、这些因素之间又是如何作用的深入了解,将会大大提高人们对生命过程本身、对人类衰老及退行性病变、肿瘤疾病等方面的本质理解,并为进而找到应对方法提供帮助。下面对本文研究中所涉及到的相关背景知识进行简要介绍。
第2章 基于基因组功能注释的高通量数据正则化方法
2.1 引言
对于 ChIP-Seq 实验产生的数据目前常用的正则化方式主要包括 TMR(total number of mapping reads)正则化方法和 Lowess 正则化方法。其中,TMR正则化方法是一种直接将各样本总体 reads 从数量上扩大或缩小的方式对不同生物条件下样本进行正则化的方法,但这种直接比例扩增的正则化方法根本没有考虑到样本内部 reads 的分布情况,常常造成较大的误差。LOWESS 正则化方法是曾被广泛用于 Chip-chip 数据正则化的方法,后被引入到对 ChIP-Seq 数据进行正则化处理。其中,Lowess 正则化方法通过对实验中对照组之间数据值的对数差异,以及对照组之间数据值的对数平均值进行局部加权平滑回归来对数据进行正则化处理。
但无论是 TMR 正则化方法还是 LOWESS 正则化方法都存在着一个巨大的缺陷:这些正则化方法根本没有考虑到基因组的结构对于其生物功能的影响。不同的 DNA 序列从功能上可以划分成基因区、基因间区、启动子区、3'和 5'非翻译区等等有着截然不同生物学功能的区域,这些区域在不同的细胞环境下其生物数据分别有着不同的分布特征。上述正则化方式笼统而机械地进行正则化处理无疑破坏了这种生物学特征,还可能人为引进不必要的误差。
为了克服现有新一代高通量测序技术正则化方法的这种不足,本章中提出了一种基于基因组序列生物功能注释的正则化方法,该正则化方法不仅能够保留样本数据中隐含的基因组结构信息,还避免了粗暴划分正则化区间造成的人为干扰,为本文后续章节预测分析提供分布良好、细节丰富的数据样本。
本章主要探讨了转录调控预测问题中通常涉及到的高通量数据正则化问题。首先介绍了目前处理ChIP-Seq数据的主要正则化方法包括TMR和LOWESS正则化方法。然后针对现有方法的不足之处提出一种基于基因组功能注释信息的LOWESS 正则化方法。最后对基于基因组功能注释信息的正则化方法的效果作出评价。
本章的其余部分安排如下:2.2 节讨论了常见的 ChIP-Seq 高通量数据正则化方式并对其优缺点进行了评价,然后针对这些方法的不足提出了一种新的基于基因组功能注释信息的 LOWESS 正则化方法在 2.3 节中进行了介绍。2.4 节比较了基于基因组功能注释信息的 LOWESS 正则化方法与现有方法的正则化结果。2.5 节对本章内容进行了小结。
2.2 现有 ChIP-Seq 高通量数据主要正则化方法
在生物实验中,实验数据中带有由实验工具或实验条件造成的系统性误差是不可避免的。目前对基因表达量或蛋白质之间相互作用进行实验确定的方法通常基于新一代测序技术中的ChIP-Seq实验进行。尽管与早期采用的RT-PCR或基于microarray微阵列芯片技术相比,ChIP-Seq实验得到的数据更加具有精确性和无偏性,但实验误差仍然会对研究带来阻碍,尤其是在不同条件下多样本对照的情况中。例如,在MCF7细胞的ChIP-Seq实验中,得到的原始数据与理想状况下reads的分布(拟合实线与理想情况虚线)存在偏差,如图2-1所示:
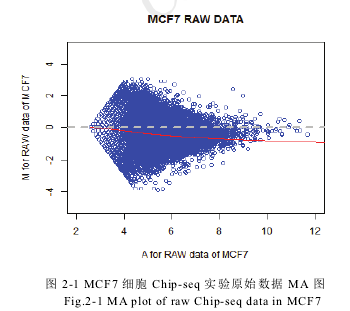
为保证不同条件下ChIP-Seq实验样本之间的可比较性,通常可以采用基于整体reads数量比较思想的TMR正则化方法或者基于局部平滑的LOWESS正则化方法对数据进行分析前的预处理。下面分别对这两类正则化方法进行简要的介绍。
第 3 章 基于 PolII 高通量数据的转录调控网络预测与功能分析 ........ 37
3.1 引言 ..... 37
3.2 基于 PolII 数据的转录调控预测方法 ............ 38
第 4 章 具有馈环结构的转录调控网络构建方法 ......... 60
4.1 引言 .............. 60
第 5 章 基于多数据融合的 TF-lncRNA 转录调控预测方法 ..............81
第 5 章 基于多数据融合的 TF-lncRNA 转录调控预测方法
5.1 引言
通过对前面章节介绍的基因和 microRNA 所受到转录调控的识别方法进行扩展,本章基于多类型特征数据研究了 TFs 对另一大类非编码 RNA(noncoding RNA,ncRNA)lncRNA 的转录调控识别问题。非编码 RNA 是对所有不编码蛋白质的 RNA 的统称,它们能够在 RNA 水平上行使重要调控功能。ncRNA包括很多不同种类,核苷酸的长度从20多到几十Kbp,其中有一类占ncRNA80%左右,长度超过 200bp 通常具有帽式结构和 poly-A 的被称之为长非编码 RNA(long noncoding RNA,lncRNA)。lncRNA 不仅数量相对较多而且在基因组上存在普遍转录现象,可以在表观遗传水平、转录水平和转录后水平上对基因表达进行调控,广泛参与着生命体生长发育到疾病相关等生理和病理过程。
已知的大多数 lncRNA 在一级结构上保守性非常低,无法利用传统的构建motif 的方式进行建模,同时虽然有些 lncRNA 在不同物种中非常保守,但对于大多数 lncRNA 而言其功能更多的表现出组织特异性。lncRNA 往往与多种人类肿瘤的发生发展密切相关。如肝细胞中 lncRNA H19 可以与其下游结合区中血管生成素以及成纤维细胞生长因子相互作用,改变相关基因的表达进而诱发肝脏肿瘤,同时 H19 也被认为参与了中枢神经系统髓母细胞瘤和脑膜瘤的发生发展。更多的 lncRNA 参与乳腺癌、前列腺癌、肺癌等肿瘤形成过程或作为标记物等被识别出也都有相关文献报道。
结论
转录调控是生命体中最基础而重要的调控方式之一,对人类转录调控机制的研究能够加深对转录过程、转录调控网络的本质理解。基于新一代测序技术的高通量数据,本研究分别在数据正则化方法、新的预测数据选择以及测度的显著性阈值选择方法、复杂转录调控预测与分析、转录调控网络构建等方面进行了研究。为深入理解转录因子在人类疾病的产生和发展中发挥调控作用生物学机制提供精确可靠的预测方法和理论依据。
本研究主要成果包括以下几个方面:
(1)本文提出了一种基于基因组功能注释的 LOWESS 正则化方法,改进了目前高通量测序数据正则化方法中没有考虑到基因组的结构对于生物数据分布的影响这一不足。与传统方法相比,本方法可以针对不同研究目的依据不同注释信息分区域进行数据正则化,具有更高的特异性和灵活性以及更低的时间和空间复杂度。
(2)本文基于转录调控预测的新数据源 PolII 数据在乳腺癌细胞中构建了高敏感性的转录调控预测流程和转录因子调控网络。针对现有转录因子间交互协作关系识别方法的不足,提出了综合显著性打分 SIS 测度以及相应的显著性阈值确定标准。通过对基于同样预测流程分别使用 PolII 和基因表达数据预测结果的比较分析证明了 PolII 数据能够为转录调控的预测提供更丰富信息。此外还进一步讨论了同一 TF 不同 motifs 的调控角色。文献分析及实验结果表明,本文识别的转录调控 TFs 及其调控网络具有非常高的可信性。
(3)本文针对多类型调控因子参与的转录调控问题,在人类宫颈癌细胞HeLa 中对 TFs、microRNA 及其调控基因组成的前馈和反馈调控通路进行了识别,构建了具有馈环调控结构的转录调控网络。本文构建了 TFs 对 microRNA调控区域模型,预测了参与调控的转录因子及其共调控因子,同时还对受到调控的靶基因进行了预测。本文新识别的调控模式有助于进一步增加对于转录因子在肿瘤中的复杂调控角色与作用机制的了解。
(4)本文提出一种基于朴素贝叶斯框架的整合多类型数据转录调控预测方法,通过对先验数据的建模和参数估计来对 TF-lncRNA 调控的后验概率进行预测。该模型整合利用了包括序列信息、染色质状态信息、表观遗传信息等多数据来源的信息,尤其是可以针对缺乏相应 TFs 的特征数据的情况下对该TF-lncRNA 结合位点进行准确预测。与相应 TFs 的 ChIP-Seq 实验结果比较证实了本文方法对于具有和缺乏相应特征数据的 TFs 都能够做出准确的预测。
参考文献(略)
计算机应用论文2018年精选范文三:基于神经网络的不平衡数据分类方法研究
第1章绪论
1.1研究背景与意义
分类是机器学习、数据挖掘等领域内非常重要的一个研究内容,在现实生活中有着广泛的应用:基因表达数据分析、医疗诊断、图像识别和故障检测等。如何通过对己知经验数据进行分析从而精准预测未知数据成为研究的重点。目前,已经有了一些相对成熟的分类方法,比如:k-近邻、神经网络、支持向量机等方法,这些方法对分布均勾的数据集显示出很好的效果,并获得了广泛的应用。但是,在现实生活中,所获取到的数据集往往出现类别间样本数不平衡、严重重叠和噪声干扰等特点,使传统的分类器及其学习算法无法达到预期效果。
数据集中各类之间的不平衡通常伴随着各类在样本空间上的重叠,研究表明,数据集的各类之间样本的不平衡不是造成分类器分类准确率不高的唯一因素,类之间的样本在样本空间上的重叠也是影响分类器性能的原因之一。有些学者甚至认为:不管在数据集中各类之间的样本平衡与否,数据集的类之间样本重叠现象都会给分类器的性能带来很大的影响。因此,在研究不平衡数据集学习问题时,也应该考虑到各类在样本空间上的重叠问题。如何缓解甚至消除各类在样本空间上的重叠给传统分类器性能带来的影响,也是亟需解决的问题。


1.2论文的主要工作
本文针对不平衡学习问题,从数据集和算法两个层面入手,分析了不平衡数据集对现有分类器的影响,特别是对神经网络性能的影响,重点研究了基于神经网络的不平衡数据分类技术。论文的主要研究工作有以下几个方面:
(1)分析不平衡数据集对传统分类器特别是神经网络泛化能力的影响。传统的下采样方法不能有效地选择具有代表性的大类样本,从而使一些重要的信息丢失。本文从数据集层面给出了一种面向不平衡数据集的主动下采样方法,该方法可以自动有效的去除远离边界的大类样本,而且能够保持数据集整体的分布特性,从而改善整个训练数据集的不平衡度,使之更适合传统的分类学习算法。以BF算法为准分类器的实验证明,与其他采样算法相比,该方法能够有效地提高小类的识别率,同时兼顾大类的准确率。
(2)数据清理技术经常用以解决由釆样方法而引入的类之间样本的重叠问题,但现有的数据清理方法虽然能够减少类之间样本的重叠问题对分类器的影响,但也导致误删除了一些不在重叠区域的样本,并且一些边界噪声由于现有数据清理方法过于苟刻的规则而没有被删除。本文借鉴离群点检测算法的思想,提出边界噪声因子(的概念,以此来表示样本成为边界噪声的程度,继而给出基于的数据清理算法,结合采样方法来解决不平衡和类之间样本的重叠问题。通过和传统采样方法、数据清理方法的实验比较证明该方法的有效性。
(3)分析了基因表达数据的特点,将面向不平衡数据集的智能极限学习机和剪枝加权极限学习机应用于基因表达数据的分析中,通过对急性白血病数据集、结肠癌数据集、小圆蓝细胞肿瘤数据集和蛋白质数据集的分类分析,验证了这些方法的有效性。
第2章面向不平衡数据集的主动下采样算法设计与实现
2.1引言
机器学习研宄的实质就是如何使算法能够根据已经学习过的事物进行分析总结,以便对未知的事物进行判断。对于有监督学习来说,其中很重要的一个步骤就是选择合适的训练数据集,在训练数据集上训练学习算法,使其掌握规律以便对未知的样本进行预测或者分类。传统的分类算法通常假设训练数据集中的各类样本之间的分布是均衡的,因此设计的算法在平衡数据集上的性能是非常好的。但是,事实上数据集并不总是均衡的,在现实中得到的数据总是因为一些其他因素而导致在数量和分布上不均衡,不平衡的训练数据集影响了传统分类器的性能。
针对两类问题来说,正如第章指出的,不平衡数据的涵义包括两个方面:(1)数量的不平衡:一类拥有的样本数量非常多,称之为多数类或者大类;另一类所拥有的样本数相对比较少,称之为少数类或者小类;(2)分布的不平衡:两类拥有相同的样本数,其中一类拥有的样本空间分布集中,称之为大类;而另一类的样本空间分布相对比较分散,称之为小类。由于传统的分类器是以整体准确率为准则来进行分类的,在各类样本分布均匀的数据集上效果很好,但是在处理不平衡数据集时,仍然使用整体准确率作为评价指标的话,就使得分类器为了达到高的整体准确率,被大类的识别率所影响,分类性能大大下降,一些属于小类的样本数据被错分为大类。
