CHAPTER ONE INTRODUCTION
1.1 Study background
The origin of studies on translation universals can date back to 1970s when Toury (1978) put forward that there might be some “universals” in translation. He thought that there was “A general trend is that translation will reveal the implicit information in the source text without being influenced by the translator's identity, language, style and times”. Also, Blum-Kulka, S. & Levenston, E. A. (1983) raised a more specific concept of “explicit hypothesis” believing that “Without considering the differences between the language system and the text system, the use of cohesive devices observed in the translated text is more significant than that in the original text”. With the development of electronic software, corpus linguistics emerged and was gradually introduced to the translation studies. In 1993, Mona Baker (1993: 243) first applied the corpus into the studies of translation universals, thus founding the corpus-based translation studies.
Since then, more and more linguist researchers have begun to do studies with corpora to make contributions to studies of translation universals from various perspectives. However, most of the studies focus on the written translation or using the written translation to prove translation universals in interpreting, and the studies based on the combination of interpreting corpora and interpreting process are still limited.
In the process of Chinese-English simultaneous interpretation, features in the target language may be different from both native English and Chinese-English written translation. They are the reflections of cultural differences and characteristics of the simultaneous interpretation. The corpus-based studies of interpreting have covered some areas including vocabulary, syntax and discourse, but the studies on conversion of subjects in Chinese-English simultaneous interpretation has been wanting.
.............................
1.2 Purpose and significance
In view of the above background, this study aims to explore the conversion of subjects during the Chinese-English simultaneous interpretation by solving the following three research questions:
1) What strategies do interpreters adopt when interpreting subjects in Chinese-English simultaneous interpretation?
2) What are the differences between the interpreted English and the native English in the use of subjects, if any?
3) What are the reasons for the adoption of the interpreting strategies of subjects in Chinese-English simultaneous interpretation?
The research conclusion is expected to contribute to interpreting studies, especially the interpreting studies under the perspective of translation universals, and be helpful to guide the interpreting teaching.
This study is meaningful theoretically, methodologically and practically. First and foremost, on the theoretic level, this study extends the interpreting studies of translation universals. Based on the authentic materials of conference interpreting, this study analyzes the conversion of the subjects in the Chinese-English simultaneous interpretation and explores the reasons of the conversion. It infuses new blood to interpreting studies, promotes the development of interpreting studies and teaching and provides a reference for others who are conducting or will conduct similar research. What’s more, the materials of this study are selected from an authentic conference.
.............................
CHAPTER TWO LITERATURE REVIEW
2.1 Origin and current research of translation universals
It is Baker (1993:234) who first proposed the concept of translation universals saying that the translation texts have their own distinctive linguistic characters which are neither effected by the original language nor the target language. Based on the research of Vanderauwera (1985) and Blum-Kulka (1986) and Shlesinger (1991), she summarized translation universals into three groups: simplification, explicitation and normalization. Since then, represented by Baker (1993,1995,1996), Laviosa, S. (2002), Kenny, D. (1998,2001), Olohan, M. & Baker (2000), Mauranen, A. (2003), Puurtinen (2003a,2003b) etc., linguistic researchers have been studied translation universals from various perspectives.
The studies on simplification have been mainly related to the simplification of vocabulary, syntax and style studied by Blum-Kulka, S.& Levenston, E. A. (1983), Vanderauwera, R. (1985), and Baker, M. (1992/2000), while the studies on explicitation have been touched on two types: lexical explicitation and information explicitation. Both of them seem like the result of context or situation requirements, but in essence they are the very outcome of the differences of languages and can be attribute to the category of mandatory explicitation. What’s more, Vanderauwera, R. (1985) and Toury, G. (1995/2001) have conducted the research on normalization and found out characters in the target language. From punctuation, diction, and style to sentence structure and discourse construction, translation texts tend to adhere to the use norm of the target language. Also, Toury, G. (1995/2001) raised that the normalization contains both the comparison between the interlingual translation and the comparison between the translation texts and the original texts. These researches have broadened the horizon of translation universals studies and offered multiple views to further studies.
...............................
