本文是一篇计算机论文,本文提出一种基于主特征值比例和核目标对齐的多核学习算法,同时考虑基核函数在样本空间的表示能力和复杂度,提高了多核学习方法的性能。
第一章绪论
1.2研究背景与意义
核方法,如支持向量机(Support Vector Machine,SVM)[1]、最小二乘支持向量机[2]是一类重要的机器学习方法,已被成功应用到各种机器学习问题中。这些方法将数据点从输入空间隐式地映射到特征空间中。映射是由一个核函数隐式确定的,它计算特征空间中数据点的内积,并在特征空间中学习线性学习器。核函数的好坏直接影响核方法分类性能的优劣,如何选择核函数已成为了核方法研究的关键问题。一般情况下,核方法需要用户先确定核函数的类型,如线性核函数或多项式核函数,并通过优化核函数的质量函数来确定核参数。质量函数的选取非常重要,常见的包括交叉验证[3]、泛化误差界[4]和核对齐[5]等。
虽然单核方法在许多应用领域都表现出很好的效果和实用性,但它们都是基于单个特征空间的。不同的核函数对应于不同的特征空间,因此核函数在不同的应用场景下的性能表现差异很大。当样本的特征包含异构信息、数据规模大、数据分布不平衡或者数据不规则时[6],使用单个核函数对所有样本进行映射的方法并不可靠。而且,传统的单个核函数只有浅层结构,因此表达能力较为有限。为了解决这些问题,近年来研究人员对多核学习方法(Multiple Kernel Learning,MKL)展开了大量的研究[7]。
多核学习模型相较于单核方法更加灵活。研究表明,多核函数能够增强决策函数的可解释性,并且能够获得比单核模型更优的性能[8]。通常,构造多核模型的最常用方法是实现多个基核函数的凸组合。因此,在多核学习框架内,需要解决的问题由原来的基核函数的选择,转化为了确定基核函数的组合系数,且已发展出多种不同的多核学习方法[9],如基于无限内核集的多核学习方法[10]、基于L1和L2正则化的学习方法[11]、半无限线性规划的多核学习方法[12]和基于正则化路径的多核学习算法[13]等。
........................
1.3国内外研究现状
1.3.1多核学习研究现状
核函数可以将样本从原始特征空间映射到高维再生核希尔伯特空间(ReproducingKernel Hilbert Space,RKHS),使在原始特征空间线性不可分的样本变的线性可分[19]。然而,对于不同的数据,核函数的选择会对结果产生很大的影响,因为不同的核函数具有不同的表示能力。单个核函数从复杂数据中提取特征的能力较弱,在实际应用中无法处理复杂的应用程序。多核学习方法是核方法的扩展,与单核方法只学习单个核函数不同的是,多核学习遵循不同的方式学习一组基本核函数的组合系数,并将基核融合为一个复合内核来进行学习[20]。在多核学习方法中使用了多种潜在的特征映射,增加了映射的多样性并提高了模型的表达能力[21]。除此之外,多核学习方法的基核函数可以是不同特征表达的输入,使多核学习可以进行特征选择和多信息融合,提高了多核方法学习数据特征的能力。
在过去的几年中,多核学习得到了积极的研究,许多扩展的多核学习技术被提出来改进常规的多核学习方法,例如本地化MKL[22]实现了内核权重的局部分配;函数逼近MKL[23]使用函数逼近技术寻找最优核;多经验核学习[24]将数据点从输入空间显示映射到经验特征空间,其中映射的特征向量可以显式表示;两阶段MKL[25]根据一定的准则学习最优核权重,然后应用所学的最优核训练核分类器。除此之外,研究人员还针对多核学习存在的核选择、权重选择和模型优化等问题对多核学习进行了改进。
...............................