近年来,在不平衡学习问题上涌现了大量的研宄,并给出了很多解决方法;这些方法概括起来,可以分为三类:(1)改进训练数据集的不平衡分布,例如:上采样方法、下釆样方法、混合采样等;(2)改进经典算法:对当前比较成熟的分类器算法,采用优化参数、对各类样本赋不同的错分代价、设计面向不平衡数据集的新算法等;(3)改进评价体系。本章提出一种新的主动下采样算法来改善训练数据集类样本之间的不平衡,实验证明该算法有利于提高小类的识别率,同时也保持了较高的整体识别率。第4、5章则是从算法层面来解决类不平衡问题。
2.2不平衡数据集对分类器性能的影响


第3章基于离群点检测技术的类样本重叠数据集分类方法.........28
3.1引言.......28
3.2离群点检测技术.....28
第4章极限学习机优化方法..........42
4.1引言.......42
第5章面向不平衡数据集的智能极限学习机和剪枝加权极限学习机.........70
第6章不平衡数据分类算法在基因表达数据处理中的应用
6.1引言
生物信息学是由计算机、数学、生物等多门学科融合而产生的一门交叉学科,主要是利用计算机、数学等多门学科中的技术来解决生物学领域内的相关问题。这一概念自提出以来,生物信息学领域内的技术迅猛发展,并且在基因组数据的研究方面得到了广泛的应用。基因芯片(又称DNA微阵列)是基于杂交测序原理,釆用基因芯片技术可以获取海量的基因信息,跟踪监测成千上万乃至上亿的基因在不同组织、不同状态下的表达,利用基因芯片技术对样本检测而得到的数据就是基因表达数据。这些基因表达数据包含了样本中所有可测基因的表达水平,对这些数据进行分析研究可以了解基因之间的调控信息、影响基因活动的生理阶段等,据此来检测甚至预防疾病,例如,肿瘤就是正常的细胞组织因为在外界致癌物的影响下,基因在结构上(主要指碱基对排列顺序或者组成)发生了改变,因此基因原有的正常分布(包括基因的种类、各类基因的表达水平)也改变了;如果对肿瘤基因表达数据进行分析研究就可以更好的理解肿瘤发生的机理,识别治疗肿瘤的药物标,精准的诊断并掌控治疗的最佳时机,另外对临床治疗也提供了重要的信息。因此,对基因表达数据的挖掘、分析和处理是十分有意义的。
第7章结束语
7.1论文总结
本文主要研究基于神经网络的不平衡数据分类技术,整个研宄工作围绕不平衡分类领域,从数据集和算法两个层面分别给出了改进方法,用以改善不平衡数据对神经网络性能的影响。主要的研究工作总结如下:
(1)针对不平衡数据对传统分类器,特别是神经网络的影响,从改善不平衡数据集本身出发,提出了一个面向不平衡数据集主动下采样算法。首先分析了不平衡数据对传统分类器的影响,由于传统的分类器算法的设计是以均衡数据集为前提,以整体准确率为评价标准,因此直接应用于不平衡数据集时,常常为了获取高的整体准确率,而忽略小类样本的识别率;针对这一情况,从改善不平衡数据集不平衡状况本身出发,提出了一个主动下采样算法,该算法能够自动剔除远离边界的大类样本,同时保持数据集整体的数据分布,从而使数据集整体的不平衡状况得以改善,更适合于传统的分类器。实验证明,提出的算法与其他下采样方法相比,能够有效的提高小类的识别率,同时兼顾大类的准确度。
(2)将离群点检测方法引入到采样方法中,给出边界噪声因子的概念,并提出基于边界噪声因子的数据清理算法,用以解决不平衡和类之间样本重叠问题。分析了现有的和采样方法结合的数据清理技术存在的弊病:误删不在重叠区域的样本,而边界的噪声数据却因为其严格的规则没有删除;实验表明,提出的算法整体性能优于其他数据清理方法。
(3)将基于量子行为的粒子群优化算法引入到极限学习机算法中,用以优化极限学习机的网络结构,提出了量子行为粒子群优化极限学习机算法。极限学习机算法随机选择输入权值和隐层偏置,虽然比传统基于参数调整的神经网络算法节省了很多时间,但导致产生一些不必要的输入权值和隐层偏置存在,这就使得极限学习机算法需要更多的隐节点,因此,提出采用量子行为粒子群优化算法来优化输入权值和隐层偏置以减少极限学习机的隐节点;实验证明,量子行为粒子群优化极限学习机算法比其他基于智能优化算法的极限学习机方法在整体性能上更优。
参考文献(略)
计算机应用论文2018年精选范文四:非均衡数据分类算法若干应用研究
第1章 绪论
1.1 引言
随着计算机硬件技术和数据库技术的快速发展,各行各业积累了大量的数据,这些数据推动了工业自动化、互联网、物联网以及生物医学等新兴技术的快速发展。近年来,随着人类对海量数据研究的不断深入,对海量数据的处理逐步从原始的数据统计分析过渡到海量数据的知识发现,使得采用人工智能算法处理海量数据、进行数据分析,提取有用信息和发现新知识成为可能。知识发现一般被定义为从大量数据中提取可信的、新颖的、潜在的、有用的并能被人理解的知识的非平凡过程,其核心内容为数据挖掘。基于数据挖掘提取的知识一般可表示为概念、规则、模式和约束等。因此,从大量的有用信息中获取有价值的和重要的知识,并利用这些知识成为信息科学研究的重要课题。数据挖掘技术作为数据库技术和机器学习的交叉学科,就是从大量的、有噪声的、随机的、模糊的和不完全的数据中,利用先进的人工智能算法,提取隐含的、事先未知的,但又潜在的有用的信息和知识的过程,近年来已得到社会和学术界的高度重视。如在 2005 年的国际人工智能会议(IJCAI’05)收录的文章中有近一半是与数据挖掘的研究相关。数据挖掘技术被广泛应用于工业自动化、经济和医学等诸多领域,已取得了很多成功的应用。
随着新技术的不断涌现和数据挖掘理论研究的深入,分类器设计成为数据挖掘领域研究的一个热点问题。在数据挖掘中,分类器设计属于预测分析范畴,它的基本功能为用训练集进行分类器模型学习,用测试集评估分类器模型的性能。在有监督学习过程中,通过在已知训练上采用分类算法进行学习,构造分类预测模型函数,再用测试集验证所得决策函数的准确率。其中比较有经典的分类模型主要有朴素贝叶斯分类算法、人工神经元网络(Artificial Neural Networks,ANN)分类算法、kNN 分类算法和支持向量机分类算法等。人们对分类器的研究通常集中在海量高维数据分类、多类别数据分类和非均衡数据分类等多个方面。大量的实验研究表明,很难找到一种分类模型能适合所有的数据集并使分类器性能达到最优。因此,在分类器设计中,通常不同的数据集需要采用不同的分类模型来实现最优。
1.2 非均衡数据分类问题研究内容及现状
自20世纪60年代后期,研究人员开始对非均衡数据分类问题进行研究,非均衡数据分类问题越来越受到机器学习领域的重视,成为机器学习界的热点研究课题之一。在传统的机器学习研究中,大多数分类算法通常都假设训练样本中每类样本的先验概率分布均衡或误分类代价相等,而在现实世界中,这种假设并不一定成立,面对非均衡数据时,由于少数类样本信息被大量的多数样本所淹没,导致前者分类错误率远远大于后者,而且分类器泛化能力较差。因此,非均衡数据分类问题是数据挖掘和机器学习领域面临的主要难题之一。同时,由于医疗诊断、信用卡欺诈和入侵检测、市场商业行为分析、文本分类和检索和环境监测等某些领域,虽然少数类样本非常稀少,但是少数类的准确识别价值往往要高于多数类,人们往往更关注少数类样本分类的正确性。因此,对非均衡数据分类问题的研究具有重要意义。非均衡数据分类的性能评估标准不再由分类器总识别率来决定,人们更关注少数类的分类精度。近年来,随着非均衡数据问题研究的不断深入,基于非均衡数据分类算法吸引了大量的研究者。世界各地举办了以非均衡数据分类为主题的国际会议,会议涉及病情监测、生物信息、医疗诊断监测和无线传感器网络入侵检测等诸多基于非均衡数据分类问题,而提高非均衡数据分类器整体性能的方法主要有数据重构层面的重采样技术和算法层面的经典分类算法改进和提出新算法。
1.2.1 重采样技术
重采样技术就是对训练样本集中多数类样本采用欠采样方法,对训练样本集中少数类样本采用过采样方法,从而达到提高训练样本类分布均衡程度的目的,是当前提高非均衡数据分类器性能的一种有效途径。数据重采样技术主要有欠采样(Under-sampling)和过采样(Over-sampling)两种方法。欠采样技术主要包括随机欠采样多数类方法、近邻清理方法(Neighborhood Cleaning Rule,NCR)、压缩最近邻(Condensed Nearest Neighbor rule,CNN)方法、单边选择(One-Sided Selection,OSS)方法和Tomek links方法等,其主要目的是移除训练集中的多数类样本,此过程中存在可能将其中潜在的、有用的多数类样本移除,导致分类器性能降低现象。
第2章 相关技术
传统机器学习算法在对数据进行分类时,通常采用总识率作为分类器的性能评估标准,导致预测结果偏向于多数类,而少数类样本则往往被忽略或视为噪声。然而,在实际生活中,少数类样本往往是人们非常关注的对象。但少数类样本自身的特点就是少数类样本数据十分匮乏,只从少数类样本自身出发,则很难总结出存在的规律。因此本章分别从非均衡数据重构、集成学习和对经典分类算法进行改进几个方法出发,对非均衡数据分类问题进行研究。这里对非均衡数据分类问题用到的相关分类算法、非均衡数据处理方法和分类器性能评估方法等相关技术进行简单介绍。
2.1 误差反向传播神经网络算法
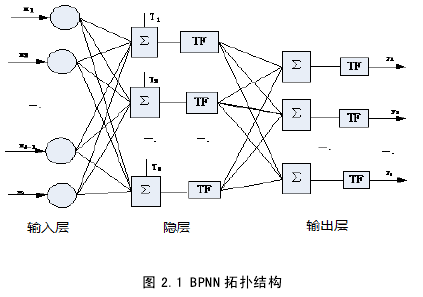
误差反向传播神经网络是人工神经网络的重要模型之一,是由Rumelhart D E等[58]在1986年提出的。该算法不仅具有良好的并行分布处理、非线性映射、泛化和容错能力强等优点,而且具有自学习、自组织、自适应等性能。目前,BPNN算法已广泛用于环境工程和工业自动化等诸多领域。该算法的网络拓扑结构主要包括输入层、隐含层和输出层,如图2.1所示。网络训练学习过程主要包括信号由输入层到输出层的正向传播和误差由输出层向输入层的反向传播两阶段。一个基本的BPNN模型主要由一组代表神经元连接强度的权值、用于求取各输入信息的加权和的累加器和非线性传输函数三部分组成。在网络学习训练过程中,若输出层的实际输出与期望输出未达到预先给定的精度,则转入误差的反向传播阶段,进而修正各层之间的连接权值,最后找到一组使期望误差函数最小的连接权矩阵。BPNN算法是目前神经网络中应用最广的一种网络,已经成功地解决了许多领域的实际问题。
2.2 基于最小分类错误率贝叶斯决策
Bayesian 统计分析源于英国学者 Bayes T R 在1973年的一篇文章提到的贝叶斯公式和推理方法。在数据挖掘中,主要采用朴素贝叶斯方法和Bayesian网络。其中朴素贝叶斯方法主要用贝叶斯公式进行预测。而 Bayesian 网络则是描述数据变量之间关系的图形模型,是一个带有概率注释的有向无环图。Domingos P等通过研究发现,朴素贝叶斯算法变量之间存在强相关的情形下也能取得较好的分类效果。具有算法简单、高效和适应性强等优点。朴素贝叶斯决策主要包括基于最小分类错误率贝叶斯决策和基于最小风险贝叶斯决策。
在基于最小错误率的贝叶斯决策中,假设朴素贝叶斯算法中各属性之间相互独立和连续属性的类条件概率服从高斯分布,在先验概率和类条件概率密度已知的情况下,通过贝叶斯公式比较样本属于各类别的后验概率大小。在保证总错误率最小的情况下,测试样本中任一个未知模式所属的类别决策为后验概率最大对应的类别。本文所利用基于最小错误率的贝叶斯决策算法可简单描述为:样本集合 D 的定义如公式(2.1)所示,设测试集中任一个未知模式为 x,设 N 为训练样本总数,设Ni是训练样本中属于 ωi类的样本数,则有各类别的先验概率p(ωi)≈ Ni/N,(i=1,2,…c)。假设类条件概率 p(x/ωi)服从高斯分布,则在 d 维特征空间中,多变量高斯概率密度函数定义如式(2.2)所示:
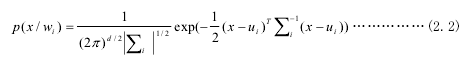
第3 章非均衡数据重采样集成学习模型研究...........25
3.1 模型框架 .................. 25
3.2 非均衡数据重采样集成学习模型........ 26
第4 章特征提取集成学习模型及在废水监测状态诊断上的应用.....45
