本文是一篇软件工程论文,本文构建了一个由Transformer和CNN方法相结合的轻量级图像超分网络FTCN(Fusion of Transformer and CNN Network)。首先,提出了一个基于Swin Transformer的轻量化GFE模块,利用滑动窗口多头自注意力计算的长程依赖性实现对特征全局的提取能力。
第一章 绪论
1.1 研究工作的背景与意义
图像作为物体的视觉表现形式,承载着广泛而丰富的内容,是人们获取信息来源的主要载体之一。随着电子科学技术的发展,图像更多地以数字形式存储,数字图像可以通过多种物理设备和技术手段来进行采集,包括数字影像器件、电子扫描仪、天文望远镜等。采集得到的数字图像以标准的数据格式得以更好地在电子设备上进行存储、传输和处理。
然而数字图像的采集以及传输的过程并不是理想化的,真实环境中图像的采集往往会受到现实条件的制约以及硬件设备的性能瓶颈导致在一些情况下无法获取高质量的图像。例如在高温气候中由于地表受热地面空气攀升而引起空气媒介不均一而造成的透光度的改变,使得即使相机对焦成功拍摄出的图像也依然会变得模糊;大气运动及空气密度的变化会导致视宁度的下降,使得用天文望远镜捕捉到的深空图像产生扭曲和失真。在图像的传输过程中由于网络通信环境的不稳定和周围介质的干扰也有可能产生噪音与数据损耗,导致传输后的图像缺少部分关键信息而缺少有效细节。此外,将图片传输到社交媒体应用的过程中,平台对图像的处理也会引入图像压缩技术和不可预测的噪音,使得下载之后的图片和原始图片相比分辨率低,丢失了部分高频细节。
低分辨率(Low Resolution,LR)、模糊不清晰的图像不仅无法给人带来愉悦的视觉体验,同时也导致在进行数字图像处理任务时无法有效地获取到关键信息从而严重影响计算机视觉领域诸如检测、分割等下游任务的精度。最直观的提高图像分辨率的方式是通过硬件手段来实现,该方法主要是通过提升设备的感光芯片(CCD, CMOS)的性能来提高图像的分辨率[1]。受限于芯片的规格以及生产工艺的成本,想通过优化成像单元的整体参数(像元尺寸、信噪比、像素)来提升分辨率的方式实施难度高,投入周期大,在实际应用中性价比不高[2]。而基于软件的方法则是通过软件手段将已经采集到的图像在原图的基础上通过特定的算法来构建与之相对应的高分辨率(High Resolution, HR)图像。和基于硬件的方法相比,基于软件的方法的最大的优势就在于可以在不改变原有成像系统的硬件配置的前提下,以更低的成本以及更简单的方式来构建所需的高分辨率图像,实现了图像采集与处理过程的解耦。
.............................
1.2 国内外研究现状
图像超分辨率重构技术有着重要的理论价值与广泛的应用场景,因此引起了学术界以及工业界日益增长的广泛讨论与关注。本小节将从传统的图像超分、基于学习的图像超分、真实场景图像超分、轻量级图像超分四个角度分别论述图像超分辨率领域的国内外研究现状。
1.2.1 传统的图像超分研究
上世纪80年代Tsai和Huang[9]提出了基于多帧低分辨率图像之间的相对运动关系来复原单幅高分辨率图像的方法,被学术界公认为是超分领域的开山之作。在此之后随着计算理论和硬件性能的逐步发展,越来越多的算法广泛应用在了超分领域,并取得了突破性的进展。在神经网络和深度学习兴起之前,具有代表性的传统图像超分算法主要是非均匀插值和频域方法。
非均匀插值(Nonuniform Interpolation)方法是一种直观的图像超分算法。通过估计像素点之间的相对位置信息,得到非均匀采样点上的HR图像。然后,按照直接或迭代的方法来对均匀间隔的采样点进行重构。Ur和Gross[10]利用Papoulis[11]和Brown[12]对非理想条件下多通道信号恢复的处理方法,在假定相对位移准确的情况下引入了去模糊的过程,并对空间偏移的LR图像通过多项式拟合与滤波实现了非均匀插值。Nguyen和Milanfar[13]提出了一种基于小波的超分重建算法,利用了SR中采样网络的交错解构,对二维数据进行了高效的小波插值计算。非均匀差值方法的优势在于计算开销低,使得实时应用成为可能;但是该方法仅适用于具有相似概率分布规律的降质模型,因此具有一定的局限性。
