本文是一篇计算机论文,本文基于机器学习算法,从web服务器和开源社区收集大量数据集进行研究,实现了较高的识别精度和识别效率,并基于此开发设计出一套恶意URL识别系统,可以部署于实际的生产环境中。
第一章 绪论
1.1课题研究背景及选题意义
随着计算机、智能手机与网络技术的不断进步和快速发展,许多网上业务走进了大众的生活,如社交网络、扫码支付、线上授课等,互联网在人们的生活中的占比愈来愈大,可以说在现在任何人离开了互联网在日常生活中将变得举步维艰。截至2022年6月,中国网民规模为10.51亿,互联网普及率为74.4%[1],各个公司和公立机构也将自己的服务推广到网络上来,实现了事务处理的高效性和透明性。
然而伴随着网络的发展与科学技术的进步,web开发的难度也随之降低,但由于部分web开发人员的安全意识不强,在编写程序的过程中出现了很多漏洞,容易泄露用户的数据与隐私,给使用者造成了很大的安全问题。如一些不法分子利用代码漏洞植入木马病毒,窃取用户隐私数据,从而实现诈骗等犯罪行为以谋取利益[2]。
目前一些研究者对于恶意URL的检测防范进行了研究,主要手段为基于黑名单过滤的识别方法和基于规则匹配的识别方法。这些方法原本的识别精度很高,然而面对互联网上层出不穷的新URL链接,其识别精度变得越来越差[3]。如今人工智能技术手段成熟,在网络安全方面应用广泛,研究者们利用经验在众多恶意网站中提取特征数据,使用机器学习算法对未知URL进行评估,然而人们对特征提取效率较低,人工成本较大[4],后来有了深度学习等算法,不需要人工提取特征,输入数据便可自动学习,成为当前网络安全方面主流的恶意URL识别方法[5]。现在人们使用互联网的主要途径是打开URL链接来访问目标网站,与此同时越来越多的网络安全问题也出现在我们身边,每一次对未知URL链接的点击访问都可能对计算机造成威胁,因此为了维护网络安全,解决对恶意URL的访问问题刻不容缓。
...............................
1.2国内外研究历史与现状
自上世纪以来,针对恶意URL的检测,人们发明出三种主流的检测手段。总体而言分别为:基于黑名单过滤的检测技术,基于动态行为的检测,以及基于机器学习的检测技术。
1.2.1 基于黑名单过滤的检测技术
基于黑名单过滤的检测技术是一种常见的网络安全技术,它可以通过使用预定义的黑名单列表来阻止或过滤掉恶意或不良的网络流量或内容[6]。黑名单列表通常由安全专家、网络管理员或其他安全机构维护,其中包含已知的恶意或不良的域名、IP地址、URL、文件哈希值等信息。当网络流量或内容与黑名单列表中的任何项目匹配时,系统将根据预定义的规则执行相应的操作,如组织访问、删除文件等。
然而,基于黑名单过滤的检测技术也有其局限性。黑名单列表可能存在漏洞或过时,无法有效防范新型的攻击和威胁。此外,黑名单过滤也容易产生误报或误拦截,对正常的网络流量或内容造成影响。因此,在实际应用中,基于黑名单过滤的检测技术通常与其他安全技术结合使用,如基于行为的检测技术、入侵检测系统等,以提高安全性和减少误报。
1.2.2 基于规则匹配的检测技术
基于规则匹配的检测技术指的是一种利用事先设定好的规则,对文本、图像、声音等数据进行匹配和识别的技术。这种技术通常用于检测特定类型的信息或行为,例如网络安全、垃圾邮件过滤、广告屏蔽等领域。该技术的实现基于以下几个步骤:首先,需要定义一组规则或模式,用于描述要检测的信息或行为的特征。这些规则通常由专家或经验丰富的人员制定,并经过多次实验和调整,以确保其准确性和可靠性。其次,需要将这些规则转化为计算机可以理解和处理的形式,例如正则表达式、语法分析器等。这些工具可以自动解析文本、图像、声音等数据,并按照规则进行匹配和识别。
................................
第二章 恶意URL攻防理论
2.1 URL与Web应用
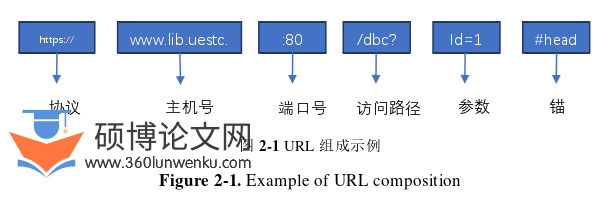
URL(Uniform Resource Locator,统一资源定位符)是一个由若干个标准格式组成的字符串,用于标识互联网上的资源(如网页、图像、音频、视频等)。它由多个部分组成,包括协议、主机名、路径等等,它们共同描述了互联网上的特定资源的位置和访问方式[24]。URL是Web应用程序的核心组成部分,它允许用户通过浏览器访问Internet上的各种资源。
Web应用程序是一种运行在Web浏览器中的应用程序,它使用Web技术(如HTML、CSS、JavaScript等)来提供各种在线服务。Web应用程序可以通过URL提供对不同资源的访问,例如网页、图片、音频、视频等等。Web应用程序通常由前端和后端两部分组成。前端通常包括用户界面和交互逻辑,而后端则处理数据存储、业务逻辑和服务端的网络通信。
Web应用程序的一大优点是它们具有跨平台性,可以在各种设备上运行,例如桌面计算机、移动设备、平板电脑等等。它们还具有易于更新和维护的特点,可以通过网络进行更新,而不需要安装或升级本地软件。
Web应用程序的发展已经极大地改变了我们的生活方式,例如在线购物、社交网络、电子邮件、在线银行等等。它们已经成为现代生活的必备工具,对个人、企业和社会都产生了重要影响。如图2-1所示,URL由以下六个主要部分组成:
计算机论文怎么写
.........................................