第5 章 BSV‐BP算法及其在废水处理活性污泥质量分类上的应用...59
5.1 应用背景 ............ 59
第6章进化支持向量机模型及在流域水质评估中的应用
6.1 应用背景
随着世界人口的不断增长和经济的飞速发展,导致人均占有水资源量不断减少,人类活动和工农业生产导致水资源污染十分严重,工业废水和生活废水的排放量与日俱增,对受纳水体的环境质量造成严重威胁。国家环保部在2011年度《中国环境状况公报》中指出,我国地表水污染情况依然较重,松花江、淮河、海河、辽河、长江、黄河、珠江、浙闽片河流、西南诸河和内陆诸河十大水系的469个国控监测断面中Ⅳ~Ⅴ类占25.3%,超Ⅴ类占13.7%,地表水资源污染十分严重,人类的水资源安全面临着极大的危机。其中,黄河水系Ⅰ~Ⅲ类、Ⅳ~Ⅴ类和劣Ⅴ类水质的断面比例分别为36.4%、34.1%和 29.5%,属中度污染,支流污染较重。松花江水系Ⅰ~Ⅲ类、Ⅳ~Ⅴ类和劣Ⅴ类水质的断面比例分别为21.9%、53.7%和 24.4%,属中度污染。
水质评估是以水质指标的浓度值对水资源的综合影响为基础,按照一定的评价标准对水资源水质进行评估,准确反映水域水质状况和水体污染情况,达到提前预测预警水质状况的目的。传统的水质评估方法主要有单因子评价法、加权均值指数法和内梅罗污染指数分析法等。由于这些方法在水质评估中存在很多缺陷,往往导致评估结果与实际水质状况差距较大,因此很难满足水质评估的实际要求。如单因子指数法只能反映各个水质参数的污染程度,不能反映水资源整体污染状况,评估精度极低。加权均值指数法克服了参数个数对水质评估的影响,但权值的确定存在合理差和主观性等缺点。内梅罗指数法只考虑单因子污染指数的平均值和最高值,过分强调最大浓度污染因子对水资源的影响,忽视了某些浓度小而危害大的污染因子,对水资源水质评价灵敏性不够高,难以区分水资源污染程度的差别。
第7章 总结和展望
7.1 本文工作总结
本文通过参阅大量前人留下的优秀文献,详细介绍了数据挖掘技术的产生和发展,以及数据挖掘技术在非均衡数据分类问题上的应用,并在此基础上,提出基于非均衡分类问题研究的现状及研究意义。概述了类分布不均衡数据的定义、相关分类技术和分类器评估方法。文中针对UCI 非均衡数据集重采样集成学习模型的理论和非均衡数据分类算法在污水处理过程各处理单元监测状态诊断、废水处理活性污泥质量分类和水资源水质评估的实际应用,做了一系列有意义的尝试性和探索性的研究,并采用多种度量方法对分类器进行评估。本文围绕非均衡数据分类问题,做了以下工作:
(1)文中利用UCI 非均衡数据集,提出采用重采样技术对非均衡数据进行重构和对基分类器进行集成这一方法,有效地提高分类器的整体性能。通过对多组两分类UCI 数据集少数类和多数类重采样规模进行研究,得出重采样规模由最小类样本个数和最大类样本数的比值确定。通过采用F-measure 和G-mean方法对多组UCI 数据集分类算法进行评估,得出分类器性能度量参数F-measure 最大值与最小类样本数和属性数的比值之间的关系符合Logistic 曲线。为解决非均数据重构中少数类和多数类重采样规模盲目设定这一难题提供了一条新途径。
(2)文中利用污水处理过程各处理单元水质参数数据,开发基于 PCA预处理方法的选择集成学习模型。首先利用因子分析与旋转对污水处理过程各单元工业参数进行了定量分析,得出污水处理过程多传感器融合系统中不同信息源之间的关系,揭示了能够表征污水处理过程水质变化的本质属性。在因子分析的基础上采用选择集成学习模型对污水处理各单元监测状态进行诊断,较好地解决了故障类型与各监测参数之间的对应关系,达到动态预测污水处理过程故障类型的目的,为污水处理各单元的监测状态诊断提供了一个新方法。
参考文献(略)
计算机应用论文2018年精选范文五:基于元启发优化极限学习机的分类算法及其应用研究
第 1 章 绪论
1.1 研究背景和意义
分类研究一直是模式识别、机器学习和数据挖掘领域中最重要的研究问题之一,在学术界和技术应用领域都能涉及到,在现实生活中许多重要决策问题如疾病诊断和风险评估等都可归结为分类问题,这些复杂的问题对分类理论和算法提出了很高的要求。其中基于人工神经网络的分类理论与研究一直是人工智能和机器学习领域中最活跃的研究课题之一。人工神经网络不需要先验知识,能通过已知数据样本训练数学模型,对任意线性和非线性数据结构进行预测,具有良好的泛化能力,在研究领域和现实生活中有着非常广泛的应用。然而,传统的神经网络方法也存在很多缺陷,如训练时间过长、计算开销大、对初始参数设置敏感、易陷入局部极值、收敛速度慢甚至不能收敛、过拟合问题等。近年来,基于单隐层前馈神经网络的极限学习机方法有效地解决了传统梯度下降优化方法的不足,在处理分类问题上表现出更优越的性能,逐渐成为人工智能和数据挖掘领域的热门课题。同时我们也能看到,虽然研究人员提出了很多基于极限学习机的分类算法和模型,但尚未形成统一完善的理论体系,而且,同国外基于极限学习机的研究相比,国内的研究相对较晚,理论研究和应用技术还值得进一步的提高。因此,值得对基于极限学习机的理论、算法和应用展开深入研究。
元启发算法是利用不同启发式算法搜索空间的高级策略,它可看作是一个迭代产生的过程,结合不同的概念指导下属启发式算法探索和开发搜索空间。为了更有效地实现寻优,算法利用良好的学习策略来构建搜索信息。元启发算法是一个概率决策过程,它与随机搜索的不同之处在于它并不是完全随机搜索,而是以一种智能的方式进行随机搜索。同时它也可看作是一个算法框架,该框架通过调节变动以求解不同的优化问题。此外,元启发算法还具有多样化搜索和集中搜索的平衡机制。由于这类方法简单易实现、鲁棒性强、适于并行、能处理NP 问题等,被广泛用于模式识别、智能控制和工程优化等实际复杂问题。元启发算法包括多种类型的智能算法,如粒子群算法(Particle Swarm Optimization, PSO)、差分进化算法(Differential Evolution, DE)、人工蜂群算法(Artificial Bee Colony, ABC)等,这些群智能算法通过观察生物群体,模拟群体之间的协作方式来求解问题;而引力搜索算法是对物理学中万有引力和质量之间相互作用进行模拟的优化搜索策略,等等。这些算法在分类方法优化方面常常能起到良好的效果。
1.2 神经网络分类方法的研究现状及评述
早期的分类方法是统计分类,其表达形式是建立在公式基础上的,主要基于概率统计模型获得不同类别的特征分布以达到分类的目的。利用已知类别的数据样本进行训练构建分类模型,若分类方法设计的合理,那么它对未知数据处理的效果就会非常好。但前提条件是需要知道数据样本的分布情况,然而在实际中这个条件往往难以得到满足。与统计模型不同,神经网络是与数据样本分布无关的模型,它通过适当地调节网络结构中的权重参数以达到预期的结果,并且能通过调整参数值使结果逼近任意目标函数。基于人工神经网络的分类模型和算法在近几十年中得到了广泛的研究,算法流程主要包括:数据样本采集、特征提取/特征选择、构建神经网络结构和模型、分类器的学习及分类预测。一个性能优越的神经网络分类模型不仅要得到更紧凑的网络结构,还要尽可能涵盖更多的信息,取得较高的分类结果。在分类方法设计过程中,最重要的工作就是要针对具体的分类问题,找到一组最具分辨力且与分类结果密切相关的特征信息集合,构建结构紧凑的网络模型。在实际应用中主要有两种方法:一种是从领域专家那里直接获得专业领域知识;另一种是采用机器学习方法,从已知的数据样本中获取先验知识来指导神经网络分类模型的构建。由于前一种方法易受人的主观性和经验影响,因此,研究者大多采用后一种方法设计神经网络分类模型以解决分类问题。
随着人工智能和机器学习理论和技术的发展,研究者提出了多种人工神经网络方法来解决分类问题,主要以径向基神经网络(Radial Basis Function Neural Networks, RBFNN) 、 多 层 感 知 器 网 络 (Multi-layer Perceptions, MLP) 、自 组 织 映 射 网 络(Self-Orgnisations Map Netwoks, SOM)、小波神经网络(Wavelet Neural Networks, WNN)及其它多种神经网络分类方法等。下面按具体方法进行展开阐述。
第 2 章 相关知识介绍
2.1 人工神经网络概述
2.1.1 人工神经网络的定义
关于人工神经网络,尚未有一个标准和统一的定义,其中引用较广泛的定义是由神经网络学家 T.Kohonen 提出的:人工神经网络就是简单单元(通常为适应型)组成的广泛并行互连的网络,它的组织能够模拟生物神经系统与真实世界物体所作出的交互反映。概括地说,人工神经网络是一种旨在模拟人脑结构及其功能的信息处理系统。人工神经网络的研究和应用已经取得了良好的效果,研究者根据不同领域的具体问题提出各种各样的神经网络模型,并用于模式识别、计算机视觉和自然语言处理等多个方向,取得了巨大的进展。
2.1.2 神经元的结构
人工神经网络是由大量的神经元相互连接构成的网络,它是在现代神经科学研究成果基础上提出的,反映了人脑功能的基本特征。然而它并不是人脑的真实描写,只是在一定程度上的抽象和模拟。神经元是脑组织的基本单元,大约有 140 亿个,其结构和功能大致相同。图 2.1 为神经元结构图,包括四个组成部分:本体、树突、轴突和突触。其中本体就是细胞体,能够处理输入信息,相当于 CPU;树突是本体延伸出的多根分支;轴突是本体延伸出最长的分支,信号就是通过神经末梢传给其它神经元的,相当于本体输出端;突触是轴突与树突之间的结构,也就是神经末梢与树突相接触的交界面。在大脑神经网络中,每个神经元通过突触与其它神经元相连,一个神经元所发出的信号对不同接收神经元产生不同的效果,这是由突触决定的。突触连接越紧密,信号越强,反之信号越弱。突触的连接程度可由网络的训练改变。
通过对人类大脑神经网络的研究,它的基本特征可概述为:
(a) 由大量神经元以及神经元之间的连接组成;
(b) 神经元之间的连接程度决定传递信号的强弱;
(c) 神经元之间的连接程度可以通过网络的训练而改变;
(d) 信号可以起到抑制作用,也可以起到激发作用;
(e) 一个神经元收到的信号所累积的状态决定该神经元的状态;
(f) 每个神经元都具有一个“阈值”,这个阈值决定该细胞体是否能被激发。
2.2 前馈型神经网络模型
前馈神经网络是最常用的神经网络模型,通常包括一个输入层、若干隐藏层和一个输出层。其中隐藏层为单层,称为单隐层前馈神经网络;若隐藏层为多层,则称为多层前馈神经网络。神经网络输入和输出的激活函数通常为线性函数,而在隐藏层中的激活函数为非线性函数。其中对于训练多层前馈神经网络来说,影响最广泛的是 1988 年Rumelhart 和 Hinton 等提出的用于前馈神经网络学习训练的误差反向传播算法(BP 算法),为多层前馈神经网络的研究奠定了基础,而且多层前馈神经网络能够逼近任意的非线性函数,还具有良好的泛化能力,在科技领域中有着十分广泛的应用。
BP 方法是建立在梯度下降算法基础上的神经网络优化方法,采用误差反向传播算法来对网络中的参数进行调整,适用于多层神经网络的学习训练。算法的训练过程大体分为两步骤:第一步,从输入层输入信息,依次经过隐藏层的逐层处理并计算每个神经元节点的实际输出值;第二步,当输出层所取得的输出结果未达到预期值时,逐层递归地计算实际结果值和期望值之间的误差大小,根据此误差来迭代调节层与层之间的连接权重值,当输出结果到达预期值时,算法停止运行。确定神经网络的结构包括:明确输入层的节点数,隐藏层层数,各隐藏层中所需的节点数,隐层偏倚值、输出层的节点数以及隐藏层采用的激活函数类型(acvitive function)。
其中输入层类似树突,主要负责数据的输入,图中x 为 BP 网络的输入值,中间层主要负责数据的处理并将转换的结果传递到输出层神经元,y 是 BP 网络的预测值,各神经元之间由边连接,其值的大小用连接权重值来衡量。
第3 章 基于人工蜂群算法的极限学习机优化分类模型 ................. 29
3.1 基于原始人工蜂群算法的极限学习机优化分类模型 ........ 29
3.1.1 人工蜂群算法............... 31
第4 章 集成特征提取和优化极限学习机的医疗诊断模型 ............. 67