2.2 Studies on translation universals
Since translation universals hypothesis, various hypotheses have emerged abroad and at home. Frawley (1984) believed that the translation language is a third language code or a translation interlanguage. After Baker introduced corpora into translation studies, linguistic researchers began to carry out their studies on translation universals based on the corpus and new discoveries have been achieved both in written translation and interpreting.
2.2.1 Studies on translation universals abroad
At present, most of the studies on translation universals focus on written translation. This part introduces the development of the three groups of translation universals: simplification, explicitation and normalization.
2.2.1.1 Simplification
Vanderanwera’s study (1985) on syntactic simplification shows that a translator inclines to translate a non-finite clause into a finite clause to simplify the syntactic structures in the translation. From the point of Mona Baker (1996), simplification is that there is a trend that a translator simplifies the information of the Original language during the translation. The simplification can occur in both vocabular and syntax no mater consciously or subconsciously. That is to say that the original language serves as a reference for the target language when defining whether simplification exists. Later, through macro statistics, Laviosa, S. (1998) studied the simplification from the perspectives of lexical density, the average length of a sentence and high frequency vocabulary in a comparable corpus. According to her research, there is a lower percentage of notional words and a high percentage of function words in the translated language than that in the original language. The translated language shows a lower lexical density. Also, the ratio of high frequency words to low frequency words is higher in the translated language. The results are that the translated language contains lower lexical density, shorter average length of a sentence and a further higher frequency of commonly used words. The research results are further confirmed later by Corpas Pastor et al. (2008: 4) through NLP (Natural Language Process) approach.
..............................
CHAPTER THREE RESEARCH METHODOLOGY ............................... 18
3.1 Research questions ............................ 18
3.2 Corpus of the study .................................... 19
CHAPTER FOUR RESULTS AND DISCUSSION ................................ 31
4.1 Statistics of the conversion of subjects in Chinese-English interpreting........................... 31
4.2 Conversion of subject .................................... 32
CHAPTER FIVE CONCLUSION ..................................... 50
5.1 Major findings .............................. 53
5.2 Research implications .............................. 53
CHAPTER FOUR RESULTS AND DISCUSSION
4.1 Statistics of the conversion of subjects in Chinese-English interpreting
On the basis of the preparation stated in the previous chapter, in this chapter, the specific situation of corpus is counted. See the table below for details:
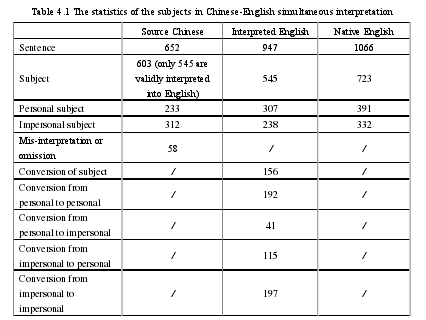
...........................
CHAPTER FIVE CONCLUSION
5.1 Major findings
On the basis of the translation universal, the study carries out a research on the subject conversion during Chinese-English simultaneous interpretation. The corpus is built on the basis of two sessions of 2016 Summer Davos Forum. The three research questions are as follows:
1) What strategies do interpreters adopt when interpreting subjects in Chinese-English simultaneous interpretation?
2) What are the differences between the interpreted English and the native English in the use of subjects, if any?
3) What are the reasons for the adoption of the interpreting strategies of subjects in Chinese-English simultaneous interpretation?
To solve the research questions, the author selects three sessions from 2016 and 2018 Summer Davos Forum. There is a reason to believe that the interpreters who work for this high-level forum are professional and skillful with rich interpreting experience. Through transcription and collation, the corpus of this study is established. Then, according to both Chinese and English syntactic rules, the transcribed text is divided into sentence by sentence and their subjects are also classified based on the subject definitions of both Chinese and English. When this part is finished, the first research question is answered. Then, after calculating the number of personal subjects and impersonal subjects in original Chinese, interpreted English and native English, by SPSS, the significant differences in subject use among the three corpora are summarized to answer the second research question. Finally, from the view of translation universals, the third research question is answered. The findings of this study are as following:
reference(omitted)