2.2 恶意URL主要攻击手段
人们在享受web互联网给生活带来便利的同时,也可能遭受到许多利用Web进行的网络攻击。本章接下来将主要介绍三种常见的URL攻击手段,例如SQL注入、XSS攻击和网站钓鱼等。
2.2.1 SQL注入
SQL注入是一种常见的网络攻击技术,它利用对Web应用程序输入的SQL查询字符串的不当过滤或验证机制,向应用程序的后台数据库注入恶意代码,从而实现非法访问、篡改或破坏数据库的目的[25]。SQL注入攻击可以对Web应用程序和数据库造成严重的安全威胁,导致机密信息泄露、业务中断、数据丢失等重大损失。
SQL注入攻击通常通过Web表单、URL参数、Cookie等方式向Web应用程序发送恶意SQL查询字符串。攻击者可以利用各种技术手段来构造恶意查询字符串,如拼接、嵌套查询、注释等,以绕过应用程序的输入验证和过滤机制,成功地执行恶意代码。
SQL注入攻击的危害性非常高,因为它可以绕过应用程序的访问控制和权限限制,直接对数据库进行操作[26]。攻击者可以通过SQL注入攻击获取敏感信息,例如用户名、密码、信用卡信息等,进而利用这些信息进行其他的攻击活动。此外,攻击者还可以利用SQL注入攻击破坏数据库的完整性和可用性,导致系统崩溃、数据丢失等灾难性后果。
............................
第三章 机器学习理论 ................................ 11
3.1 支持向量机 ................................. 11
3.2 决策树算法 ......................................... 12
3.3 集成学习 ....................................... 13
第四章 基于特征提取的恶意URL检测算法研究与实现 .................. 19
4.1 数据预处理 .................................... 19
4.2 算法模型仿真 .................................. 23
4.3 基于支持向量机的URL检测算法 ...................... 24
第五章 恶意URL检测系统的设计 ................................. 31
5.1 设计过程 ....................................... 31
5.2 数据载入与处理 ............................................. 32
第五章 恶意URL检测系统的设计
5.1设计过程
(1)需求分析阶段:通过训练得到一个能对未知URL链接进行正常或恶意判断的模型。
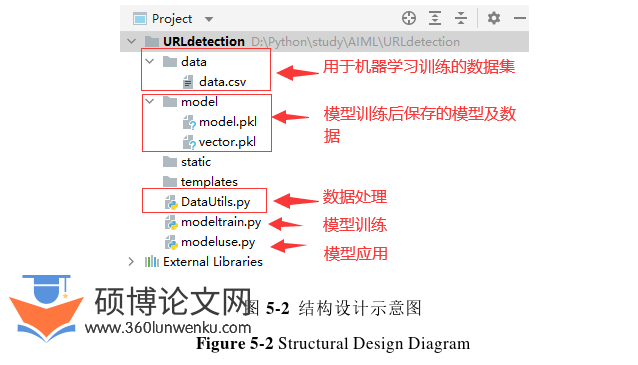
(2)结构设计阶段:data.csv为用于机器学习训练的数据集,model.pkl和vector.pkl为模型训练后保存的模型及数据,DataUtils.py为数据处理。
计算机论文参考
(3)实施阶段:先将数据集载入至Python中,将URL和标签进行识别和区分,再对URL进行向量化处理,然后进行模型训练,最后保存模型后用未进行训练的数据集进行效果测试。
..........................
结语
URL检测是Web安全领域中一项重要任务,对于预防和拦截网络攻击具有重要意义。本文对恶意URL检测领域相关研究现状进行了分析,从基于多种机器学习方法的角度出发,搭配两种特征提取方法,使用模型并提升训练精度,取得一定的成效,现在对本文所做工作总结如下:
(1)研究了正常URL在Web应用中的作用和运行原理,并分析了攻击者借助URL这一载体实施SQL注入、跨站脚本攻击和网站钓鱼等网络攻击手段的基本方式,为研究实施有效的URL检测技术提供了重要支撑。针对恶意URL检测领域中国内外研究者的主要工作进行总结和介绍,分析了现有检测技术的基本原理和主要优缺点,主要包括基于规则匹配的检测技术、基于黑名单的检测技术和基于机器学习的检测技术。
(2)在经验特征和TF-IDF统计特征提取的基础上,研究并实现了三种(SVM、决策树和随机森林)机器学习算法对URL的有效检测,根据实验筛选出准确率最高的搭配作为恶意URL检测系统的设计方式。
(3)根据第四章的实验结果,使用准确率最高的机器学习模型,设计并实现了一个恶意URL检测系统,能支持其他恶意信息识别算法的搭载,为后续多累恶意信息的全面挖掘提供强有力的支持,具有深远的工程意义。
参考文献(略)