第二章基于神经正切核的多核学习算法
2.1实验与分析
本小节将通过3个实验来验证NTK的性能,第一个实验是有限宽神经网络与NTK对比实验,用来验证有限宽神经网络所产生的NTK是否跟其有着相似的性能;第二个实验是NTK与传统核函数的对比实验,用于验证NTK相较于传统的核函数是否有着更好的性能和表示能力;第三个实验是基于NTK-MKL的多核学习算法与AverageMKL算法的对比实验,为了验证使用神经正切核替代传统核函数作为基核,是否可以提高多核学习算法的性能。
2.4.2实验数据集
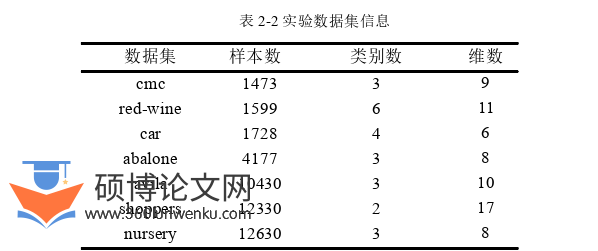
本节实验总共采用7个UCI数据集(http://archive.ics.uci.edu/ml/index.php)来验证模型的性能,其中包括鲍鱼数据集(abalone)、避孕方法选择数据集(cmc)、汽车评估数据集(car)、红酒质量数据集(red-wine)、网上购物者购买意图数据集(shoppers)、阿维拉(avila)数据集、和苗圃数据集(nursery),数据集的详细信息如表2-2所示。
计算机论文参考
虽然UCI数据集是标准数据集,但是其原始数据中仍然存在一些格式上的问题,无法在程序中直接使用,需要对其进行相应的处理。如car数据集中的low、med、high和vhigh等属性值,字符型离散型数据,需要将其根据某种规则转换为数值型数据。因此,本文在[-1,1]区间内平均取n个实数进行替换,n为字符型属性个数。那么low、med、high和vhigh这四个属性值,根据规则被转换为-1、-0.5、0.5和1。此外,abalone数据集的“Sex”列的值为‘M’、‘F’和‘I’是字符串数据,分类模型无法直接学习,需要将字符串类数据转换成数值型数据,为方便分类,将‘M’、‘F’和‘I’分别转换为0,1,2。
...............................
2.5本章小结
本章首先对多核学习常用的基核函数和常见的多核学习算法进行了介绍;然后对无限宽神经正切核的理论和其在无限宽限制下不随时间变化,以及神经网络与NTK核回归具有等价性这两条特性进行了研究;接着对有限宽神经网络的递归计算进行了描述;最后将NTK核函数与有限宽神经网络和传统核函数,分别在不同的UCI数据集上进行对比实验,并将本章提出的NTK-MKL与AverageMKL算法在不同数据集上进行对比实验,来验证NTK核函数的性能以及将NTK应用到多核学习算法中能否提高其性能。实验结果表明,在avila数据集上有限宽神经网络与其对应结构的NTK核有着相似的性能,特别是在神经网络的宽度为1024的时候,二者的误差曲线几乎重合,说明了在有限宽神经网络中也存在着与无限宽神经网络相同的现象。同时,在car数据集、abalone数据集和shoppers数据集上随机生成的NTK的准确率都要比传统的核函数要高,说明了NTK核函数相较于传统核函数在不同规模的数据集上有着更好的性能。NTK核函数的精确率和召回率在3个数据集上也要比传统核函数要高,尤其是在car数据集和abalone数据集上,这也进一步说明了NTK核函数相较于传统核函数有着更好的表示能力。此外,NTK-MKL算法在nursery数据集、cmc数据集和red-wine数据集的准确率都要比AverageMKL算法要高,说明了使用神经正切核替代传统核函数作为多学习的基核函数可以有效的提升多核学习的表现。综合上面的结果,充分说明了NTK核函数相较于传统核函数有着更好的性能和表示能力,可以将其作为多核学习方法的基核函数,来提高多核学习方法的性能。
计算机论文怎么写
..............................
