本文是一篇计算机论文,本文提出一种基于改进LightGBM(轻量梯度提升机制)和强化K-means(k均值聚类分析)的双阶段入侵检测框架,该框架通过改进的数据流结构巧妙融合了前者检测率高与后者准确率高的优点,并克服了前者误报率高与后者时间开销大的缺陷。
第一章绪论
1.1研究背景与意义
随着网络信息技术的飞速发展和广泛应用,基于网络信息系统的使用场景已扩展到了社会的各行各业覆盖了包括政府、国防、工业、金融、教育、卫生等各个领域。第47次《中国互联网络发展状况统计报告》[3]指出,截止到2020年12月,我国网络用户规模达到了9.89亿人,相比9个月前新增了8540万网络用户,同年互联网普及率为70.4%。图1-2显示了历年互联网普及率的变化。
计算机论文怎么写
伴随计算机网络的普及和大数据、云计算、区块链等技术的应用,网络安全事件层出不穷且愈演愈烈,与网络空间相连的信息系统面临着前所未有的威胁。从我国国家互联网应急中心发布的《2020年中国互联网网络安全报告》[4]中可以发现,2020年我国的网络安全形势依然严峻,网络攻击的技术和手段在不断升级。各国将更加重视网络安全的发展,网络安全已成为国家重要战略资源和生产要素。在《2020中国网络安全企业100强报告》中提到,未来十年,中国网络安全市场规模将增长十倍、网络安全会成为优先级最高的IT投资、网络安全将成为第一生产力。由此可见,利用一些技术手段来检测网络中存在的攻击事件,维护国家网络空间主权以及维护社会的网络安全尤为必要。
.................................
1.2研究现状
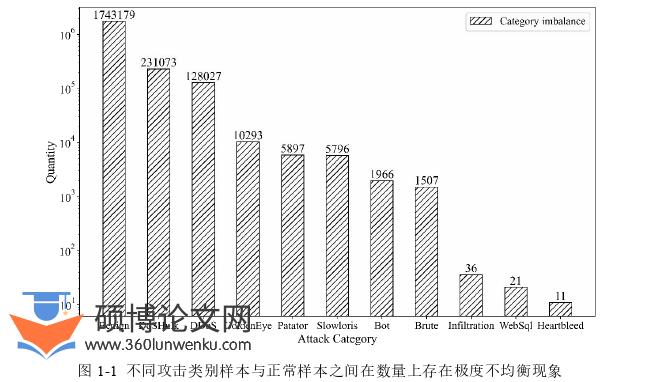
在有线网(如云)和无线网(如物联网)融合的背景下,每天产生的系统日志和网络流量数据量非常庞大[13]。从海量数据中快速提取攻击特征并准确检测攻击行为是一个巨大的挑战。最重要的是,攻击行为数量与正常行为数量高度不均衡导致攻击行为隐蔽的混杂在海量正常行为中,给入侵检测的研究增加了难度。目前,为了解决样本极度不均衡场景下入侵检测和攻击分类难的问题国内外展开了广泛研究。下面将首先介绍现有研究提出的入侵检测技术,并通过四个方面介绍国内外学者是如何降低和消除不均衡现象给入侵检测带来的干扰。
1.2.1入侵检测技术
有监督模型:Belavagi等人[14]通过比较逻辑回归、高斯朴素贝叶斯、随机森林等模型发现随机森林在入侵检测中比其他模型更有效。然而,他们没有对模型进行有效的改进。Min Du等人[15]将LSTM用于系统日志数据的入侵检测,鉴于系统日志的不断变化,他们还提出了如何在线更新模型以响应变化。他们提出的模型可以处理包含多个任务或具有并发线程任务的序列。Kazi Abu Taher等人[16]将特征过滤与有监督学习模型相结合以找到能够更好识别恶意流量的组合模式。他们发现具有包装特征选择的人工神经网络在入侵检测方面优于支持向量机。然而,他们并未与其他优秀的有监督模型进行多维度的比较。Paulo Angelo Alves Resende等人[17]使用随机森林模型进行入侵检测和攻击分类。田志宏等人[18]开发了一种用于URL分析的网络攻击检测系统,该系统使用分布式深度学习技术能够配置在边缘设备上。此外,该系统结合了多个并发深度模型能够实现快速更新从而增强系统的稳定性。M Shafiq等人[19]提出一种用于识别网络中恶意流量的框架模型,该框架使用的过滤模型(CorrAUC)能够筛选有用特征并消除无用特征对攻击分类的干扰。
