第 1 章 引言
1.1 研究背景和意义
认知是指人类大脑接触外界信息或者事物后,通过内心活动的加工和处理,转化为我们学习到的知识,即我们学习新事物、获取知识,并对学到的知识进行应用的一种能力。认知功能包括记忆力、理解力、计算力、语言能力、视觉空间能力、判断能力等,如果认知功能出现以上一个方面或者几个方面的受损,可以被认为是认知功能障碍。如果不加以预防和干预,易从轻度认知障碍(mild cognitive impairment, MCI)恶化为阿尔茨海默病(Alzheimer disease, AD, 别名:老年痴呆)。MCI 是介于认知正常和老年痴呆的一种中间状态,MCI 患者存在某个或某些认知能力受损,但整体情况尚未影响到日常生活能力,未达到确诊痴呆的标准(周媛媛等, 2018)。老年痴呆不是正常衰老过程所导致的精神疾病,而是一种不可逆的大脑功能障碍,一旦患病就无法逆转,只能尽力延缓病情(赵晋萱等, 2020) 。
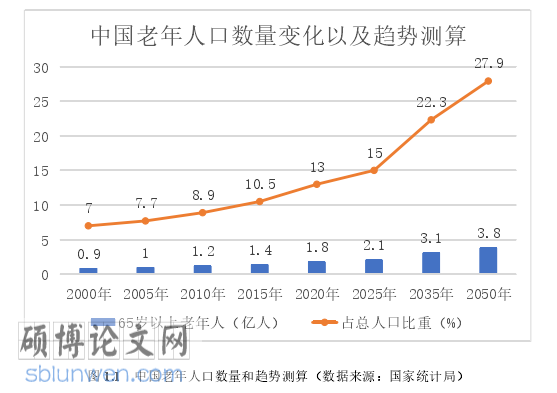
我国从 2000 年左右开始进入老龄化社会,中国发展基金会发布的《中国发展报告 2020:中国人口老龄化的发展趋势和政策》中指出,到 2022 年左右,我国 65 岁以上的老年人口将占到总人口的 14%,预计到 2050 年我国 65 岁以上老年人口比重将达到 27.9%,中国老龄化将达到峰值,中国老年人口数据变化及趋势如图 1.1 所示。随着人口老龄化问题的加剧,将会有越来越多的老年人面临认知功能下降或损害问题。认知功能下降或障碍不仅影响生活能力,也会影响到社交能力(曹颖等,2019)。
计算机软件论文怎么写
1.2 国内外研究现状
认知量表评估与数据管理系统主要有医疗器械公司的产品、互联网产品以及其他研究者开发的系统。医疗器械公司的产品大多数需要花费上万元购买整套系统,而且可能存在数据泄漏隐患(Arevalo‐Rodriguez I 等,2015)。互联网产品主要针对的形式是问卷,并非针对神经心理学量表这个垂直领域。其他研究者开发的系统,并不对外开放,同时也具有局限性。随着数据时代的来临,数据为各行各业起着支撑作用。在医疗领域也不例外,其产生的数据多、维度高、利用率低等特点,很多研究者也开始利用数据分析、数据挖掘的算法来探究数据间的关系(Kalantari A 等,2018)。因此,下面将针对认知量表的评估与数据管理系统和基于神经心理学量表数据的数据挖掘技术应用进行国内外现状分析。
1.2.1 基于量表数据的认知能力评估模型的国内外研究现状
(1)国内
针对老年人群体的认知能力分类,比较典型的是利用神经心理学量表进行评分,结合量表的不同分数范围,判断出该老人的认知能力属于哪种类型。这种仅靠总分进行判断的方式并不准确,姜志强等(2018)联合 3 个量表收集的数据,利用支持向量机算法对 MCI 进行检测和分类,最终结论得出模型可以较好地分类,准确率为 93%。刘玥等(2015)利用马尔科夫聚类算法分析中风后认知障碍的常见症型,建立了中风后常见症型的评估模型,其准确度在 86.8%至 96.6%之间。
(2)国外
对于数据挖掘算法在认知功能上的研究和应用,国外的研究者利用数据挖掘算法研究构建预测和检测 MCI或 AD的模型、构建 MCI阶段性的分类模型、利用机器学习可以检测帕金森病患者是否存在 MCI 等等。美国南密西西比大学Pai-Yi 等(2019)使用机器学习技术开发了一个简短的问卷,以帮助神经学家和神经心理学家筛选 MCI 和 AD。里约热内卢大学的研究者 Barreto M L 等(2018)利用 605 份认知障碍患者的医疗记录,在文本挖掘过程中创建一个新的结构化数据集,应用贝叶斯信念网络和决策树算法和构建了 AD 和 MCI 的预测模型。
.......................
第 2 章 相关理论基础
2.1 认知功能障碍与痴呆症
2.1.1 认知功能障碍
认知功能包括记忆力、思考能力、定向力、理解力、计算力、语言能力、视觉空间能力、判断能力等,当其中一项或一项以上受损时可以称为“认知功能障碍”(Petersen R C 等,2016)。受损程度较轻时可以称为“轻度认知障碍”(mild cognitive impairment, MCI),MCI 也属于痴呆症的一种类型。
2.1.2 痴呆症
痴呆症(Dementia)是一种脑部疾病。通常情况下,痴呆症患者的认知功能会比正常衰老人群的认知功能下降更严重(Arvanitakis Z 等,2019)。它会影响记忆、理解、语言等认知能力,并影响个人日常生活能力和增加照顾者的压力。痴呆症的体征和症状大致可以分为 3 个阶段。早期阶段主要表现为忘事、在熟悉的路上迷路;中期阶段主要表现为忘记最近的事和人名、迷路、沟通起来变得困难以及精神恍惚等;晚期表现为几乎完全需要他人看管照顾、无法辨认亲戚朋友以及出现严重的记忆障碍(Bessey L J 等,2019)。
痴呆症存在很多种类型。最常见痴呆症是阿尔茨海默病,占到痴呆症的60%~70%左右。其他的类型有血管性痴呆、路易体痴呆以及前额叶形痴呆症等,按成因分类的痴呆症如图 2.1 所示。不同痴呆症之间的界限并不明显,也存在混合型痴呆(Paraskevaidi M 等,2018)。
全世界大概有 5000 万痴呆症患者,据估计,60 岁以上人口中有 5%~8%患有痴呆症。目前并没有能够治愈痴呆症的药物或医学方法,很多方法处于研究或临床阶段,但是仍然要尽力提高人们对预防痴呆症的意识和对痴呆症知识的普及(Ebert A R 等,2019)。
.......................