第三章 基于主特征值比例和核对齐的基核权重计算方法 ................ 23
3.1 主特征值比例 ............................. 23
3.2 核目标对齐 .............................. 24
3.3 基于PK-MKL的多核学习算法 ........................ 25
第四章 基于NTKSketch的近似多核学习算法 ...................... 31
4.1 NTKSKETCH算法 ...................... 31
4.1.1 反余弦核随机特征 ............................... 31
4.1.2 张量草图变换 .................................. 32
第五章 基于NS-MKL算法的油井压裂增油效果预测 ....................... 43
5.1 数据来源与影响因素概述 ............................ 43
5.2 数据预处理 ....................................... 43
5.3 压裂影响因素分析 ........................... 45
第五章基于NS-MKL算法的油井压裂增油效果预测
5.1数据来源与影响因素概述
选取了大庆油田多个工厂近10年来井区的生产资料,作为油井压裂的历史数据,并利用这些信息,预测对应区块内油井采取压裂措施后的日增油量效果。
油井压裂是一个复杂的工艺措施,会受到多种因素的影响。为保证预测模型在不同场景下的准确性和鲁棒性,选择易获取、可量化和标准化的影响因素非常重要。通过这样做,可以提高油井压裂增油效果预测的精度。通常用于预测油井压裂增油效果的影响因素可分为四大类:区块及单井基础信息、地质静态数据、生产动态数据和措施效果及工艺数据。此外,与测试数据相关的参数也是需要考虑的重要影响因素。下面详细描述了各个类别的影响因素:
1.区块及单井基础信息反映了待测压裂井的区块和井层信息,主要包括井号、区块单元、区块地层压力、区块年均含水和饱和压力等。
2.地质静态数据包括砂岩厚度、有效厚度、渗透率、孔隙度和油层组名称等,这些参数有助于表征待测油井的储层和周围地质构造信息。
3.生产动态数据反应了待测油井的生产效率和生产质量,包含生产天数、累积注水量、沉没度、累积产油量、累积产水量和累积产气量等。
4.措施效果及工艺数据包括累增油、有效期、压裂液类型、措施层段、施工日期、完工日期和压裂类型等,其中压裂液的类型会影响压裂作业的效率和生产率,施工日期等时间数据反映了压裂作业开始时间和持续时间等信息,为优化压裂作业效率提供参考。
5.测试数据是了解待测油井行为和特性的重要信息来源,可为优化生产和增产作业提供指导,主要有层位、井段顶深、井段底深、注入量和表皮系数等。
.........................
结论
多核学习方法是核学习中以为重要的方法,然而,针对大多数的多核学习方法仍存在以下问题:1)多核学习方法基核函数多选用浅层结构的核函数,它在数据规模大、分布不均等情况下,表示能力不足;2)在大规模数据上进行训练,核矩阵的计算复杂度非常高;3)大部分的多核学习基核权重的度量考虑过于单一。因此,本文对提升多核学习方法在大规模数据上的性能和计算效率进行研究。本文主要取得的研究成果如下:
(1)本文基于神经正切核提出一种新的多核学习算法,提高了多核学习方法的表示能力。在7个UCI数据集中进行多个对比实验,实验结果表明,在NTK与有限宽神经网络性能对比实验中,当隐藏层神经元个数为1024时,NTK与有限宽神经网络有着相似的性能;在NTK与传统核函数对比实验中,NTK核在的准确率、召回率和精确率在3个UCI数据集中均比传统核要高;在NTK-MKL算法与AverageMKL算法对比实验中,NTK-MKL算法在2个UCI数据集上的准确率均比AverageMKL算法要高,尤其是在cmc数据集中,高了7个百分点左右。
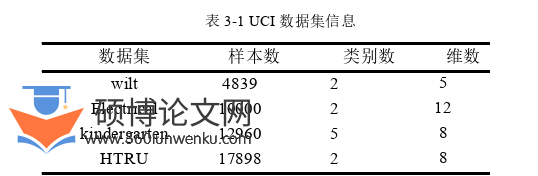
(2)本文提出一种基于主特征值比例和核目标对齐的多核学习算法,同时考虑基核函数在样本空间的表示能力和复杂度,提高了多核学习方法的性能。在4个UCI数据集上进行了两个对比实验,通过实验结果可以知道,在不同PK值性能对比实验中,核函数的PK值越大,那么其的分类准确率就越高;在PK-MKL算法与NTK-MKL算法的对比实验中,PK-MKL算法的分类准确率在2个UCI数据集上均比NTK-MKL算法要高,尤其是在kindergarten数据上的准确率高达99.6%,且比NTK-MKL算法的准确率高2个百分点。
(3)本文基于NTK草图算法提出了一种新的多核学习算法NS-MKL,提升了多核学习在大规模数据集上的计算效率。在4个UCI数据集上进行了性能对比实验,由对比实验结果可知,在NTK与近似NTK对实验中,近似NTK的挂钟时间在2个数据集上都比原始NTK要短,尤其是在bank数据集上近似NTK的挂钟时间比原始NTK提升了3倍,且相较于原始NTK准确率仅损失了1.5个百分点;在多核学习算法性能对比实验中,NS-MKL算法的挂钟时间远小于其余4个多核学习算法,仅为46s,且相较于PK-MKL算法准确率仅小了1.3个百分点。
参考文献(略)