频域方法充分利用了每个LR图像中存储在的混叠来重构HR图像。频域方法基于傅里叶变换的位移特性、原始HR图像的连续傅里叶变化(Continuous Fourier Transform, CFT)和LR图像的离散傅里叶变化(Discrete Fourier Transform, DFT)之间的混叠关系来制定系统方程从而推理出相应的超分图像。Bose等人[14]提出了用于SR重建的自适应最小二乘滤波算法,通过不断调整并更新滤波器的参数来降低图像配准过程中的误差。Rhee和Kang[15]提出了一种基于离散余弦转换(Discrete Cosine Transform, DCT)的方法,通过使用DCT而不是DFT的方法来减少内存需求和计算成本;此外还使用多个正则化参数对图像不同通道的信号特征进行调整来更好保留图像中的有效信息。频域方法的一个最主要的优势是理论的简明性,LR和HR图像之间的映射关系可以在频域中得以清晰展示,并且该方法易于并行运算以降低硬件的复杂度。然而由于频域中缺乏数据的相关性,无法充分利用图像自身的先验信息,因此该方法主要运用在一些退化过程简单的图像重构。
................................
第二章 图像超分辨率重构的理论基础与背景知识
2.2 上采样方法
2.2.1 插值上采样
插值上采样方法是一种基于内插原理实现的图像缩放方法。该方法通过对相邻像素点之间的关系进行数学建模,从而预测出内插像素的数值。插值后的图像携带的像素点更多,有利于增强数字图像的清晰度和部分细节。常见的插值采样方法有最近邻插值、双线性插值以及双三次插值等方法。
1)最近邻插值
最近邻插值算法是最简单的一种插值算法。对于所求的像素点的数据,该算法只考虑距离其最近的像素点的数值,而不考虑其他相邻的像素值。该插值方法虽然实现简单、运算速度快;但由于缺少对相邻像素点的考虑,像素值由于不连续会产生强烈的混叠以及模糊效应。因此该方法只适用于算力资源有限、清晰度要求不高的实时图像渲染任务。
2)双线性插值
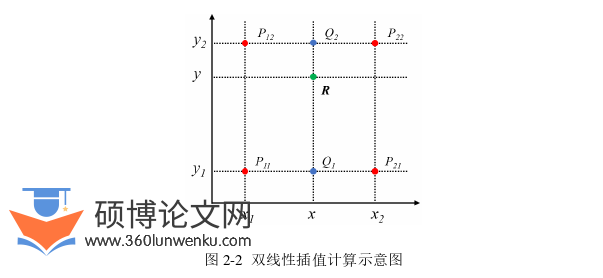
双线性插值方法是对线性插值在二维网格中的扩展。对于需要插值的像素点,需要考虑与之相邻的四个像素点的数值,并分别在水平与竖直方向上进行一次线性插值。其计算过程如图2-2所示。
软件工程论文参考
.........................
2.3 图像退化模型
图像退化模型是一个复杂的过程,在图像采集、传输以及存储的每一个阶段都有可能引入不确定的噪音和信息丢失。鉴于退化模型的不确定性与未知性,当前的主要手段是通过组合常见的退化方法来综合模拟出符合现实场景的图像退化过程。常见的退化方法主要包括下采样、模糊、噪音以及压缩方法。其中,双三次下采样算法作为最常见的下采样方法,通常用于网络模型训练时输入LR图像的生成。其原理与上一小节介绍的双三次插值算法一致本质都是对图像进行重采样,在这里不做赘述。本小节重点介绍另外三种模型。
2.3.1 模糊模型
相机对焦失败或者拍摄的物体处于运动状态等因素会导致采集到的图像出现模糊、不清晰的现象。高斯模糊是最常见的模糊模型。高斯模糊根据高斯曲线(正态分布曲线)对图像进行加权平均处理来过滤高频信号、保留低频信号。在进行高斯模糊计算时会选取一个各向同性(isotropic)或者各向异性(anisotropic)的高斯核(Gaussian Kernel)来对图像进行卷积计算得到对应的模糊值。
2.3.2 噪音模型
图像的噪音来源由采集设备的元器件因外部电磁波的干扰而引起。图像噪音过程通过利用不同的概率密度函数得到噪音值并直接与图像像素值进行相加得到。主要的噪音模型有椒盐噪音、加性高斯噪音以及泊松噪音。
椒盐噪音又称为脉冲噪音,其产生原因主要由于图像在传输过程信号突然受到强烈干扰;表现形式为图像上出现随机的高灰度值与低灰度值的斑点。加性高斯噪音的概率密度函数与上文提到的高斯分布函数一致,其产生原因是图像采集时亮度不够均匀以及传感器因长期工作而导致温度过高而导致。泊松噪音的密度函数遵循泊松分布,其通常用来模拟传感器像素在给定曝光值下感应到光子数量波动而产生的噪音。不同的噪音模型生成出的降质图像。
......................