2.2 数据挖掘技术与应用
2.2.1 数据挖掘的发展历程
数据挖掘起始于 20 世纪 50 年代左右,是一门跨多学科的技术,是包括统计学、机器学习、数据库、程序编程等知识的综合应用技术,数据挖掘技术与其他学科的关系如图 2.2 所示。随着数据库技术的发展,数据的存储变得便捷,但是随之带来的是数据的不断积累(Lazli L 等,2020)。对于企业来说,简单的查询和统计已经无法满足商业需求,急需从激增的、复杂的数据中找到有价值的信息。
此时机器学习技术也取得了较大的进展,于是人们把数据库存储技术和计算机算法分析技术结合起来,探究数据背后的潜在意义。久而久之,“从数据库中发现知识”(Knowledge Discovery in Databases,KDD)这种理念变得流行。
KDD 这个术语最早提出是在 1989 年召开的第 11 届国际人工智能联合会议上。在 Jiawei Han 和 Micheline Kamber 的教科书《Data Mining: Concepts and Techniques》中将 KDD 的过程总结为 7 个步骤,即数据清理、数据集成、数据选择、数据转换、数据挖掘、模式评估以及知识展示(Gómez-Jiménez G 等,2018)。从这 7 个步骤可以看出,数据挖掘包含在 KDD 之中,并且是比较重要的分部,KDD 与数据挖掘的关系如图 2.3 所示。迄今为止,数据挖掘技术得到了较大的发展。聚类算法中的 K-Means 算法由 James MacQueen 在 1967 年提出,关联规则算法是 IBM 的 R.Agrawal 在 1993 年提出的(Sinaga K P 等,2020)。后续有很多学者对算法进行改进并应用到生活中的不同领域。
............................
第 3 章 基于认知量表的评估与数据管理系统的设计与开发 ..........27
3.1 系统需求分析 ............................................. 27
3.1.1 业务描述 ............................................. 27
3.1.2 业务流程分析 .................................... 29
第 4 章 认知能力评估模型的数据收集和预处理 ..............................53
4.1 模型构建目标 ........................................ 53
4.2 分析方法与过程说明 ................................. 54
4.3 数据收集 ........................................ 56
第 5 章 认知能力评估模型构建和结果分析 .....................67
5.1 基于不同认知能力的老年人聚类 ................................... 67
5.2 认知能力聚类结果分析 .................................... 71
5.3 探究个人情况与认知功能的相关性 .......................... 74
第 5 章 认知能力评估模型构建和结果分析
5.1 基于不同认知能力的老年人聚类
K-Means 算法是在数据集中分析出给定 K 个簇的聚类算法,可根据业务需求、经验来人为的给定或者使用一些方法来得出 K 值。通过计算找到最优 K 值的方法有 SSE(The sum of squares due to error,误差平方和)、轮廓系数法(Silhouette Coefficient)、CH 系数法(Calinski-Harabasz Index)等等。
本文中采用 SSE 方法和轮廓系数法来分析 K 的取值来找到最优的 K 值。SSE 方法的原理是在给定了不同 K 值之后,计算每个簇内的点到该聚类中心点距离的误差平方和。理论上 SSE 的值越小说明聚类结果越好,一般 SSE 的值会趋向于一个最小值。虽然增加簇的数量可以减少 SSE 的值,但这违背了聚类算法的目的,聚类的目标是在保持簇数目不变的情况下提高簇的质量。轮廓系数法的原理是给定一个 i 点,计算向量 i 到 i 所在簇内其他点的距离,记为 A(i),计算向量 i 到其他簇(不包括本身所在的簇)内所有点的平均距离,记为 B(i),如公式(5.1)所示:

计算机软件论文参考
第 6 章 总结与展望
6.1 总结
本文从我国进入人口老龄化阶段患认知障碍人数增多、大多数人不够重视认知障碍的社会背景出发,开展对老年人群体的认知功能和能力强弱的相关研究。分析了老年人各项认知能力的优弱势,探究了个人因素对认知功能的影响,以及开发了一套应用系统来方便认知筛查工作的顺利进行。论文取得的主要工作和阶段性成果如下:
1. 设计并实现了认知能力评估和数据管理的应用系统:将常用的神经心理量表抽象成各类题型,设计成评估系统,同时可以自由组合量表,方便进行认知评估和数据的管理。
2. 研究了老年人群的认知能力强弱:利用所收集到的数据,使用数据挖掘算法构建认知能力模型,分析出各项认知能力优势、弱势,针对优弱势提出训练认知能力的日常使用方法。
3. 探究了个人因素和认知能力的影响:个人情况往往也是影响认知能力的因素之一,本文探究了受教育年数和年龄对认知的影响,发现了受教育年数与整体的认知能力成正向相关关系,与定向力、注意力和计算力等认知能力成正向相关关系。
参考文献(略)