4.1 基于极限学习机的甲状腺疾病混合诊断模型 ............. 68
第5 章 结合减聚类加权和核极限学习机的医疗诊断模型 ...................... 83
第 6 章 基于改进引力搜索算法优化极限学习机的分类模型
特征选择和参数优化二者对于 ELM 模型来说起着同等重要的作用,二者之间相辅相成,共同作用。特征选择通过从原始特征空间中选出与结果最相关且最具分辨力的特征子集,并去除冗余的和结果不相关的特征,防止过拟合问题,降低训练模型的计算复杂度;而合理的参数设置能极大程度地提高 ELM 模型的分类性能,得到更优的分类结果。这两个因素在设计时兼顾考虑,同步优化,能最大化 ELM模型的泛化能力。目前,基于GS 法和基于梯度下降的方法是较为常用的两种参数优化方法,这两种方法存在的不足在之前章节中已进行了说明。
6.1 Hooke-Jeeves 模式搜索法
Hooke-Jeeves 模式搜索法是一类简单有效的直接搜索方法,由 Hooke 和 Jeeves 于1961 年提出,Torczon于 1997 年证明了它关于无约束最优问题的收敛性。 模式搜索法是对当前搜索点按固定模式和步长探测移动(exploratory moves),以寻求可行下降方向的直接搜索法。首先在某个参考点(当前解)附近,沿坐标轴方向逐一搜索,目的是探测函数下降方向,发现函数变化规律沿有利的方向,寻找更优的点。若找到改善点的函数值优于参考点的值,则将该改善点作为下一次迭代探测的参考点,并增加步长;若找到改善点的函数值低于参考点的值,说明探测失败,从参考点出发继续搜索,并减小步长。这样通过不断的搜索和模式移动,可以使得搜索逐步向最优值靠近。
第 7 章 总结与展望
7.1 论文内容总结
人工神经网络凭借其能对数据进行自动学习,并从复杂模式中提取知识作出智能决策的强大能力,为医疗诊断、生物信息和信贷评估等领域中决策问题的有效解决提供一条新的途径。然而随着分类问题复杂度的增加对学习算法的泛化能力提出了更高的要求,传统的分类方法和模型在一定程度上都存在着不足,对于不同的具体问题直接应用难以达到预期的效果。考虑如何设计具有良好分类性能和强泛化能力的分类模型,为理论研究和技术应用提供科学的帮助和支持,到目前仍未很好地解决。本文的研究工作是围绕 ELM 方法构建具有良好性能的分类模型,并用于解决医疗诊断和信贷风险评估领域中的分类决策问题。针对 ELM方法自身存在的不足以及在实际分类问题上表现不佳、泛化能力弱等深入探讨,提出了结合 ABC 算法和 ELM模型的优化分类方法、基于元启发框架的自适应多核 ELM 分类算法、结合 LFDA 特征提取方法和进化核 ELM 模型的甲状腺疾病诊断模型、基于优化减聚类加权算法和核 ELM 模型的帕金森疾病诊断模型以及基于改进 GSA 优化框架的核 ELM 模型分类算法。在知名 UCI 分类数据集上的一系列实验结果表明,本文提出的这些基于元启发优化框架的 ELM 分类模型都能获得良好的性能,达到了预期的效果和目的。本文的主要工作如下:
1.针对ELM的泛化性能受模型权重参数影响的问题,提出了一种基于 ABC 算法优化ELM 模型的分类方法 ABC-ELM。利用 ABC 算法优越的全局搜索能力优化 ELM 模型的网络输入权重参数和网络结构,并且在最大化分类精度的同时尽可能地最小化输出权重值范数,进一步提高了 ELM 模型的泛化能力。实验结果表明该优化算法不仅获得良好的泛化能力,分类性能优于已有方法,具有良好的稳定性,还得到了更紧凑的网络结构;核函数类型选择对核 ELM 模型影响很大,但传统方法在设计模型前需预先设定固定的核函数,在处理不同问题时具有较大局限性。针对上述问题,提出了一种基于自适应ABC 算法的多核 ELM优化方法SABC-MKELM。一方面,设计的多核函数能够根据数据分布进行合理地调整,另一方面,自适应 ABC算法能够更灵活地从策略池中选择更合适的解更新策略对多核 ELM 模型的重要参数进行优化。此外,在目标函数设计中综合考虑了分类平均精度和隐层节点个数两个重要因素。实验结果表明,该方法在 UCI数据库中十六个分类数据集上表现出良好的泛化能力,结果更稳定,而且分类性能明显优于已有方法。
参考文献(略)
计算机应用论文2018年精选范文六:计算机动画技术的研究与工程应用
第1章绪论
1.1研究的背景、意义和目的
1.1.1研究的背景
在使用计算机制作动画以前,所有的工作都需要动画工作人员手工完成,每秒钟格的画面要求,使得一部动画片画面数量大的惊人。而工作人员不得不一格一格的慢慢完成。
如今计算机技术在动画中的应用,大大缩短了动画的制作时间。计算机作为承载动画这门艺术的强大工具,就时间来说,还属新兴事物。
本人在职期间,从事动画专业教学工作。经过长期教学实践,日趋意识到计算机技术在动画制作应用中的重要性。
1.1.2研究的意义
计算机技术在动画制作上的应用日趋成熟的今日。不论是日本的二维动画,还是美国的三维动画都依靠其成熟的电脑制作技术吸引了全世界动画爱好者的眼球。2011年热映的美国动画《玩具总动员3》全球票房高达10.63亿美元,计算机动画带来的经济效益由此可见一斑。
1.1.3研究的目的
外国市场的冲击,自身条件的限制,使中国动画陷入了举步维艰的遞她境地。中国动画在世界市场中向来处于弱势地位,但其发展潜力仍不可小颇。只有从根本上将计算机动画技术研究透彻,将新的思维和技术在实践中加以应用,我国的民族动画才能得到振兴。
1.2国内外研究应用现状
发达国家计算机技术在动画领域的推广应用,将动画产业推到了一个薪新的阶段。尤其美国的这种数字技术已趋于成熟阶段。各种国际流行的制作二维、三维及合成的软件也是应有尽有,功能完备,而且兼容性极好,适于在各种平台运行。中国计算机动画技术技术紧跟国外发展且不乏自主创新,但由于缺少好的剧本与前期设计,只能以动画中期和后期加工的方式生存。
第2章动画概论
基于视觉暂留原理,当人的眼睛每秒连续观看24张连贯的静态图像时,这些图像之间将不会出现停顿而是像真的动起来一样。这种原理促成了动画的形成与传播。
2.1传统动画
以是否使用计算机制作为标准来衡量,从19世纪初到20世纪80年代末出品的动画,都可以归类于传统动画。这段时期的动画作品,不论是绘制于赛猫洛或纸张上的平面动画,还是相对立体的,用粘土捏制的定格动画,大部分是靠动画制作人员手工完成。其制作过程虽耗时耗力,但凭借动画工作者的创造力和毅力,出现了丰富多彩的动画片种。
2.1.1传统动画的起源
位于西班牙北部阿尔达米拉洞窟的壁画中出现了超过四只腿的牛,说明人类对于动态图像的想象与捕捉早在三万五千年前已经开始。
2.1.2传统动画类型
2.1.2.1笔绘动画
出现最早、种类最多的动画类型要数笔绘动画。像水彩动画、错笔动画、素描动画、炭笔动画、粉彩动画、水墨动画等都属于笔绘动画。生活中常见的铅笔、钢笔粉笔等都可以拿来制作笔绘动画。1906年,美国人詹姆斯斯图尔特布莱克顿制作的历史上第一部动画《滑稽脸的幽默像》,就是用粉笔绘制在黑板上创作出来的。
在笔绘动画中,最常见的是水彩动画。传统的迪士尼动画大多就是使用水彩颜料绘制而成。这种动画需要先用铅笔在画稿上画出设计稿,再将透明的赛挪塔覆在铅笔稿上描出线条,最后填上颜色。由于制作工艺相对简单,加上水彩颜料本身鲜艳明亮的特性,使得水彩动画成为传统动画中最为流行的片种。
粉彩动画也是观众较为喜爱的片种。用棒状彩粉笔绘制的画面具有细腻、柔和的手绘笔触,使得粉彩动画非常具有感染力。1987年,弗烈德瑞克贝克历时五年完成旳粉彩动画《植树的人》获奥斯卡最佳动画短片奖。一幅幅用彩粉笔和树脂描绘在毛胶片上描绘的精美图片,为本片感人的故事营造出梦幻的氛围。2006年,本片入选法国昂西国际动画电影节“动画的世纪一百部作品”,排名第五。
1961年,中国国宝级艺术——水墨动画诞生了。由伟特、钱家骏担任导演,取材自齐白石写意花鸟画的《小蝌蚪找妈妈》在国际上屡获大奖。水墨动画采用没有明确边缘线的画法,打破了笔绘动画先描线、后填色的制作技巧。年出品的水墨动画《山水情》成为唯部入选法国昂西国际动画电影节“动画的世纪一百部作品”的中国动画。
2.2计算机动画
20世纪后期,计算机动画在传统动画的基础上发展起来并广泛应用于动画制作、影视制作、游戏制作等诸多领域。运用计算机进行动画制作的系统包括硬件平台(计算机输入输出设备,如手绘板、图形工作站、显示器等。)和动画软件两部分。
本文将着重于计算机动画软件方面的解析,下面三个章节将分别介绍,计算机二维动画、计算机三维动画、计算机动画配套软件。
第3章计算机二维动画...........12
3.1计算机二维动画的制作........12
3.2计算机二维动画软件..........13
第4章计算机三维动画............18
4.1计算机三维动画的制作.........18
第5章计算机动画配套软件.........23
5.1图像处理软件.........23
第7章计算机三维动画工程应用实例
本章以计算机三维动画《星星历险记》(图7.1)的制作流程为例,详述国内动画公司计算机三维动画技术在实际动画项目中的应用。
《星星历险记》是一部国内原创的冒险励志类动画长片,目前已完成前三集的制作。主人公星进入的世界是魔法世界,有很多有趣的岛与:糖球岛、蘑攝岛、牙膏岛、鲜花岛、牛仔裤岛……他将与新认识的伙伴一起探险,在探险的过程中星星遇到了各种奇境,故事精彩,富有感人的童话色彩。
《星星历险记》动画项制作流程:

制作前期
剧本
第一集
(镜头紧随海踏后)海踏在空中自由的飞翔,(俯视镜头)海鸭向下俯冲,忡向城市一角。(镜头跟随)飞到星仔家的窗户那划过,(推镜头),透过窗户看到星仔机在书桌上睡觉,(遥镜头,交待桌子上有什么东西)桌子上,(特写)旁边摆有他爷爷的照片。
(推镜头,特写星仔嘴角)星仔嘴角流露出甜甜微笑,(跌化出梦中的场景)星仔和他爷爷一起以前生活的点滴(图片交代星仔生活的家园,还有爷爷的职业等)突然一切消失了,出现了个神仙老头告诉星仔,要找到爷爷,会有很多艰难险阻!不过会有帮助他的人。说完老头一思拂尘消失(加闪光特效)。
(切镜头,脸部特写)小星仔一着急,挣开双眼。(切镜头,全景)星仔在一个岛上坐起来採接眼睛,发现到了另一个世界(魔幻世界)的一个岛(糖果岛)上外滩,(脸部特写挣大眼睛)星仔惊奇的看着前方,(切镜头,全景)一个小魔女,小魔女向摆手星仔打招呼,(切镜头,中景〉星仔迷糊的看着小魔女疑惑的说:“你是……”。
此时礼炮声响起,(切镜头远景)不远处天空中的礼花,礼花接二连三,(切镜头,全景)小魔女站的星仔左恻,手指着天空说:“星仔看那好热闹啊,我们去看看吧。星仔坐着抬头望着他,星仔站起来,魔女朝那走去,星仔跟在后面走去。
(切镜头,仰视镜头背后,全景)星仔和魔女站在一个糖果岛大门口下。(推镜头大门的远景)里面传来欢声笑语还有音乐声,礼花声。(切镜头中精)小魔女回头对星仔说:“咱们去看看吧,也许他们能有你爷爷的消息星仔点点头,(切镜头,背后俯视镜头,全景)星仔和小魔女大步向门走去。
结论
—、传统动画与计算机动画的关系
计算机的应用在制作传统二维动画时,提供了力便与快捷。前文曾提到过的油画动画《老人与海》的导演亚历山大佩特洛夫曾表示:“我和加拿大国家电影局合作,替公司拍摄这部片子,对我而言,工作环境是前所未有的优渥。他们给了我一套最先进的动作控制动画摄影平台,用电脑软什有效执行复杂的格数拍摄工作以及视觉特效,也减少了很多现场失误所造成的缺点,科技其实也是可以帮忙艺术创作的。”
计算机二维动画省略了传统偶动画中手工制作模型的步骤,肓接运用计算机二维动画软件在电脑中创造动画角色、动画场景的模型,相当于在计算机中完成传统的定格动画。计算机动的应用给传统定格动画带来了方便与快捷,但同时也给传统定格动画造成了巨大的冲击。
作为英国著名动画公司阿德曼创始人之一的彼得罗德曾执导过《小鸡快跑》、《超级无敌掌门狗之魔兔的诅咒》等多部定格动画。在谈及定格动画是否会被电脑技术所取代时,他表示:“二十年前有些影像只能用定格动画的方式来制作,现在已经大不相同了。例如雷哈利豪森的影片,要创造逼貞的怪物与恐龙的唯一方法就是定格动画。例如《星球大战》第一集与第二集,要创造出在冰冻星球上走路的象形怪兽,唯一的方法就是定格动画。《未来战士》第一集里,角色从失事燃烧的卡车里走出来,也是定格动画做出来的。对当时而言,这都是唯一能创造出这些影像的方法。因此定格当时在电影工业里占有一席之地。残酷的是:现在这些都被电脑技术取代了,之前所举的例子都能用电脑技术来制作。”由此可见,电脑动画确实给传统定格动画造成了巨大的冲击。
