本文是一篇软件工程论文,笔者认为当今时代,在建设教育强国背景下,深入探究并有效利用知识追踪技术,能够精准诊断学生对知识的掌握情况,从而显著提升教育教学质量。这不仅对我国教育行业的实践具有不可估量的价值,更将在推动教育创新、培养高素质人才以及实现教育公平等方面发挥关键作用。
1 绪论
1.1 研究背景及意义
2025年,中共中央、国务院印发了《教育强国建设规划纲要(2024-2035年)》[1],要求坚持教育优先发展,加快建设高质量教育体系,为建设社会主义现代化强国、全面推进中华民族伟大复兴提供有力支撑。教育作为民族振兴与社会进步的关键基石[2],其发展改革从未止步。互联网时代开启后,传统教育历经多次变革,在线教育由此崛起,成为当代教育不可或缺的一部分。根据中国互联网络信息中心发布的第51次《中国互联网络发展状况统计报告》,在线教育在农村地区的普及进程显著提速,农村网民中使用在线教育服务的比例达到了31.8%[3]。如今,各类在线学习平台如雨后春笋般涌现,广泛应用于各类教育场景,吸引了海量学习者注册使用。
在线教育消除了传统教育的诸多障碍,例如突破了传统课堂时间和空间上的限制,学习者可随时随地通过移动设备或电脑接入课程,自主安排学习进度,尤其适合在职人员、偏远地区学生及碎片化时间管理。在线教育具有丰富的优质课程资源,拓宽了教育受众群体[4] [5]。依据联合国发布的《2022 年可持续发展目标报告》,在线教育为受冲突影响的近百万学生提供了远程学习机会,确保了教育活动的持续性[6]。基于深度学习、大数据和人工智能等技术,在线教育相比传统教育具有资源丰富性、可及性和更高效的处理速度。这使得在线教育相比传统教育的优势更为突出,并且逐步向智能化发展。
.........................
1.2 国内外研究现状
在当今数字化的时代背景下,教育领域正经历着一场由技术驱动的深刻变革。随着互联网的普及和智能设备的广泛应用,在线教育平台如MOOCs(大规模开放在线课程)和智能辅导系统(Intelligent Tutoring System,ITS)等应运而生,为学习者提供了前所未有的学习机会[9]。这些平台不仅突破了传统教育的时空限制,使优质教育资源得以广泛传播,还通过积累海量的学习行为数据,为教育研究者提供了深入探索学习过程的宝贵素材。在这样的时代浪潮下,知识追踪技术作为智能教育领域的核心研究方向之一[10],正吸引着越来越多研究者投身其中,致力于通过精准建模学生的学习过程[8],实现真正意义上的个性化教育,推动教育事业迈向新的高峰。
知识追踪技术主要分为两大类:基于传统方法和基于深度学习的方法。传统方法通常基于概率图模型,如贝叶斯知识追踪(Bayesian Knowledge Tracing ,BKT),它将学生对知识点的掌握状态建模为一组二元变量,并利用隐马尔可夫模型(Hidden Markov Model,HMM)来维护这些变量,以预测学生对后续问题的作答表现。这种方法简单且有效,但存在一些局限性,例如假设学生对知识点的掌握是二元的(掌握或未掌握),忽略了中间状态。深度学习方法则利用复杂的神经网络结构,如循环神经网络(Recurrent Neural Network,RNN)、长短期记忆网络(Long Short-Term Memory ,LSTM)、记忆网络(Memory Network)和自注意力机制(Self-Attention Mechanism)等,能够捕捉学生知识状态变化的更细微模式,从而实现更精准的预测。
......................