半监督模型:Christopher T.Symons等人[20]提出了一种用于网络安全入侵检测的无参数半监督学习模型。他们提出的模型是非参数的可以提高模型的灵活性并避免添加对模型没有实际影响的约束。该模型的优点在于能够检测具有高隐蔽性的恶意入侵。Mutahir Nadeem等人[21]结合神经网络和无监督模型进行入侵检测。与有监督的入侵检测模型相比,该模型仅使用少量标记样本即可实现高检测率。姚海鹏等人[22]使用分层半监督K-means聚类模型来识别入侵行为。鉴于正负样本的数量极不平衡,他们在模型中添加了欠采样方法对攻击行为进行精细分类。然而他们的模型在建模过程中并没有改进数据流结构,导致在入侵检测过程中产生了过多的时间开销。Muhammad Shafiq等人[23]提出了一种新的名为CorrACC的特征选择度量方法,该方法能够实现物联网场景下有效特征选择问题从而提高入侵检测准确率。
.......................
第二章入侵检测概述
2.1基本概念
入侵检测主要通过监测系统中的各种操作以及网络中的各种行为事件,对数据进行研究分析来实时、精准的识别攻击的过程,它是一种主动的安全防御机制。入侵检测系统与防火墙功能互补,用于对付网络中存在的各种攻击事件从而遏制攻击危害的蔓延(如红队攻击最大的特点就是横向移动、扩大战果。攻击一旦逃避检测就会躲藏在系统中伺机而动,通过情报搜索获取主机的资产和漏洞信息从而得到入侵同一网络中其他主机的权限,最终使整个网络系统瘫痪)。入侵检测扩展了系统管理员的安全管理能力(包括安全审计、监视、进攻识别和响应),提升信息系统的安全架构。它也常被认为是防御系统中继防火墙之后的第二道安全闸门,在确保网络正常运行的情况下对网络进行实时监测,以抵御内部攻击和外部攻击。
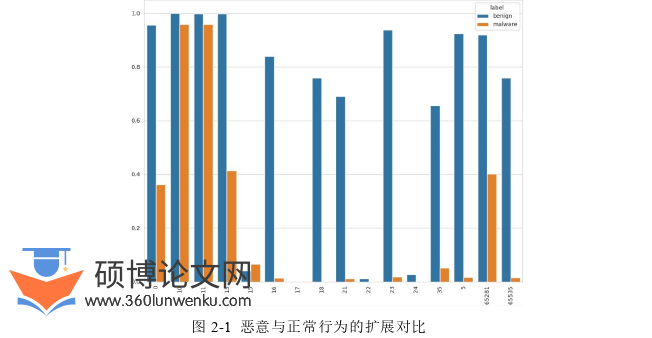
大量研究发现恶意事件与正常事件在一些行为特征上存在着显著差异,如恶意行为倾向于使用更少的扩展,合法客户端的密钥长度比较短[57]等,如图2-1和图2-2。入侵检测旨在研究恶意行为与正常行为的区别,从而能从海量事件中识别攻击并采取主动防御反制措施。早期安全分析师采用人工分析的方法研究攻击事件的构成方式来检测入侵,然而攻击者的攻击手段不断强化形成了海量的攻击变体,人工分析已无法满足入侵检测的需求。随着AI赋能网络安全时代的来临,各种机器学习模型开始应用于入侵检测系统,如基于决策树的入侵检测[58],基于深度神经网络的入侵检测[59]和基于支持向量机的入侵检测[60]等。随着入侵检测模型的发展和完善,入侵检测技术的效果达到了一个瓶颈期,后续学者将提升入侵检测性能寄托于特征工程,如基于遗传算法优化的入侵检测[61]、基于粒子群算法优化的入侵检测[62]等。接下来将详细介绍几种常用的入侵检测模型和特征选择技术。
计算机论文怎么写
............................