计算机技术在定格动画的各个环节都提供了强有力的帮助,阿德曼指出:“在《超级无敌掌门狗之魔兔的诅咒》中我们有三十公分的塑料泥土做的兔子,也有电脑影片制作的兔子,这其中有很实际的考量。有一段影片是漂浮在三度空间中,用定格拍摄的话是很困难、很昂贵的细腻工作,而用电脑影像来制作的话则相对比较简单。有了数字后期,轻易就能把定格拍摄的角色从地面上举起来,使他们飞翔,而且做合成也很容易。前景与背景可以分别拍摄再合成,定格拍摄的部分与背景也可以合成,非常实用。十年前我们花了九牛二虎之力,经过很多困难才能拍出让观众感觉是飞的效果。而现在这些效果在数字绘图里算是一般常识,很容易做到。如今在我们的工作室,我们有时候也会觉得工作室的空间太小,做不出我们想要的大场景镜头,或一些更有气势的做法。以合成来说,这些想法就能较为轻易的实现了。我们在工作室的楼下做了同样的场景,我们也做了三到四倍大的复制场景,因为我们仍然想用摄影机拍摄一气呵成的全景。但如果我们能把前景和背景分幵拍摄再用计算机合成,那我们就不必建立那么多次及那么多种场景了,这可以省下大量的预算与空间,这是非常实用的方法。”
参考文献(略)
计算机应用论文2018年精选范文七:实时同步虚拟协同实验平台的设计与实现
第一章 绪 论
1.1 课题的背景与意义
在信息技术和计算机网络飞速发展的今天,远程教育获得了蓬勃的发展,远程教育是综合应用一定时期的技术开发和利用各种教育资源为学生提供教育服务的总称,其教育模式和教学方法日趋成熟,开设的学科越来越丰富,学科体系越来越完善。但是受时间、空间、成本等多方面的限制,如何在远程教育中高效地开展实验教学仍然是困扰教育管理者的一大难题,虚拟实验的出现,为解决这一难题提供了一种有效的解决方案。
计算机支持的协同工作的提出有效的解决了虚拟实验网络教学平台的搭建问题。计算机协同工作(Computer Supported Cooperative Work)是利用计算机和通信技术建立一个可以多人协同完成的工作环境,这一概念最早是由美国 MIT 的艾琳·格雷夫(Iren Grief)和DEC的保罗·卡什曼(Paul Cashman)于1984年在一个专题讨论会上首次提出的,当年他们提出这一概念是为了描述他们当时正在组织研究一个关于如何利用计算机技术支持交叉学科的研究人员可以共同工作的课题,他们利用通信技术和多媒体技术建立了一个可以协同工作的环境。在此环境下参与者可以相互合作,共同解决在一个研究领域、一个项目、一个产品或者求解学术上的同一个难题。
本课题组根据《计算机网络》教学需求,在本学院网络通信实验室的实验设备基础上,设计开发了远程网络教育实验公共服务平台。该课题采用B/S模式,学生只需通过浏览器,访问此网站,就可以不受时间和空间的限制进行虚拟的实验操作。但此课题现有的虚拟实验还存在着一定的不足,譬如只有单人实验,不能多人协同完成实验。本文将以单人虚拟组网实验平台为基础,进一步深入研究并开发了实时同步虚拟协同实验平台,目的在于可以使多名学生同步协作完成同一项实验。在此虚拟协同实验平台下,学生不仅能够操作基本的虚拟实验,巩固计算机网络知识,提高自身的实验动手能力,更能通过协同合作增强学生的合作意识、提高实验效率。
1.2 国内外研究现状
虽然提出虚拟实验的概念只有二十余年,但是由于它具有广阔的应用前景,各国均在该领域进行大力的研发并且己经取得了一些进展。对于虚拟协同实验系统,目前国内外还没有出现作为正式产品的同步协同虚拟实验室,但对虚拟实验室和CSCW两方面的研究都已开展得如火如荼。其中国外比较著名的有:
(1)1997年德克萨斯洲大学的PatriciaJ.Tene:先生设计了一个虚拟协同实验系统,其目的是为了能够获得协同实验环境中涉及的一些关于物理科学实验室所固有的科学方法,使用这样的实验室,使得学生必须进行协作实验,从而让学生可以在协作学习小组中加强彼此之间的信任。
(2)2007 年 Lianguan Shen 等在异步协同环境下工程设计教育中提出了通过多种角色的概念来区分不同的操作权限。不同的角色提供与该角色相对应的权限和义务。除此之外,文章中定义的操作实体不仅具有几何属性,比如尺寸、类型等,还包括协作属性,用于包含操作中生成的协作信息。
(3)2009年 Jara等在在线实时虚拟协同实验室中实现了一个可以多人异地轮流操作同步观看的实时协作虚拟实验室,文中使用加锁法对实验室进行并发控制,在教师演示的过程中学生是不能参与操作的,如果学生对实验过程存在疑问要首先经过老师同意才能操作实验,并且同一时刻只能有一个学生可以操作实验面板,所以该实验室不支持异地多人同时操作。
(4)2009年 Qin Jing;Choi,Kup 一Size等在基于集群混合网络架构的虚拟协同手术中提出了一个支持协作虚拟外科手术的完整框架。该框架主要是基于duster 混合网络体系结构完成的,在该框架中通过采用多路传输传送参与者的所有相关更新信息的方式来减少系统的网络延迟,由管理服务器维护系统的一致性。协作虚拟环境(CVES)的研究使得在外科手术中进行模拟协同工作成为可能,但由于在保持最快网络存取状态一致性上存在技术瓶颈,所以要实现一个高效能协作外科手术模拟仿真系统仍然是一项十分艰巨的任务。
第二章 相关实现技术
本章主要介绍了本实验平台所使用的开发平台、开发工具及实现语言,并通过对比和分析阐述了选择开发平台和实现语言的理由。除此之外本章还介绍了涉及到的关键性技术。最后,针对本文的研究内容给出了技术层面的定义。
2.1 .NET Framework
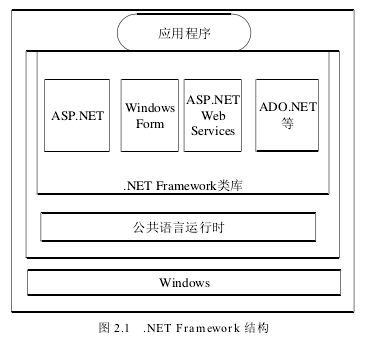
2.1.1 公共语言运行时(CLR)
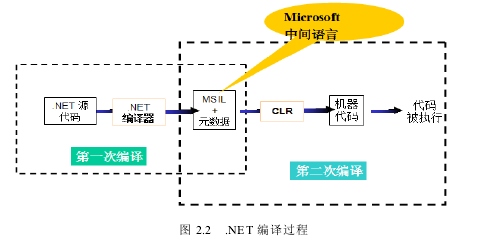
公共语言运行时(CLR)是.NET Framework 框架的基础,可以把运行时看作是一个在程序执行时负责管理代码的代理,它主要有线程管理、内存管理和远程处理等职责,除此之外它还强制实施严格的类型安全以及其他形式的可提高可靠性和安全性的代码准确性。实际上,代码管理是运行时的基本原则,通常我们把在CLR的控制下运行的代码称为托管代码。CLR执行编写好的源代码之前,需要编译它们,在.NET 中,编译分为两个阶段:
(1) 把源代码编译成中间语言(IL)。
(2) CLR把IL编译为平台专用的代码,两阶段如下图2.2所示。 这两阶段很重要,Microsoft 中间语言是提供.NET 的许多优点的关键。Microsoft中间语言与 java 字节代码共享一种概念:它们都是低级语言,语法简单,可以非常快速的转换为内部机器码。对于代码来说,这种精心设计的通用语法有平台无关性、提高性能和语言的互操作性的优点。
2.2 C#编程
2.2.1 C#语言概念及优势
C#是可用于创建要运行在.NET CLR 上的应用程序的语言之一,具有语法简洁、面向对象设计、与 web 紧密结合、完整的安全性和错误处理、版本控制、兼容性及灵活性的特点。它是从C 和C++演化而来的,是Microsoft 为使用.NET平台而量身打造的,它综合考虑了其他各种编程语言的优缺点,在保留各种编程语言的优点的同时尽量解决其他编程语言存在的问题。因为 C#语法比较简单,所以使用C#开发应用程序比使用 C++要简单一些,与此同时C#是一种十分强大的编程语言,用 C++可以完成的任务几乎全部可以通过 C#完成。虽然一般情况下执行相同的任务的时候,用 C#编写的代码量通常比 C++要大一些,但是 C#代码更健壮,调试起来也更简单,.NET 始终可以随时的跟踪数据类型。C#虽然只是用于.NET 开发的一种语言,但是它是最好的一种语言,它是唯一一个彻头彻尾为.NET Framework设计的编程语言,是可以移植到其他操作系统上的.NET版本中使用的主要语言,它能使用.NET Framework 代码库提供的每种功能。综上所述,本实验的开发选择使用C#编程语言来完成。
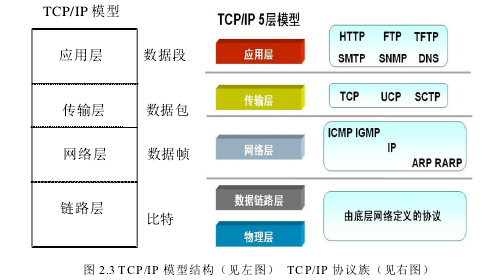
2.2.2 C#网络编程方法概述计算机网络的 TCP/IP 模型将计算机网络通信定义为一个四层框架模型,分别为链路层、网络层、传输层及应用层,从名字上看,TCP/IP 包括传输控制协议和网际协议,但实际上指的是 Internet 协议系列,常称为 TCP/IP 协议族,具体模型结构及各层所包含的主要协议如图 2.3 所示。.NET 框架也为网络开发提供了两个顶层命名空间:System.Net 和 System.web,C#通过命名空间中封装的类和方法实现网络通信编程、Web应用编程以及 Web Service编程,常使用的命名空间有:System.Net、System.Net.Sockets及System.Web,常使用的类有:IP地址类、DNS类及Socket 类。
第三章 实时同步虚拟协同实验的设计方案 .......................12
3.1 单人虚拟组网实验平台概述 ..............................12
3.2 虚拟协同实验平台的设计目标 .....................13
第四章 实时同步虚拟协同实验的实现 .................16
4.1 实时同步实验操作...............16
第五章 实时同步虚拟协同实验的运行 ..................41
5.1 实时同步实验操作的实例 ......................41
第五章 实时同步虚拟协同实验的运行
本章主要从设备配置的实时同步、实验拓扑的同步搭建、并发操作的控制等几个方面,对本文设计搭建的虚拟协同实验平台的主要功能进行了测试,并在测试的实例中给出了效果截图与详细说明。
5.1 实时同步实验操作的实例
本文假设学生kdf占用SW1(交换机1),学生sharpay占用SW2(交换机2),本文以在 sharpay 的实验平台查看 kdf 对 SW1 的配置来验证实验平台的实时同步功能,为了能够突显出平台的实时性,本文在查看和配置文本框上加上了时间显示器,并在同一台PC机上对比实验效果图。学生kdf配置SW1,此时学生sharpay右键双击自己平台SW1设备图标旁的“正在配置,点击查看代码”label,出现查看SW1配置情况的textbox,为了能够集中检测实时同步配置信息的功能,本文只给出关键部分的实验效果图,如图5.1所示。
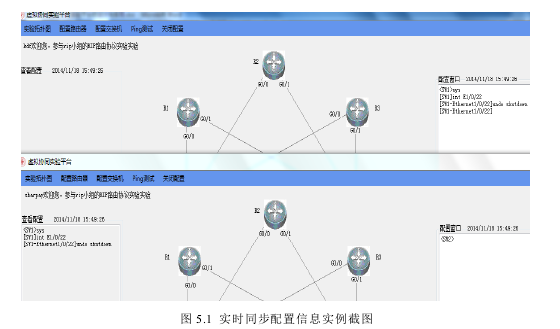
图 5.1 中有 kdf 与 sharpay 两个学生用户共同完成 rip 路由协议实验,kdf 配置窗口可以看到15:49:26这个时刻kdf对 SW1 的配置情况,此时sharpay的查看配置窗口中15:49:26时的配置信息与kdf相似,但是由于提示行的命令对于实验是没有操作意义的,所以 sharpay 查看配置与 kdf 配置窗口的命令行在同一时刻是相同的,这就证明本平台实现了实时同步设备配置信息的功能,本文第4章讲到本实验设备操作的实质是对实验设备的配置,所以本实例表明本实验可以实时同步实验操作。
第六章 总结与展望
6.1 工作总结
本文在单人虚拟组网实验平台基础组网实验的开发思想下,结合多人协作虚拟实验的项目需求及项目特点,设计并开发了实时同步虚拟协同实验平台。该平台不仅能够允许多人共同完成同一项组网实验,增强了学生之间的合作意识,还严格模拟真实的实验流程及实验操作,更好的帮助学生熟悉实验操作流程,全面地学习和掌握计算机网络知识。
本文对实时同步实验平台的需求进行分析和总结,提出了虚拟协同平台的设计目标,通过网络编程技术、C#编程语言、.NET 类库及 Sql Server 数据库等关键技术,搭建了一个可以满足同步搭建网络拓扑、实时同步实验操作及控制设备并发操作的虚拟协同实验平台。
经过运行实例证明,该虚拟协同实验平台基本满足多人协同完成同一项虚拟实验的需求,它的设计和开发,为本课题进一步实现智能化在线虚拟协同实验平台提供了重要理论依据和技术基础。
参考文献(略)
计算机应用论文2018年精选范文八:基于三维重建的计算机辅助骨科手术系统研究