第三章 轻量级图像超分模型设计 ·················· 20
3.1 模型整体设计 ································· 20
3.1.1 浅层特征提取层 ······························· 21
3.1.2 深层特征提取层 ···························· 22
第四章 边缘特征协同的双分支超分模型设计 ························ 44
4.1 模型详细设计 ·························· 45
4.1.1 整体框架设计 ····························· 45
4.1.2 边缘特征协同网络 ························ 47
第五章 实验分析与系统实现 ······························· 60
5.1 数据集与数据预处理 ···························· 60
5.1.1 数据集 ································· 60
5.1.2 数据预处理 ··································· 61
第五章 实验分析与系统实现
5.1 数据集与数据预处理
5.1.1 数据集
本文使用了DIV2K数据集作为模型的训练集。DIV2K[77]由Agustsson和Timofte于2017年提出并作为当年NTIRE单幅超分挑战赛的数据集。该数据集总共包含了1000张像素分辨率为2K的图片,是当前超分领域使用最广且最具代表性的训练数据集。DIV2K数据集中包含的图片种类丰富,既有在高景深场景下拍摄的内容充实的风光摄影图,又有浅景深场景下局部细节充足的人像以及动植物摄影图。清晰的分辨率与多样化的图像种类使得用该数据集训练出的模型能学习到更加丰富逼真的图像细节以及拥有更强的泛化性。

软件工程论文参考
.............................
第六章 全文总结与展望
6.1 全文总结
图像超分辨率重构通过高性价比的软件算法的方式对低分辨率、模糊不清晰的图像进行重构,生成出分辨率更高、细节更加丰富的高清图像。高分辨率图像既能为下游视觉任务诸如检测、识别提供支持,又符合人类的视觉感知需求,因此图像超分一直是计算机底层视觉领域中一项备受关注的研究方向,并在遥感、监控等细分领域有着长远的发展潜力。深度学习的兴起与计算机性能的快速迭代更使得基于深度学习的图像超分模型的恢复性能得到了大幅提升。然而随着网络结构愈发复杂臃肿,模型的参数规模与计算开销也随之增加,大规模的网络模型难以部署并应用在计算资源有限的低成本设备中。面对这一问题,本文致力于研究图像超分模型的轻量化设计与实现,力求在图像恢复性能与模型的参数量之间达到良好的平衡。具体而言,本文的主要工作内容总结如下。
(1)提出了一个Transformer与CNN相结合的轻量级图像超分网络FTCN。该网络充分利用Swin Transformer与CNN方法对不同类型特征提取的差异性,兼顾了对特征的全局信息与局部信息的把控;并将提取到的全局特征与局部特征进行融合增强来进一步聚合更加精细的特征。通过对Swin Transformer进行轻量化设计以及引入蓝图可分离卷积等方式大幅降低了模型的参数量,使得FTCN的参数量仅为410K左右。
(2)提出了一个双分支的边缘特征协同的图像超分网络E-FTCN,来致力于丰富超分图像的边缘纹理细节,提升图像的视觉感官。在现有的基础上设计了一个基于残差像素注意力模块的分支网络EFC-Net来有监督地跨域学习低分辨率图像与高分辨率图像边缘之间的映射关系;并将边缘特征在上采样前进行高维融合来提升图像超分的重构质量。此外,通过对边缘检测方法进行定性与定量分析选取了一种非二值化散度方法来生成边缘标签图像。该方法提取出的强弱边缘更加清晰,有利于模型在训练过程中对细腻纹理信息的掌控。
参考文献(略)