2.2入侵检测模型
2.2.1基于决策树的入侵检测模型
决策树(Decision Tree)又称作判定树,它是数据挖掘领域里基于树形结构的一种决策分析方法[63],它的主要思想就是先构建一棵树形结构(可以是二叉树或者多叉树),这棵树上的每一个节点均能够代表一个特征,并且这棵树的每一个叶子结点都能够表示为一种分类结果。根据不同特征以及特征值的多种组合形式,决策树的分支可以把数据集划分成为很多不一样的子集合从而得到最终的分类结果。决策树的结构如图2-3所示。决策树的生成流程大致包含了三个步骤:1、选择具有显著分类能力的特征。2、结合信息增益算法使得决策树分枝从而生长。3、为了防止过拟合现象的出现还要对决策树进行剪枝。
随机森林(Random Forest)是基于大量决策树构建的集成树模型,随着随机森林中决策树数量的不断增加,随机森林的泛化误差收敛将会达到极限,最终达到更精准的分类或者回归效果[64]。随机森林算法具有准确率高以及泛化性能好的特点,并且它还降低了过拟合的风险。随机森林对海量高维数据集与特征之间的非线性关系具有很强的处理能力。
............................
第三章 基于改进LightGBM和强化K-means的双阶段入侵检测模型 ..................................... 21
3.1 改进的LightGBM模型 .......................... 21
3.2 强化的K-means模型 .................................. 23
第四章 基于弱耦合集成技术的多融合攻击分类模型 ........................ 33
4.1 MIM模型架构 ............................. 33
4.2 OUSD采样方法 ......................... 34
第五章 基于集成学习的入侵检测系统 ......................... 47
5.1 需求分析 ............................................ 47
5.2 系统总体设计 .................................. 51
第五章基于集成学习的入侵检测系统
5.1需求分析
5.1.1总体需求分析
随着互联网技术的发展和云计算、大数据等技术的普及,每天产生的网络事件是海量的,因而入侵检测系统需要能够实现快速响应对每条数据的监测。网络数据存在高维异构现象,所以数据预处理模块需要配合入侵检测和攻击分类模块实现数据解析和特征降维。随着网络攻击的日益复杂化产生了大量攻击的变体,基本的入侵检测模型无法适用于新型网络环境,因而系统需要能够实现数据存储和管理从而定期更新优化模型。
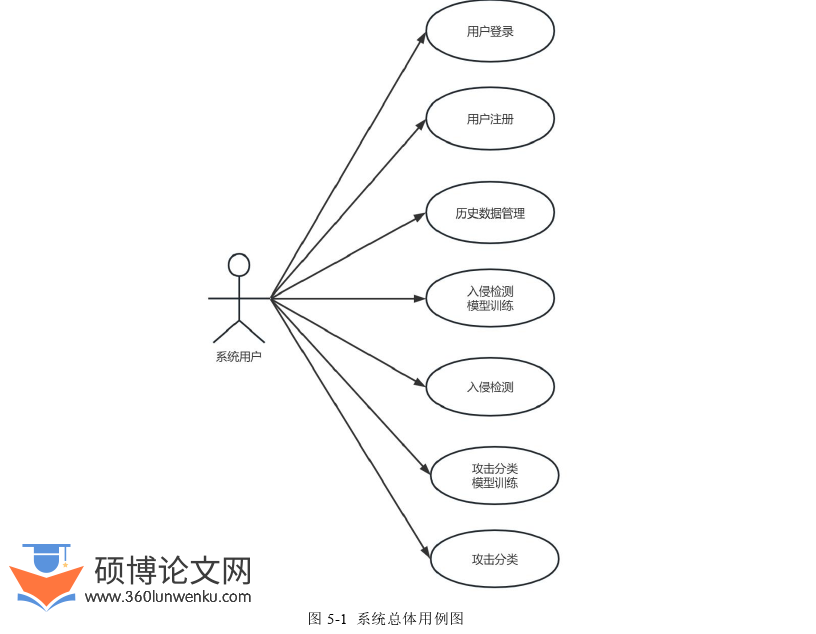