第一章 绪论
1.1 选题背景及研究意义
骨科手术中通常涉及到复杂的几何结构的变化,并需要对骨骼的形态有足够的认识和了解。在传统的骨科手术中,医生通过在大脑中进行术前模拟来确定手术方案,再根据形成的三维印象进行手术,这是手术能够高效准确地进行所必须的准备工作。但要在大脑中清晰的想象出术中骨骼形态的几何和拓扑结构的复杂变化并非易事。这种手术方案质量的高低非常依赖于医生个体的外科临床经验与技能,且在大脑中形成的这种手术方案的构思信息不方便于手术小组成员之间的交流。
近年来,借助于计算机图形学等技术的医学体数据重构人体内部三维结构应用日益广泛,医学诊断与治疗的手段也在不断发展,如近年来出现的计算机辅助外科手术系统、虚拟外科手术系统等。通过这些技术,外科医生在手术中可以提高手术定位的精度,减少手术创伤,提高成功率。通过术前在计算机上演示手术的过程,可以方便医生、护士和患者之间的沟通,否则如果仅仅凭医生的描述,其他人往往较难彻底理解其手术意图和要点。除此之外,在医学教学上运用虚拟手术系统可以为缺少临床经验的学生、医生在真正手术操作前获取更多经验。
三维重建是计算机辅助骨科手术的前提和基础。医学图像三维可视化是科学可视化的一个重要领域,也是它的一个研究热点。医学图像可视化,是指人们通过 CT,MRI等数字成像技术,在计算机上进行三维效果表现,从而提供传统手段无法取得的结构信息。医学图像的三维可视化具有重要的研究和临床应用价值。
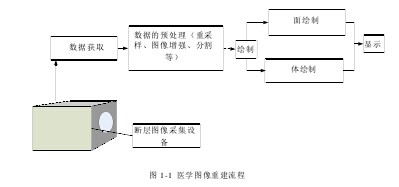
针对医学图像的三维重建虽然有多种方法,但处理步骤却基本相同,如图 1-1 所示。即,得到序列断层医学图像(CT、MRI、PET和 SPECT)后,将医学图像格式转换为便于计算机处理的格式,通过对图像数据进行如平滑噪声,消除伪影等预处理,再采用一定的插值算法,保证体数据的表达各向同性,然后采用图像分割算法,对体数据的不同组织器官进行感兴趣区域提取,剔除无关组织。在这些预处理步骤完成后,再根据系统的内存容量、计算能力和重建的目标和应用特点,选择合适的三维重建算法进行绘制。
基于这种三维重建技术,医生可以由CT图像获得解剖组织丰富的三维信息,从而对图像信息的利用更充分。计算机辅助手术系统最早用于颌面外科手术,现在已经扩展到骨科、整形科及神经外科等涉及骨骼等硬组织的辅助设计中。这种类型的系统仍然是未来的主要发展方向之一,在临床上也积累了丰富的案例及经验。
1.2 三维可视化技术的分类及国内外研究情况
目前医学体图像的三维重建可分为断层绘制、面绘制和体绘制3种不同的绘制方式。其中最简单的绘制方式是断层绘制,它将各断层图像以快速逐层显示、二维序列显示、或漫游等方式来提供灰度或伪彩色位图显示。这类方法绘制速度快,人机交互性好,在观察器官内部结构特性方面现在还常常被用到。面绘制(Surface Rendering)是由原始的三维医学体数据构造出大量的几何图元(一般是三角面片),由这些几何图元拟合成物体表面的三维结构,再根据光照、明暗模型等计算机图形学算法进行消隐和渲染得到显示图象。体绘制不需要构建几何模型,而是根据光照原理直接将三维效果显示在屏幕上。这两种可视化方法在医学影像可视化领域都得到了泛的应用,下面分别简单进行介绍。
第二章 二维医学图像预处理
2.1 引言
在骨组织模型三维重建之前,须先经过二维平面上的预处理。医学图像一般是以DICOM 格式存储的,计算机并不能直接显示这种格式的文件,因此要解析 DICOM 图像并转换格式。分割是三维重建的基础,分割可以将需要重建的部分提取出来,以便在三维重建前进行定性和定量的观察分析,令重建效果更精确。此外,为了增强重建效果,对图像的滤波也是必不可少的。本章主要介绍二维医学图像的获取及预处理,为下一步的三维重建做准备。
2.2 CT 图像和 MRI 图像的获取
医学图像中,计算机断层扫描(CT)和磁力共振成像(MRI)是最常见的两种用于获取解剖图像信息的技术。CT是用 X线束对人体某部位进行一定厚度的扫描,由探测器检测到透过该部位层面的 X 射线,将此可见光的信号转换成电信号,再用 A/D 转换器转换成数字信号,输入计算机处理后形成图像。这种技术成像快,在骨骼及软组织成像方面具有独特优势。人体组织处在较强的磁场和射频脉冲环境下组织内进动的氢核(H+)会发生章动,MRI就是利用了这一原理。MRI图像适合于软组织成像。相对而言,CT的空间分辨率高于MRI,而MRI图像的对比分辨率高于CT图像。 影像设备产生的数据存储格式不尽相同,常见格式有 DICOM、TIFF、BMP,现在医学图像领域较为通用的是基于 DICOM协议上的标准格式。
第三章 医学图像三维重建 .............16
3.1 引言 ........ 16
3.2 轮廓连接法三维重建 ........ 16
3.3 传统的移动立方体算法 ......... 17
3.4 MC 算法的二义性及消除........... 21
3.5 等值面的平滑 ...............23
3.6 实验结果及分析 ..............24
3.6.1 绘制结果 ........ 24
3.6.2 结果分析 ............. 26
3.7 本章小结 ........ 26
第四章 快速成型技术 ............. 27
4.1 引言 ................ 27
4.2 STL 文件的格式与规则.............. 27
4.2.1 STL 文件格式............ 27
4.2.2 STL 文件规则................ 28
4.3 快速成型文件的生成 ............ 29
4.3.1 快速成型文件生成方法 .... 29
4.3.2 STL 文件中三角片顶点顺序问题..........9
4.3.3 本方法生成 STL 文件的步骤及伪代码.......... 30
4.4 快速成型文件在手术设计中的应用 ............. 32
4.5 实验结果及分析 ............... 33
4.6 本章小结 ........ 34
第五章 医学图像三维模型的手术模拟操作 ........36
5.1 引言 ......... 36
5.2 三维点的拾取 .............36
5.2.1 射线拾取法获取三维点的思想 .......... 36
5.2.2 空间变换与向量射线的求取 ...............37
5.2.3 向量射线与三角形交点计算 ................39
第六章 计算机骨科手术辅助系统的实现
6.1 引言
在真实的外科手术中,外科医生和助手始终进行着两个重要的活动,一是对物体进行目测或借助工具对物体进行几何测量,如选择范围内某组织的尺寸,截骨的角度等;二是把物体放在准确的角度和位置。计算机辅助外科手术系统可以辅助外科医生在术前获得手术部位的准确的结构信息,进行严格的术前规划,这对提高手术的精确性意义重大。因此这种辅助系统的也越来越受到医生的青睐。
目前,有些机构已经开发出了计算机辅助手术系统的产品,其中在国内被广泛使用的是比利时 Materialise 公司开发的 mimics 软件,它具有人体测量分析,分割、切割、融合、定位等功能,能辅助手术设计,快速成型、假体/植入体设计,并能进行有限元分析及流体力学分析等。但这种软件价格昂贵,而且实际应用中某些医疗机构只需要其中一部分功能,如外科室只对计算机辅助骨科手术功能有需求。
本文正是基于这样的背景,研究开发这样的系统。在进行上文理论研究基础上,开发出计算机辅助骨科手术系统,本系统用 Visual Studio 2005 作为开发工具,并借助了OpenGL 图形函数库。本章主要介绍本系统的系统架构、功能模块以及实例分析等。
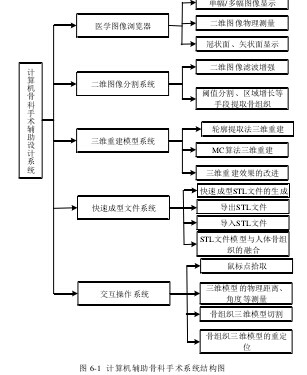
6.2 计算机骨科手术辅助设计系统框架
本系统的框架如图 6-1 所示。由于医学图像一般用 DICOM 格式存储,因此首先要对 DICOM 文件进行解码,转换成 BMP 格式后在计算机屏幕上显示。这里,三维重建所需的体数据是由CT序列图像提供的,因此系统要能读入多张图像,并按一定的顺序显示。为便于观察,本系统根据得到的体数据重构了冠状面及矢状面,提供了更丰富的观察角度。同时,在二维图像上可以进行包括距离、角度的物理测量。在三维重建前,需要对二维序列图进行滤波、分割等预处理,以得到更好的重建效果,有利于对感兴趣区域的观察。在三维重建方面,系统用MC 算法进行面绘制,并对算法进行了消除二义性、提高平滑度方面的改进。在交互操作中,用鼠标准确拾取空间点是其他操作的前提条件,其精确性对后续的三维模型测量、切割等有决定性的影响,而基于此的切割及重定位是计算机辅助骨科手术重要的环节。系统还实现了快速成型文件的生成及其导出功能,为辅助人工替代物的植入提供更完善的服务。
结论与展望
全文工作总结
医学图像三维重建技术是从一系列二维图像中重构三维结构信息,它能够为医生提供逼真的显示效果和定量定性分析的工具。三维重建也是计算机辅助骨科手术的前提,针对骨科手术的特点,本文用面绘制方法实现三维重建,在得到三维几何模型后对模型进行模拟手术操作。医学图像分割技术是三维重建的基础,它在医学影像处理与分析中具有重要的意义。
本文第一章对研究课题的背景及意义做了简单说明,并概述了三维重建技术及计算机辅助手术的发展现状;第二章介绍了二维医学图像的处理,重点探讨了图像的去噪滤波及感兴趣区域分割的方法及实现;第三章研究了面绘制技术中轮廓连接法及经典的MC 算法,通过在 windows 平台下用 VC++实现这两种算法,用实例对比说明 MC 算法的优点,同时针对 MC 算法存在的二义性、光滑性问题提出了解决的方法;第四章介绍了快速成型技术及其在计算机辅助骨科手术中的应用价值,针对目前采用的点扫描法不适用于医学序列图像生成STL文件,以及轮廓连接法的诸多缺点,本章提出了一种基于MC 算法生成 STL 文件的方法,并通过实例验证其可行性;第五章实现了在计算机上模拟骨科手术的操作。为了用只能获取二维信息的鼠标点击来获取三维模型的空间点坐标,本章提出了一种用拣选射线与三角形求交的方法,在此基础上实现了三维模型的测量及标注,并模拟现实中的骨科手术切割,实现了封闭区域模型切割及面切割,并对切割后的模型进行重定位,最后通过模拟脊椎矫正手术实例来说明本方法的效果;第六章介绍了基于 VC++及 OpenGL的计算机辅助骨科手术的系统的开发。完成的具体工作主要有如下几个方面:
(1) 三维面绘制轮廓连接法及 MC 算法的实现
简单介绍了轮廓连接法的实现步骤并通过编程实现,说明此方法的缺陷;然后再介绍了MC 算法的原理及其二义性的解决办法,并提出用一种三角片的法向量场平滑方法改进面绘制的显示效果。
(2) 基于 MC 算法的医学图像快速成型文件生成方法
对比了目前STL文件生成的点扫描法和轮廓连接法后,针对医学CT序列图像提出了一种基于MC 算法生成STL文件的方法,重点讨论了STL文件需遵循的三角形顶点顺序问题,并通过快速成型实体验证本方法的可行性。
(3) 计算机模拟骨科手术操作的实现
针对在电脑屏幕上用鼠标点击模型时无法获得深度信息的问题,本章提出了一种用拣选射线与三角形求交的方法来获得模型中感兴趣点的精确的三维空间世界坐标,在此基础上实现了三维模型的测量及标注。为模拟现实中的骨科手术切割,提出了一种通过计算切割平面与模型的三角面片位置关系,将模型沿切割平面分成两个子模型的方法,在此基础上实现了封闭区域模型切割及面切割,并对切割后的模型进行重定位。上述的拣选射线求空间点及平面切割模型,为了确定射线与三角形的相交点或者切割面与三角形的位置关系,都需要对所有三角面进行遍历,使得其交互速度过慢,为此本文提出一种网格划分包围盒的方法,迅速剔除大量无关三角形,避免其与射线或切割面的计算,从而显著提高了交互速度。最后通过模拟脊椎矫正手术实例来说明本方法的效果。
(4) 基于 VC++和 OpenGL 的计算机辅助骨科手术设计系统的开发
以 VC++和 OpenGL 为开发工具,设计并实现了一个将医学 DICOM 图像解析,显示,二维医学图像处理,冠状面、轴状面重构,三维重建,快速成型文件生成,骨科手术模拟操作等功能集为一体的计算机辅助骨科手术系统,其界面简单直观,易于操作,可以满足辅助骨科手术的基本要求,为以后的进一步研究打下了基础。