2 相关理论及技术介绍
2.1 知识追踪
2.1.1 贝叶斯知识追踪
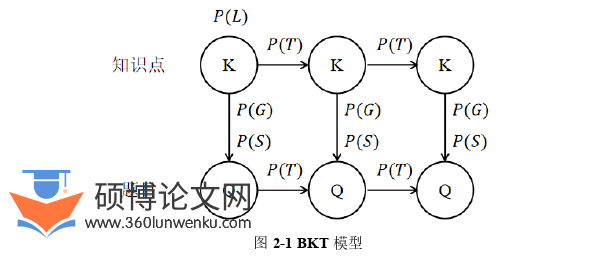
如图2-1所示,贝叶斯知识追踪是一种基于概率图模型的经典方法[11],广泛应用于智能教育系统对学生知识掌握状态的动态建模。该模型将学生的知识状态定义为隐变量(掌握或未掌握),通过观测其历史答题结果(正确/错误),利用贝叶斯定理迭代更新对知识状态的推断。其核心参数包括初始掌握概率????(????)、学习概率????(????)、猜测概率????(????)和失误概率????(????),分别表征学生初始水平、知识转化效率以及答题行为的随机性。模型通过期望最大化算法从数据中学习参数,并依据每次答题结果动态调整掌握概率:若答题正确,则结合猜测概率修正对掌握状态的置信度;若答题错误,则结合失误概率降低评估值,同时考虑学习概率驱动的状态转移(未掌握→掌握)。BKT因其计算高效、可解释性强等优势,被广泛应用于自适应学习、认知诊断等场景,但其局限性在于固定参数假设忽略了个体差异和题目特征,且未建模遗忘效应与多知识点关联。
软件工程论文怎么写
......................
2.2 注意力机制
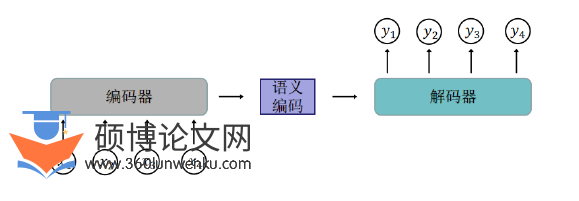
注意力机制是作为仿生计算的重要突破,其核心在于模拟人类信息处理的资源分配特性,通过建立动态权重分配模型实现关键信息萃取[31]。该技术最早在2014年神经机器翻译系统中取得突破性进展,成功解决了长距离语义依赖的建模难题[32]。在知识追踪领域,Pandey[33]等人开创性地将该机制应用于学习分析场景,提出基于注意力框架的知识追踪模型。该模型通过构建历史学习事件与目标问题的关联映射矩阵,采用键值匹配算法计算认知资源分配权重,从而提取出对学生当前答题预测最为关键的内容,最终通过这些进行预测任务。图2-3所示的编码器-解码器(Encoder-Decoder)架构展示了注意力机制的核心运算流程。
软件工程论文参考
..........................
3 辅助任务增强的对比学习知识追踪模型 ............................. 15
3.1 问题描述及定义 ............................................. 15
3.2 AT-CLKT模型结构............................................ 16
4 同伴记录增强的对比学习知识追踪模型 ............................. 29
4.1 问题描述及定义 ............................................. 30
4.2 PR-CLKT模型结构............................................ 31
5 总结与展望 ............................ 42
5.1 总结 ................................ 42
5.2 研究展望 ............................ 42
4 同伴记录增强的对比学习知识追踪模型
4.1 问题描述及定义
在本节中,本文将简要介绍知识追踪任务以及本章使用的符号。假设一个学生记为????使用在线学习平台来回答问题。本文将????的问答记录定义为:
定义1(问答记录):给定一个学生????,其交互序列为(????1????,????2????,…,????????????),其在时间的交互是 ????????????。????????????是一个三元组,????????????={????????,????????,????????}。????????代表她在时间回答的问题。????????表示与????????相关的概念集。 ????????={????????}|????????|和 |????????|≥1 , ????????表示????????中概念的 ID。 ????????表示学生对????????回答的正确性,0表示错误,1表示正确。
软件工程论文参考
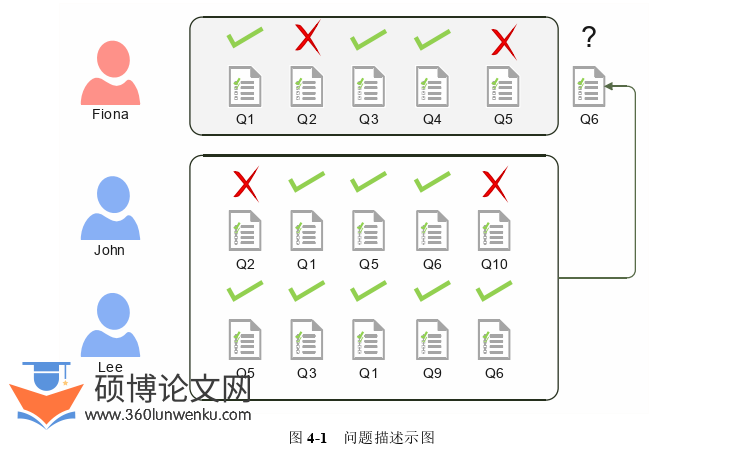
在在线学习场景中,特定学习者????的评估可借助群体认知特征进行优化。对于学生????,还有很多其他学生与????有类似的答题经历,这为估计????正确回答问题的概率提供了线索。如图4-1所示,显示了相似学生对评估目标学生的作用。现有的方法主要依据Fiona个人的历史作答记录(如图4-1上部所示) 来推断其知识水平,进而估算她正确回答Q6的可能性。但是,在线学习平台中有很多学生有与Fiona相似的练习回答经历。以Q6为例,学习者John和Lee不仅完成该题测试,其历史作答模式与Fiona呈现高度相似性。这些学生可被视为与Fiona相似的学习者。本文能够从他们的学习历程中,明确地获取他们在回答类似问题上的作答情况。这些信息可作为评估Fiona知识水平的群体认知特征,是对Fiona个人知识状态的有益补充,有助于更准确地预测她在练习Q6上的作答表现。
.........................
5 总结与展望
5.1 总结
知识追踪的实际应用中,需要构建表征能力强的模型对学习者的长期学习过程动态建模。
针对现有知识追踪模型面临的数据稀疏性问题,提出了一个辅助任务增强的对比学习知识追踪模型(auxiliary task enhanced contrastive learning knowledge tracing model,AT-CLKT)。在对比学习框架中,提出了几种用于知识追踪这一特定领域的数据增强方法,增强模型对学习者特征的提取能力。在辅助任务中,通过预测题目是否包含特定知识点来帮助模型学习更好的题目表示。在三个领域基准数据集上开展的实验结果充分证明,该模型在预测性能方面表现卓越,优于其他方法。消融研究进一步验证了模型中各个组件的有效性,包括数据增强方法和辅助任务。同时,该模型在表征能力上也展现出显著优势,能够更全面、精准地捕捉数据特征。这些发现证实了所提模型在处理教育数据稀疏性问题和提升个性化教学效果方面的潜力。这些优势使得该模型在实际应用中具有更强的适应性和竞争力,为相关领域的研究和实践提供了有力支持。
另一方面,本文受到教育心理学家班杜拉的自我效能理论启发,针对当前研究存在相似学习者的练习记录中蕴含的丰富群体认知特征信息没有被有效利用起来,对相似学生的知识状态和在相同问题上的作答表现这种信息存在讨论不足和利用不充分的问题,提出一种同伴记录增强的对比学习知识追踪模型(peer-record enhanced contrastive learning knowledge tracing model,PR-CLKT)模型。通过检索机制和相似度得分的计算得到相似的同伴记录,将同伴记录作为正样本输入到对比学习框架中,刺激模型学习有效的表示。最后,利用向量点积的方式模拟学生知识状态与题目之间的交互输出预测结果。在多个数据集上进行的对比实验与消融实验结果清晰地揭示了PR-CLKT模型的卓越之处。它不仅在预测准确率上超越了其他模型,而且通过细致的实验分析充分展现了其架构的独特之处。
参考文献(略)