本系统以基于机器学习的入侵检测技术研究为基础,主要研究海量数据下入侵检测技术的可行性、有效性、适用性和迁移能力等,并实现用户管理、数据采集、历史数据管理、数据预处理、模型训练、入侵检测和攻击分类等任务。本系统结合所提出的基于改进LightGBM和强化K-means的双阶段入侵检测模型(STG2P)和针对样本不均衡场景下的多集成攻击分类模型(MIM),开发了基于集成学习的入侵检测系统。系统实现了实时监测网络流量数据以及系统终端日志数据,通过高并发响应以最快的检测速度识别存在的攻击事件,并将结果以友好的方式呈现给用户,能够为用户的网络安全防御工作提供导向作用。系统用例图如图5-1所示。系统主要包含用户注册、用户登录、历史数据管理、入侵检测模型训练、入侵检测、攻击分类模型训练、攻击分类等7个功能模块。
计算机论文参考
.........................
第六章总结与展望
6.1总结
随着信息技术的飞速发展以及网络系统的日益复杂化,每天产生数以千亿计的网络事件,而攻击行为隐蔽的潜藏其中。传统的入侵检测系统已无法从海量安全事件中精准的提取攻击行为并对攻击正确分类。网络中不同攻击行为与正常行为在数量上存在极度不均衡的现象也给基于AI的入侵检测带来了极大的挑战。网络流量和系统日志数据错综复杂、特征繁多,不均衡现象加剧了干扰特征对入侵检测和攻击分类模型的负面影响。不同的AI模型只擅长检测特定攻击,因而现有的单一入侵检测模型无法获得高检测率。针对上述问题,本文提出一种基于改进的LightGBM和强化的K-means模型集成的入侵检测方法(STG2P)和一种基于规则与优先级集成的多融合攻击分类方法(MIM),并基于这两个模型开发了一种基于集成学习的入侵检测系统。该入侵检测系统实现了流量和日志数据自动解析、数据结构化处理以及数据预处理,并实现了基于改进的模拟退火算法自动获取最佳网络流量特征以提升攻击分类的性能,最终完成入侵检测和攻击分类任务。本文的研究内容主要包括以下几个部分。
(1)总结并归纳了网络安全入侵检测领域当前面临的挑战以及需要克服的技术难题,并简单介绍了AI赋能网络安全背景下涌现出的大量智能入侵检测模型,如基于核极限学习机(KELM)的攻击检测模型以及基于自动编码器与深度神经网络相结合的攻击分类模型等。接着对本文的研究方法和研究内容进行了简要的概述,包括对所用到的技术进行了阐述。
(2)针对入侵检测任务本文提出了基于改进的LightGBM和强化的K-means模型集成的入侵检测方法(STG2P),模型训练阶段包括对数据进行解析和结构化处理,对LightGBM的输出结构进行改进,对K-means的超参数k值实现自适应确定以及对模型融合的数据流结构进行改进。在正式入侵检测阶段详细介绍了框架的工作机理包括双阶段异常事件检测流程,K-means的工作方式以及触发K-means自动更新优化超参数k值以检测新型攻击的方式。通过在LANL数据上的仿真实验验证了STG2P的高效性,入侵检测AUC值和检测速度均超过发表在《Workshops at the thirty-second AAAI conferenceon artificial intelligence》会议上的《Recurrent neural network language models for openvocabulary event-level cyber anomaly detection》论文中提出的方法。
参考文献(略)