第 1 章 绪 论
1.1 课题背景及研究目的和意义
语言(Language,)是人类社会进行相互思想交流、彼此联系的工具,每一种语言由语音、词汇和语法构成[1]。语言和文化构成了一个民族的生命,如今世界科学技术快速发展,各个国家和民族均处于信息化时代,自然语言信息处理作为计算机科学技术和语言学的交叉学科,它关注利用计算机技术来学习、理解和生成人类的语言,伴随着人工智能、大数据、机器人等的到来,成为了每一个民族语言信息处理的核心研究问题之一。Bill Manaris 在《计算机进展》第 47 卷的“从人-机交互的角度看自然语言处理”中为自然语言处理(Natural Language Processing-NLP,)给出了明确的定义为:“自然语言处理是研究在人与人交际中以及在人与计算机交际中的语言问题的一门学科。自然语言处理要研制表示语言能力和语言应用的模型,建立计算框架来实现这样的语言模型,提出相应的方法来不断地完善这样的模型,根据这样的语言模型设计各种实用系统,并探讨这些实用系统的评测技术”[2]。其研究目标是让计算机执行涉及到人类语言的有效任务,进行人机交流,提高人与人之间的沟通,做有意义文本或语音处理[3]。自然语言具有一定的内部结构层次联系,自然语言处理模型包含以下相关知识[4-6]:语音分析(Phonology)、词法分析(morphology)、句法分析(syntax)、语义分析(senmantic)、语用分析(pragmatic)、话语(Discourse)和世界上语言自身基本知识特性分析。歧义消解(disambiguation)问题和解决该语言中未知语言信息问题成为了任何语言的自然语言处理研究关键问题。本文的哈萨克语词法分析和基本短语识别研究,同任何其他语言一样是哈萨克语信息处理过程中的基础性和关键性问题,其研究结果将影响后续的哈萨克语自然语言处理问题,同时映射到其应用系统的性能研发,如:机器翻译、文本摘要、社会计算问题等应用系统。哈萨克族(Kazakh,Qazaq, )是跨境民族,同时是世居哈萨克斯坦共和国的主体民族,哈萨克族居住在不同国家和地区,如:哈萨克斯坦共和国、中国、外蒙古国等国家,历代哈萨克族大多数人过着草原的游牧生活。哈萨克族作为中国 56 个民族之一,大部分居住在中国新疆北部等地区。
........
1.2 国内外研究现状
世界上英语、汉语和土耳其语等的词法自动分析研究已经成熟,有各种各样的形态分析等技术用于词法自动剖析,而且不同的语言对词法分析的研究内容侧重点不同。例如:英语以词标注为重点问题,汉语以分词为重点问题。词法分析研究一般采用三种方法:基于规则的方法(Rule-Based approach);基于统计的方法(Statistics-Based approach);基于它们俩相联合的方法;还有基于神经网络的深度学习新方法等。基于规则方法是利用文本中该词上下文联系语法规则在特定标注语言中进行词法分析。例如:E.Brill 提出了一系列基于语言规律的词法分析方法,1992年提出并实现了基于规则的词性标注[10],1994 年又进行改进[11],紧接着 1995年再提出的基于错误驱动词性标注[12]是利用初始状态标注器标识没有标注语料文本来形成已标注语料文本,然后比较学习到转换方法,并生成排序的转换规律集。依据统计的方法需要一定规模的语料库来为统计模型使用。例如:I.Marshall 构建的 CLAWS ( Constituent-Likelihood Automatic Word-taggingSystem)[13]语料库词性标注系统,它使用 n 元语法和一阶 Markov 转移矩阵实现了词性标注。随着隐马尔可夫统计模型[14]应用于语音识别后,统计语言模型就被运用到了自然语言处理的各个层面研究。常用的统计语言模型有:n 元文法(N-Gram model)模型,隐马尔可夫(Hidden Markov Model,HMM)模型,最大熵(Maximum Entropy,MaxEnt)模型[15],条件随机场(Conditional Radom Fields,CRFs)模型[16], 神经网络(NeuralNetworks,NN)模型[17],感知机(Perceptron)[18]等,这些统计模型被研究者们成功地应用于词性标注等研究问题。例如,隐马尔可夫模型的词性标注[19]和最大熵模型的词性标注[20]研究以及词法标注器[21]。
........