参考文献(略)
计算机应用论文2018年精选范文九:手持移动设备自然用户界面交互范式研究
第一章绪论
1.1研究背景及意义
人们与交互式系统进行交互,在用户看来是直接与其上的用户界面进行交互。自计算机的出现至今,其上的用户界面经历了三个阶段,分别为批处理界面、命令行界面和图形用户界面,其中每一种用户界面都在当时使用环境中统领着用户界面领域,而自PC时代以来,以WMP为基础范式的图形用户界面更是直到今天仍被广泛使用。但近些年来,以手机、PDA、智能手表等为代表的手持移动设备的出现及迅速广泛的应用,使得时代开始向移动时代转变由于交互上下文的不同,手持移动环境对用户界面的可用性提出了新的需求,导致以桌面办公为隐喻的范式已不再适用于移动交互环境,因此有必要提出新的移动交互范式来提高用户与手持移动设备交互的自然性、高效性。故本文的研究旨在通过分析移动可用性相关问题,继而提出一种移动交互范式来提高手持移动设备用户界面的可用性。
1.1.1手持移动环境下可用性需求
手持移动设备即是一种口袋大小的计算设备,通常配有一个小的显示屏幕,具有单个或多种输入输出方式,因为其可随时随地访问获得各种信息,所以以智能手机、PDA为代表的设备很快流行起来。然而随着手持移动设备在硬件及软件的迅速发展,用户在与其用户界面进行交互时,却没有体会到相应良好的交互体验。究其原因并不是因为其没有达到应用的功能性目标,而是由于在设计移动用户界面时仍简单的移植基于范式的图形用户界面,这虽然可以减少大部分用户的学习时间,但却忽略了移动环境与PC环境的不同所导致的可用性问题。
可用性是指特定用户在特定的环境中使用特定产品完成特定任务时,交互过程的有效性、交互效率和用户满意度。而在手持移动环境下,首先从特定用户角度来说,移动用户具有移动性和平民化趋势,即用户通常在移动环境下使用手持移动设备,并且使用者的年龄段更加广泛(包括老、中、青、幼),而用户平民化使得用户的认知水平也不再受严格限制;另外用户的移动性使得用户的注意力资源不能长时间集中在某一特定任务上。其次,从使用背景来看,手持移动环境较PC环境更具有复杂多变性,如在行进列车中使用PAD玩游戏、行人道上打电话等,因此用户在与手持移动设备交互过程中会受到各种不确定的移动干扰。再次,从特定目标来看,移动任务也不同于任务,这是由于手持移动设备自身特性(移动性、资源受限性等)和移动使用上下文(用户与设备移动性、周围环境等)决定的,在这种情况下,移动任务具有临时性、界面切换性,这与任务都有很大的不同。故在手持移动交互环境下,可用性已发生了巨大变化,从而使得针对手持移动设备用户界面的设计不能仅仅照搬PC用户界面的设计准则,同时用户界面可用性评估也需要随之改变。
1.2国内外研究现状分析
自手持移动设备出现至今,国内外就其上用户界面的研究一直没有停歇,其中包括可用性研究、交互范式、软件架构等等。本文主要对手持移动设备用户界面的可用性问题、交互范式两方面进行研究,下面就国内外对这两方面的研究现状进行描述。
(1)可用性
可用性通常要保证交互式产品易学、使用有效果、能给用户带来愉快的体。虽然手持移动环境下可用性问题日益突出,但可用性并不是新的研究课题。国内外也对移动可用性相关理论进行了大量研究:Scott Weiss等人分析了手持移动设备交互上下文特点,指出移动可用性在移动应用系统设计实现的各个环节的运用问题;Tomas等人则对现有手机平台进行了可用性测试,得出用户与移动手机交互过程中的心智模型;VirpiRoto等人在如何提高移动交互效率方面给出了建议,指出若应用系统在一定时间内没有响应,应给予其他形式反馈信息;Dong-Ham等人主要对手机可用性进行研究,提出框架模型来概念化影响手机相关可用性的各种移动因素;EevaKangas等人针对移动应用系统进行研究分析,提出了以用户为中心的移动应用系统可用性测试方法王俊在硕士学位论文中针对移动应用系统软件提出可用性设计准则〗中科院对利用多通道交互技术来提高手持移动设备可用性做出了理论研究。
我们可以看出,针对手持移动设备用户界面,研究者们主要在移动可用性、移动可用性设计准则及移动可用性评估方法三方面进行研究。然而这些研究多是针对具体某一问题提出了具体解决方法,但就对手持移动环境下可用性相关问题没有给出统一、规范的描述。
(2)交互范式
自在固定办公环境下提出WIMP范式以后,基于其的图形用户界面就占据了用户界面的统治地位。但随着软硬件技术的发展及应用领域的不同(比如:移动互联网环境、虚拟现实环境),WIMP范式已不再适用,随后研究者们在上世纪末提出了及—界面,和等人指出界面指没有桌面隐喻的用户界面认为界面是至少包含一项不属于传统交互技术组件的用户界面,从而将研究方向聚焦在下一代交互范式上:的实验室对进行了大量研究,中科院田丰在笔式交互环境进行了分析研究,提出基于环境的笔式交互范式,房綺等人详细分析了触控交互环境特点从而提出了触控技术中的用户界面交互范式,,张丹洁等人则在三维用户界面进行了研究,提出三维用户界面的交互范式
而以上范式大多是针对某一特定交互环境(笔输入,触控技术等)进行研究,但就手持移动设备自然用户界面却没有人提出相关的交互范式。相关基础理论
第二章手持移动交互环境下用户界面可用性研究
从用户角度来看,交互设计的本质就是关于开发容易使用、有效而且令人愉悦的交互式产品,即一个交互系统不仅要满足功能性需求,同时它也需要具有很好的可用性,这样的系统才是一个令人满意的交互式系统。可用性作为衡量交互产品设计好与坏的一个重要目标,是设计者在设计用户界面时重点考虑的因素之一。而在手持移动环境下,移动可用性已与传统桌面环境发生了很大变化,故本章节针对移动可用性进行探讨,总结移动可用性特点,并就移动可用性特点提出手持移动设备用户界面可用性设计准则及可用性评估方法。
2.1手持移动环境下用户与设备特点
在手持移动环境下,用户与设备同传统桌面环境下具有很大不同。首先,手持移动设备具有资源受限性:手持移动设备,即口袋大小的可随身携带的计算设备,配有小的显示屏幕,单一的输入方式,这种情况下,硬件资源受限是必然的,表现为以下几方面。
1.硬件计算资源(主板、CPU、内存、存储设备等)受限。设备的口袋大小的特点,限制了各种硬件计算资源大小,在现阶段,这直接导致计算能力受到限制。
2.屏幕尺寸受限。手持移动设备配有显示屏幕,但屏幕大小不可能过大。屏幕资源限制导致交互方式与PC不同。
3.硬件配件资源(电池、摄像头、扬声器等)受限。手持移动设备的手持移动特性直接导致的是各种配件资源也会受到限制,如:电池续航能力,摄像头成像效果,扬声器声音大小等。
其次,用户具有平民化特点。
1.用户年龄大众化。手持移动环境下,使用者为普通大众,各个年龄段都有使用手持移动设备的需求:中小学生使用便携手持移动设备接收学校信息;青年使用设备进行娱乐;中老年通过手持移动设备随时与子女沟通信息等等。
2.用户认知水平大众化。使用者大众化使得用户无须专业背景即可通过简单的学习来使用设备,从而用户的认知水平也不再受到限制。
手持移动设备硬件资源是支撑其上用户界面的基础,而用户是手持移动设备的直接使用者,设备受限性和用户平民化将直接导致用户界面与PC用户界面有很大的不同,如用户界面框架、静态界面信息呈现方式(页面元素,布局等、动态交互方式(信息输入输出方式)等。
2.2手持移动环境下移动可用性特点
在第一章相关基础理论一节中已经讨论过了普适可用性,但在手持移动环境下,可用性又有其具体的特点。首先,在手持移动环境下,用户平民化使得交互系统的用户界面必须能够满足易学性、易记性等属性特点;同时,用户及设备的双重移动性导致用户不能将全部注意力资源集中在一个交互任务上,这也要求交互系统必须更加重视有效性、能行性、安全性等属性要求;最后,手持移动设备受自身软硬件限制,其上用户界面的安全性也需要重点考虑。
故手持移动环境下移动可用性特点总结如下。
1.用户与设备双重移动性
双重移动性指用户在移动环境中使用手持移动设备。在这种复杂多变的环境下,用户同设备交互具有多任务性,需要感知迭代的处理并发事件:如使用智能手机打电话的同时翻阅纸质资料查找信息等。这就要求手持移动应用系统用户界面应尽可能易于使用、增加中断恢复机制等,使得用户可随时中断注意力资源,并且在再次继续使用时用户能顺利继续操作。
2.自然、隐式交互
自然、交互隐式交互指用户无需大的认知负担、以最自然的交流方式与应用系统进行互动,即在手持移动环境下,釆用人们自然的交互通道(如听觉、触觉、视觉等)实现用户与移动应用系统用户界面的交互。
3.面向内容交互
面向内容交互指用户关心的是操作内容,而不是如何操作,这是受用户平民化及双重移动性影响的。此时,移动用户界面应突出内容、弱化操作,利用人们的自然认知来满足大众用户使用习惯。
4.多维度交互
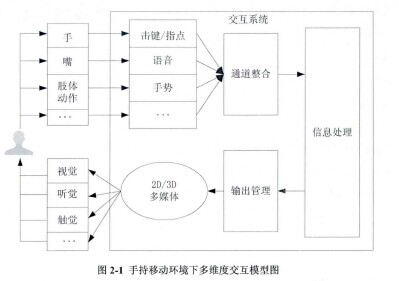
多维度交互指用户使用多个通道(触觉、听觉、视觉等)同手持移动设备交互。受设备自身硬件条件及交互环境影响,多维度交互能够增加用户同用户界面交互的方式,解放用户注意资源,从而大幅度提高用户的使用满意度。手持移动环境下多维度交互模型如图2-1所示。
第三章手持移动设备用户界面交互特征研究........19
3.1手持移动环境交互特征........19
3.2手持移动设备用户界面的信息呈现与交互方式特征...21
3.3典型手持移动设备用户界面信息呈现元素及交互方式统计与归纳.....21
第四章手持移动设备自然用户界面交互范式研究.....25
4.1手持移动设备自然用户界面交互范式提出.....25
4.1.1手持移动设备用户界面交互范式特征.......25
4.1.2手持移动设备自然用户界面交互范式提出......26
第五章手持移动设备自然用户界面交互范式评估.....37
5.1基于PMMG范式及移动可用性设计准则的交互式电子日记.........37
5.1.1使用背景....37
5.1.2系统设计........38
5.1.3应用系统用户界面设计与实现........38
5.1.4应用系统类图设计.......43
第五章手持移动设备自然用户界面交互范式评估
前几章节已经讨论了手持移动环境下的可用性问题,并且基于移动可用性提出了手持移动设备自然用户界面交互范式PMMG。为了验证其可用性,设计开发了一款基于PMMG范式的移动交互式电子曰记。
此应用基于Android平台,根据移动用户界面交互范式PMMG及可用性设计准则对用户界面静态显示方式及交互方式重新进行了设计。
5.1基于PMMG范式及移动可用性设计准则的交互式电子日记
5.1.1使用背景
现实生活中,人们都有提笔书写文字来记录每天发生的事情或感想的习惯。但随着手持移动设备的普及,人们越来越依赖于这种小巧的便携式设备来帮助自己打理一切,其中便包括记录日记。当人们在公园里散步遇到美好的景色时,人们想用照相机记录下来在图书馆看书触发感想时,人们希望能马上将它记录下来;与朋友聊天聊到好听的故事,也希望快速记录等等,这种利用琐碎时间的记录方式是普通拿纸笔记录方式无法有效完成的。然而手持移动设备却给予它可能性,譬如智能手机携带录音、拍照、摄像、文字输入等功能就给出了记录这些景色、灵感、故事的能力。
然而现有的移动平台的日记本的设计模式仍釆用传统PC的设计,即利用一整块时间块来记录日记;需要从外部一次性导入各种信息资源;以point式文字输入为主的信息输入方式等等设计方式。习惯了桌面操作的用户可以慢慢学习直至熟练掌握,但不符合手持移动环境下用户习惯。而交互式电子日记本的设计初衷就是采用非线性的记录方式来记录人们日常生活中的点点滴滴,并旨在通过良好的系统设计来帮助人们快速适应应用系统,并利用自然隐喻界面呈现方式及自然化的交互手势提高人们的用户体验。
总结与展望
工作总结
当代,以手机、PAD等为代表的手持移动设备正以迅猛的劲头发展,从而促使着不同于传统图形用户界面的新的设计范式的研究。本文首先对手持移动环境下设备与用户的特点进行调查研究,分析总结出设备与用户的双重移动性导致的新的移动可用性问题,进而提出了在新的移动可用性客观事实下用户界面可用性设计准则及用户界面可用性评估方法。然后在充分调研研究手持移动设备使用上下文及交互范式理论基础后,结合移动用户认知特点提出了手持移动设备自然用户界面交互范式PMMG。最后依据所提出的移动用户界面设计准则及交互范式设计开发了基于平台的交互式电子曰记,并通过可用性评估实验证明了该系统的高可用性与自然性。具体研究内容与研究成果如下所述:
1.调研手持移动环境下用户同设备的交互上下文特点,总结分析出用户人群具有平民化;设备与用户具有双重移动性;用户界面隐喻手持移动交互环境;用户同用户界面交互的过程中不再关注如何操作,更多的是面向交互内容。
2.研究分析了相关可用性理论研究,结合移动交互上下文特点与移动用户的认知需求,提出了移动可用性:用户与设备双重移动性、面向内容交互、多维度交互。研究普适可用性设计准则并结合移动可用性,提出十条移动可用性设计准则,为设计者设计手持移动设备用户界面提供设计准则,并提出一种基于感知控制的移动用户界面的可用性评估方法,用来评估有许多不确定干扰因素的移动应用系统用户界面。
3.研究分析手持移动环境下用户界面范式特点及移动环境用户认知心理,并在自然用户界面通用隐喻OCGM基础上提出手持移动设备自然用户界面交互范式:
工作展望
本文针对手持移动设备使用上下文进行分析总结,并在移动可用性、移动用户界面可用性设计准则、移动用户界面评估方法及移动交互范式方面做出了初步探讨,并提出了一系列准则及方法。但本文所做的研究正处于初级研究阶段,并且由于手持移动设备在近些年来发展迅猛,新的创新及技术也层出不穷,这些创新及技术都会影响用户与用户界面的交互,从而对交互范式的研究也会产生相应的影响。所以仍有大量的工作需要继续研究完善。具体工作展望如下:
1.用户同手持移动设备的交互上下文具有复杂、不可预测性,本文所提出的十条移动用户界面可用性设计准则主要针对具有大屏幕的手持移动设备,对通用移动用户界面可用性设计准则没有全面考虑,后面需要进一步的研究补充。
2.针对移动应用系统用户界面的评估方法,本文提出的基于感知控制论的移动用户界面可用性评估方法仍处在理论研究状态,仍需要后续研究进行丰富,如用户的行为状态如何影响评估准确性等等。
3.尽管移动交互范式PMMG对手持移动设备用户界面范式提出了新的研究思路和方法,但考虑到手持移动设备交互环境复杂性,仍有不完善之处需要理论研究与应用系统实践评估。
参考文献(略)
计算机应用论文2018年精选范文十:基于文字结构特征的文本图像方向的研究与应用
1 绪论
1.1研究背景与意义
随着经济和科技的发展,计算机技术越来越占据重要的地位,多媒体技术产品也越来越走近我们的生活。将印刷的纸质书籍、文档资料和报纸等大量文字信息以音频播报的方式让人获取,成为越来越多的研究者们关注的焦点。鉴于视障者的特殊需求以及他们在阅读普通书籍遇到的困难,将文字信息用语音的方式阅读给他们听,让这类人群更好更方便的获取正常的生活知识信息成为了研究的热点。为此,北方工业大学开发研制了“盲人阅读辅助器具”(后面简称阅读器,阅读器通过摄像头将纸质文档拍摄为图像,先对图像进行必要的前期处理,然后通过DCR识别技术将文本图像识别为文本的形式,最后通过TTS语音合成技术,将TXT文本通过语音播报的方式输出,实现了文字信息到声音信息的自动转换。
如图模型所示,阅读器的卡纸可以很好的限制纸张倾斜放置,然而盲人和视力障碍者并不能分辨纸张的放置方向和文档的内容方向,进而导致摄像头抓获的文本内容出现横放和倒置的现象。目前对于规则方向的文本方向检测与矫正,国内外学者也做了一些研究。文献提出了基于识别率反馈的文本图像方向检测算法。文献中提出的问题图像倒置快速检测算法,利用文本中标点和汉字的相对位置特征来判断是否倒置。文献提出了基于文字投影信息量判断文字方向的方图盲人阅读辅助器具法。文献中介绍了一种基于文本内容方向置信度检测的装置,根据统计文本方向的置信度与库中对比来判断文本的方向。文献则介绍了基于汉字十字结构特征的文本方向检测方法。然而大多现存算法对通过拍照获取的图片的判断效果不好,同时由于嵌入式版的内嵌处理器问题,现有的算法并不能满足处理过程的时效性。因此本课题就是针对提高阅图读器实时判断文本方向并进行纠正处理而提出的。准确实时的判断出文本内容的方向对整个项目的目标有重要意义。也是阅读器纸书阅读功能能否更加智能的重要一步,具有重要的实用价值。

1.2论文的研究方法和创新点;
本文的研宄方法:
在数字图像处理领域,对于图像的方向检测与矫正的算法很多学者已作过一些工作,但目前的算法并不能满足项目的功能需求,同时即使一些算法能满足项目部分模块的功能需求,但是在准确性和效率方面并不能直接用于项目中,实用性并不是很好。
所以本课题在总结前人对文本图像研宄工作的基础上,结合文本排版的特征和文字结构与笔画特征,研究并实现了适合用在视障者阅读辅具上的一种针对文档排版和规则方向的检测校正的算法,并且运用大量文档图像进行实验,以统计算法的准确性并通过实验得出算法中一些参数的经验值以提高算法的执行效率。
本文的创新点:
(1)在检测文本图像文本线走向时,分别利用文本图像的投影统计特征和文本行延伸的方法,快速的判断文本图像所属的校正类别;
(2)利用连通域搜索的方法进行字符分割,通过计算字符的宽和高,利用普通印刷汉字的宽高比结合文本线的走向判断文本的排版方式;
(3)运用动态回归的笔画跟踪算法提取汉字撇笔画的轨迹,快速抽取到目标笔画;
(4)利用汉字撇笔画的书写特征结合上述算法,准确的判断出文本的方向并校正。
(5)大量的实验验证后将部分算法移植到阅读器上应用。
2阅读书阅读系统的组成
纸书阅读系统主要涉及到计算机视觉、模式识别和语音转换输出等技术。首先通过摄像头获取待识别的对象(即文本图像),经过计算机系统处理和文字识别,得到文本的文字信息,最后通过输出设备转换为语音输出。系统的大致过程如下图2.1:
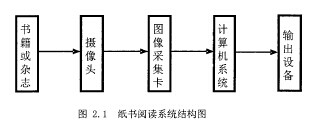
其中计算机系统模块包括三个部分:预处理、方向判断与矫正和文字识别。图像预处理是整个系统的前提,然后对文本内容的方向进行检测和矫正,这是汉字识别结果的决定性因素。最后将处理好的文本图像通过进行文字识别,得到文本内容,进而进行下一步的语音转换输出播报目标书籍或杂志的内容。
2.1图像采集
2.1.1图像获取
课题最终的目的是要做成便携式的智能阅读器,显然扫描设备的庞大体积并不能满足课题的需求,而越来越精巧的数码摄像头恰好可以满足便携的要求,因此本系统运用摄像头图像采集作为输入设备。图像采集就是纸质文档进行图像数字化,主要涉及到成像及模数转换技术。图像采集设备一般包括电稱合设备高像素摄像头和图像采集卡首先通过高灵敏摄像头获取到模拟图像信号,然后利用图像采集卡对模拟信号进行采集和处理,将模拟信号转化为数字图像。目前市场上很多流行的数码成像设备都内嵌了功能硬件而不需要其它数字化设备的支持,可以直接运用串口、并口或移动接口向计算机输入数字图像,且具有很高的分辨率,方便用户进行编辑和使用。
2.1.2图像存储格式
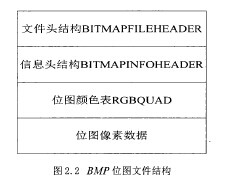
本系统运用摄像头采集图片,将图片以格式存储。位图是将图像中的全部像素转换为数据,完整的记录图像的信息,因此存储时所占用的磁盘空间会很大。为了减小存储图片的磁盘空间开销,系统采用了8位位图,而不是24位未位图。BMP位图采用二维矩阵表示,其中包含:“文件头、位图信息头、位图颜色表和位图像素数据,结构如图片2.2所示:
2.2纸书阅读系统
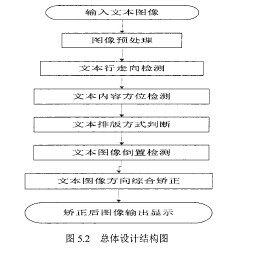
纸书阅读系统由图像的预处理、图像方向检测与矫正和文本内容识别播报三大部分组成。
图像预处理部分包括图像灰度化、二值化处理、图像去噪处理和字符分割四部分。图像预处理是整个系统的奏效的前提。因此通过多个方法、算法进行分析、实验、对比和改进,各部分得到一个最佳处理方案。
图像方向检测与矫正部分包括文本线走向检测、文本排版方式检测和文本方向检测与矫正三部分。这部分是整个系统的核心,正确的文本方向是文字识别正确率高低的分水岭。因此要分析各种方法的特定条件下的实用性与可行性。同时通过实验验证和实验数据的比较、分析和统计,得到算法中一些参数的经验值,以得到准确率更高的文本图像方向矫正算法。
文本内容识别播报是文本图像的后续处理,是将处理好的文本图像内容提取然后转换成语音播报的过程。
2.2.1灰度化
对图像进行处理之前,需将摄像头获取的彩色图像进行灰度化,转换成256色的灰度图像因为对于计算机而言,在图像处理过程中,彩色图像处理是很不方便的。
2.2.2二值化
为了分析图像特征,使后续的处理更为简便,需要将灰度化后的图像转换为只有0和255两个灰度级的图像即二值图像。二值图像有很多的优点,首先它不仅占用的存储空间小,而且在计算上也更加快速和方便,在随后字符分割和文本方向检测校正进行的处理都是针对二值图像进行的,所以说,将图像二值化处理是图像预处理中相当重要的一步。
2.2.3图像去噪
我们将图像中妨碍人们对目标信息获取的各种因素称为图像噪声。这些噪声可能在传播中产生,也可能在量化中产生。对于系统采集的文本图像,噪声更多的是在图像釆集过程中产生,这类噪声称为乘性噪声。图像去噪就是要去除二值图像中影响文本内容信息被正确获取的干扰因素。
3图像预处理技术的研究.....6
3.1图像灰度化......6
3.2图像二值化.......7
3.2.1OTSU算法....7
3.2.2迭代求最优阈值法......8
3.2.3灰度加权阈值算法......8
4文本图像规则方向检测算法的研究......17
4.1几种不同的文本图像倒置判断算法....17
4.1.1基于识别率反馈算法......17
4.1.2基于标点符号的检测方法.....18
5文本图像矫正系统的设计实现与应用......19
5.1课题随体设计方案....27
5.2核心模块的设计.....28
5.3系统测试与应用分析......28
5文本图像矫正雜的断实现与应用
为了验证本课题算法的可行性,将算法移植到嵌入式盲用阅读器系统纸书阅读功能模块中。该模块主要包括四个部分:摄像头图像采集(主要基于SDK)、文本图像处理、文字识别(主要基于市场上流行的OCR软件SDK)和语音合成(主要基于市场上流行的TTS软件SDK。纸书阅读模块的整个处理流程如下图:
本课题是基于阅读器纸书阅读模块文本图像处理部分提出的,是阅读器系统的重要组成部分。下面介绍课题的详细设计方案;
5.1课题的整体设计方案
课题的总体结构图为:
6结束语
6.1总结
在充分的理论学习、大量相关文献查阅的基础上已经导师的精心指导下,结合项目的特点,完成了课题的研究和开发工作。
本课题以文本图像作为研究对象,提出并实现了文本排版检测和文本方向检测算法以及算法的移植应用,工作包括文本图像的预处理算法的研究(图像的灰度化、二值化、去噪、字符分割)、文本排版方式检测、汉字憋笔画的提取、文本图像方向检测以及文本方向的综合校正和算法的应用移植。文本首先根据文本图像投影的特征和文本行汉字相邻位置的关系,提出了文本行走向检测算法。然后通过对汉字的整体结构特征和汉字构件笔画特征研宄,提出了文本内容放置方位检测算法和基于汉字笔画特征的文本图像倒置判断算法。最后项目的实际应用角度出发,对算法进行部分的移植应用。基本上完成了开题报告需要完成的工作。
当然,本课题也有需要改进的地方:
首先,提高降噪能力。降噪能力的好坏直接关系到文本后续处理的效果,因此为了取得更好的去噪效果,可以使用小波去噪。要达到即使采集的文本图像质量较差,也要能得到较清晰的文本前景和背景图像。当然也要把握好算法的效率和准确率之间的关系。
其次,功能的完备性与时效性总是矛盾的,在算法移植到阅读器中时,若要算法全部移植,必然会延长阅读器纸书阅读整个流程的时间。尤其是在加入文本排版校正时,大大加长了识别过程的时间,使整个功能的实用性大大降低。为了保证阅读器的处理时间在可控的范围,目前只移植了对横排文本的四个方向的检测与校正。文本排版方式检测的移植需要对整个算法进行优化或者寻找新的判断方法。
6.2展望
本课题虽然完成了开题报告的全部工作,但是仍然有很多地方需要改进,比如文本方位检测算法并没有得到大量的联机实验调试,同时算法还有很多有待进一步优化的地方,算法的一些参数需要更多的实验进行矫正等,通过上述的工作,本文算法的准确率可以得到一定的提高。
在算法应用方面,可以进一步增加摄像头的像素以获取质量更好的文本图像,同时可以幵发新的开发板以加快系统的处理能力,增强阅读器的实用性,为阅读器的产品化和市场化助力。
参考文献(略)