第2章 哈萨克语文本语料库构建和词信息分析
2.1 引言
用统计语言模型方法处理自然语言的基础资源是语料库,语料库(Copus)是经过科学取样和加工的大规模电子文本库,它是大量自然语言文本的仓库。而哈萨克语属于资源稀缺的语言(Low-Resource Languages,LRLs),特别是中国境内的以阿拉伯字符为字母符号的老文字,既没有已标注好的语料库,也没有哈语信息处理所需要的基本规范。虽然哈萨克斯坦的信息处理研究可借鉴,但是不能直接引用。因此,哈语的文本信息表示和处理规范化、语料库构建及资源库建设是哈语信息化处理领域中首要问题,是进行词法分析等后续其他研究的必要前提,如何在有限资源上进行哈萨克语词法分析和基本短语识别研究具有一定的挑战性,并且有一定的难度。哈萨克语具备突厥语言典型的结构特点,同时又具有独特的黏着性特性,具有多种形态变化,其词干后可连接多个且不同的语法功能的词缀,通过不同构形附加成分来表现其形态变化。因此,本文针对中国哈语信息处理所需的语料库缺乏问题,提出了构建适合中国哈萨克语语料库(The Kazakh LanguageCorpus)的方法和相关规范的探索,并且构建和建设了后续研究所需的资源库。本章首先介绍哈语信息的规范化处理,再描述了语料库构建与查错,通过基于语料库的词频分析等研究,进行了语言特征、语言现象的词分布和词频等词信息分析和统计研究。本章其他内容安排如下,第 2 节定义哈语信息处理研究中的规范化术语,以便后续研究工作的传承性;第 3 节构建语料库,提出了语料库构建的规范标注内容,为后面的研究打下语料基础;第 4 节在前面构建的语料库基础上进行了词信息统计分析,说明哈语服从 Zif’s 规律,揭示哈萨克语某些语言规律;第 5 节基于 n-gram 的文本查错,完善本文语料库的质量;最后小节总结本章的主要工作。
...........
2.2 哈萨克语语料库构建方法研究
自然语言处理研究目的是实现计算机对人类文字信息的自动理解并能自动生成。为达到这个目标,计算机需要获取大量语言知识库和语料库,而语料库的构建能利用计算机从大规模的真实语言语料中发现和获取语言规律知识,能满足自然语言处理需求。因此,基于语料库的语言处理研究成为了十分热门的方向,它能够从词、句法和语义等标注的语料库中提供语言知识。世界上第一个计算机语料库是美国布朗语料库,随后各个国家和多种语言都相继构建了不同语言、不同目的、不同规模的语料库,部分具有丰富资源语言(High-ResourceLanguages,HRLs)的著名语料库见表 2-1 所示。美国的布朗语料库构建目的是研究现代美国英语,使用系统性原则收集100 万词次英语文本,使用基于规则和 86 种语法标记进行了词性自动标注。70年代英国用于现代英语的 LOB 语料库,也收集 100 万词次,但采用 133 种语法标记,实现的 CLAWS 系统是基于统计模型的词性标注典型代表。而美国宾夕法尼亚大学的语言资源协会(Linguistic Data Consortium)[92]是目前最大世界各种语言资源中心,其中著名的有宾州树库[93]。
...........
第 3 章 基于规则的哈萨克语形态分析 ..........38
3.1 引言 ............. 38
3.2 依据规则的哈萨克语词形态分析方法 ............ 40
3.2.1 哈萨克语词形态学分析内容 .......... 41
3.2.2 哈萨克语的音节分析方法 .............. 43
3.2.3 哈萨克语词形态的歧义消解方法 ............. 44
3.3 哈萨克语双层词法模型形态分析方法 ............ 46
3.4 实验与分析 ............ 50
3.5 本章小结 ..... 55
第 4 章 基于统计模型的哈萨克语词性标注 .............57
4.1 引言 ............. 57
4.2 哈萨克语规范词性标记集研究 ............. 58
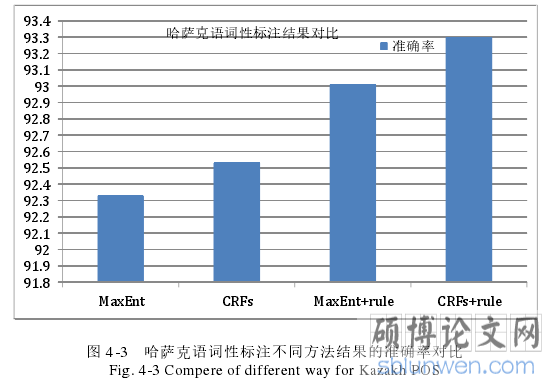
4.3 依据最大熵的哈萨克语词性标注 ......... 60
4.4 依据条件随机场的哈萨克语词性标注 ............ 65
4.5 本章小结 ..... 73
第 5 章 基于规则和统计的哈萨克语基本短语识别 ............74
5.1 引言 ............. 74
5.2 依据规则的哈萨克语基本短语识别 ..... 74
5.2.1 哈语基本短语识别规则的构建 ...... 75
5.2.2 哈萨克语基本短语歧义消解 .......... 76
5.3 依据统计的哈萨克语基本短语识别和标注 .... 77
5.4 哈萨克语短语库的构建 .............. 86
第5章 基于规则和统计的哈萨克语基本短语识别
5.1 引言
本章探索哈语浅层句法分析方法,实现基本短语的识别和标注,研究了哈语基本短语结构,并对其构成结构体系进行分析,确定了名词性、形容词性、动词性等基本短语结构和构成规则;提出了基于语言规则的哈语基本短语识别方法,基本短语歧义消解方法,实现了基于统计模型的哈语基本短语识别。本章后续内容安排如下,第 2 节通过哈语短语结构分析,提出了依据哈语规律的短语识别,为后续研究打下了基础;第 3 节进行依据统计的哈语基本短语识别研究,分别用最大熵模型实现了基本短语的识别,用条件随机场实现基本短语的识别,并进行实验与分析;第 4 节构建了哈语固定短语库;最后小节总结了本章的主要贡献。Abney[34]5提出了英语短语描述体系,成为了许多语言短语描述的典范;周强[140]等通过构建规则库并选出符合条件的规则,对汉语基本短语进行了识别研究。哈语基本短语是以核心词为中心词,内部不含其它短语的语言单位。而哈语基本动词短语是以动词为中心词的基本短语,它一般在句子末尾呈现,极少其它位置呈现。哈语的基本名词短语是以名词为中心词的基本短语,在哈语中数量最多。
........
结 论
语言和文化是每个民族的生命,在飞速发展科技的今天,自然语言信息处理是重要研究课题之一。哈萨克语(简称:哈语)是阿尔泰语系突厥语族的克普恰克语的跨境语言,她是哈萨克斯坦共和国的官方语言。全球的哈萨克族(简称:哈族)都说统一的口语,却采用不同的书写文字符号。世居中国的哈族采用阿拉伯语字母,而世居哈萨克斯坦共和国的哈族采用斯拉夫字母。“一带一路”的实现需要以此沿线语言为基础,语言相通才能进一步实现规划;而哈语是中国和哈萨克斯坦共和国间国际文化交流的纽带,哈语信息处理更是“一带一路”建设的迫切需求。本文的哈语词法分析和基本短语识别的问题是基础性研究,其研究成果可推广到中国和国际上哈语信息领域后续研究和应用产品的研发,可以直接为“一带一路”建设服务,具有重要国际意义和实用价值。本文根据哈语本身特性,以研究哈语信息处理基础语料库构建、词法分析和基本短语识别为出发点,采取规则和统计的信息处理方法,重点对哈语词的形态分析、构形附加成分切分和词形态还原、字母和词频率统计、词干提取、词性标注、文本语料库构建等问题展开了深入的研究,为进一步地进行哈语信息处理等研究打下基础。具体来说,本论文的主要研究成果如下:
(1)研究哈语语料库构建方法,创建了文本语料库,进行了词信息分析。中国哈语是资源语料库缺少的语言,本文针对哈文语料库加工与深度分析,提出了哈文语料库以词的词性、词干、附加成分为加工的设计方案,制定了哈语语料库规范和标注内容;并用 n-gram 进行了基于语料库的词查错研究,构建和建设了哈语文本语料库和资源库。针对语料库的哈文词信息统计问题,本文研究了字母、词频、词汇长度等语言信息统计,说明了哈语符合 ZIP 定律,实现了字母统计、词频统计、词长度统计等,解释了哈萨克语词频与长度等间的关系,依据语料库文本揭示了哈语语言现象;以国家语言绿皮书的形式发布了哈萨克语的语言生活绿皮书。
(2)研究哈萨克语的形态分析,实现了词干提取。哈萨克语的形态分析包括词的附加成分切分与还原,本文以构形附加成分为主,以构词附加成分为辅。即对词干、词尾和词缀的分割。依据哈语形态特点,本文分析了词的构形附加成分粘连规则和正词法规则,歧义消解分析,构建了哈语词法形态的语言规则和词形态模型;提出了依据哈语特性规则的词干提取算法和音节划分算法,并用最大匹配算法进行全切分,即从右到左对词干提取和从左到右对词的附加成分切分。提出了依据最大匹配算法结合哈语形态规律和模型来进行词全切分的形态分析解决方案,实现了哈萨克语构形附加成分切分与形态还原、词的音节切分、词干提取等。
(3)研究了哈萨克语的词性标注,实现了词级标注。哈语的词法分析包括词形态分析和词性标注。本文结合传统哈语词法和计算语言学,制定了信息处理中哈语词类标记集、附加成分和基本短语的规范标记集。提出了哈语词的标注规范化为以词性、词干、词的构形附加成分、兼类词为标注的规范方案;提出了以哈语词和词性为特征的统计模型词性标注的技术方法,通过采用最大熵模型进行一般词的词性标注,增加当前词前后词的特征信息且采用条件随机场模型对兼类词进行词性标注;针对未登录词,特别根据哈语只有名词、形容词、副词和量词具有未登录词的现象,将未登录词全部同时设为这四种词性,将未登录词转变为兼类词再进行词性标注处理,同时最后,根据哈萨克语词由词干和附加成分构成形态特性,而且不同附加成分具有自己的词性类别,针对歧义标注的结果,再次进行了基于附加成分词性的不同规则来词性标注,进一步提高了标注的性能,实现了哈语基本词、兼类词和未登录词的词性标注,提出了哈语语言规律与统计模型相联合的哈语词性标注实现方法。
..........
参考文献(略)