本文是一篇软件工程论文,本文以分布式存储系统中的热门存储引擎LSM-Tree为例,研究并应用学习索引,力图最大程度解决分布式存储系统中的索引问题。
第一章绪论
1.1研究背景与意义
在分布式存储系统之中,索引是一种加速数据存取的数据结构,各种各样应对不同访问模式的索引被应用在存储软件系统之中,支撑着上层软件的高效运作。例如,B+树索引被广泛应用于查询、存取大规模数据,并且是许多主流数据库(例如Mysql)的核心索引数据结构;而哈希表、红黑树属于内存高效的存取模型;Bloom过滤器则用于快速检查键是否存在于数据之中。索引结构作为一种通用的数据结构,经过几十年的发展和持续的优化,在生产中得到了广泛应用。
在大数据时代,PB级甚至EB级的海量数据已经屡见不鲜,即使是对这些数据进行了分库分表的拆分,数据库等存储系统也避免不了在海量数据之上构建和维护一个索引。构建和维护索引的开销是非常巨大的,有研究指出[1],为典型的OLTP(On-Line Transaction Processing,在线事务处理过程)工作负载创建的索引可以消耗最先进的内存数据库管理系统中可用总内存的55%。而对索引进行压缩处理的技术,例如前缀树,只能压缩具有相同前缀的键,节省空间有限;例如像赫夫曼编码[2]这样更昂贵的压缩技术可以在每个节点内应用,但运行时成本较高,因为磁盘页必须进行解压缩操作才能搜索一个键。即使是对多核处理器进行了特别优化,数据的频繁查询、修改、插入也会造成非常严重的CPU负担。而目前摩尔定律已被证明失效[3],在机器学习算法以及GPU、TPU等物理硬件高速发展的今天,使用机器学习模型来改善传统计算机系统软件是一个趋势[4]。
....................
1.2国内外研究现状
1.2.1分布式存储索引研究现状
随着信息、数据的爆炸式增长,单机存储早已无法满足企业数据存储的需要,而分布式存储正是海量数据存储的最佳解决方案。业界知名的GFS(Google FileSystem)、BigTable、Ceph等分布式存储系统,运行在廉价的服务器上,支持高扩展、高可用、高可靠等特性。然而,分布式存储系统中海量数据造成的索引空间占用巨大、查询性能下降等问题却依然困扰着研究者们,除了在设计和思想上进行的索引结构的优化与改进,目前使用机器学习来优化分布式存储系统也是一个热门方向。
分布式存储索引结构中运用最多的是树状索引结构,他已经经历了数十年的发展,目前最流行的树状索引是B树、R树[7]、X树[8]等。在树索引策略中,树状索引会根据已排序的数据建立索引结构。
B树的工作原理类似于二叉树搜索,但工作方式更为复杂。这是因为B树的节点有很多分支,而不只是两个分支,且B树需要具有能在磁盘上存储节点的能力,所以B树比二叉树更复杂[9]。B树索引能够实现范围查询和相似度查询,也被称为最近邻搜索(Nearest Neighbor Search,NNS)。B树仅适用于一维数据的访问,而其他树状结构则更擅长其他组织形式的数据索引,但B树也可作为实现高维索引的基础索引。此外,B树在海量数据[10]上执行索引时会消耗大量的计算资源。B树的其他变体有B+树[11]、B*树、KDB树[12]等等。R树是一种用于空间或范围查询的索引结构,它主要应用于地理空间系统,每个条目具有X和Y坐标。X树基于R树,可以实现更高维度的范围查询。其中B树、B+树是在存储领域运用最为广泛的索引结构。
.................................
第二章相关理论和技术
2.1学习索引理论
学习索引是利用机器学习算法学习数据分布的特征,并使用数据分布的拟合函数进行数据查找的模型。
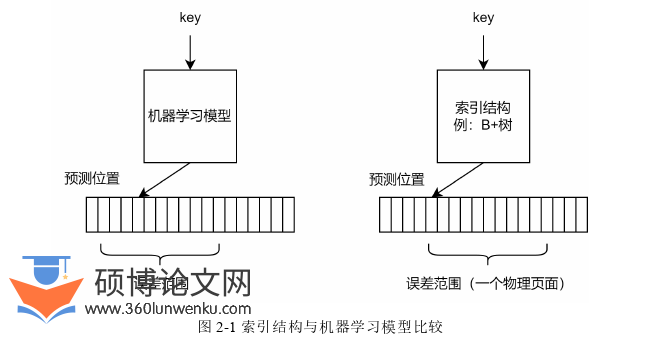
索引结构与机器学习模型同样是根据一个输入的键,返回该键所处的位置。如图2-1所示,索引结构可以视为一种模型,当输入键值后,经过数据分布的拟合函数计算,将得到存储位置结果值输出,它们同样具有输出的误差,必须在误差范围内进行进一步的查找确定最终结果。
软件工程论文怎么写
如图2-2所示,Kraska等人构建了一个递归模型索引(RMI)。使用这种模型,上层的每个小模型负责选择下一个模型,最下层的小模型负责预测误差范围内的键的实际位置。负责某个特定区域的模型能以更低的误差达到更好的预测效果,每个小模型被视为对某些键有更好预测性能的专家,所以该模型也被称为混合专家模型[30],混合专家模型在各个领域均有运用[31,32],旨在解决复杂问题下单一模型解释能力不足、预测效果不好等问题。
...............................
2.2学习索引算法模型在学习索引中,可以根据数据分布进行学习,其主要算法是数据拟合算法,即是如何将原始数据拟合为模型的过程,对于一维数据来讲,就是一个线性回归的过程。
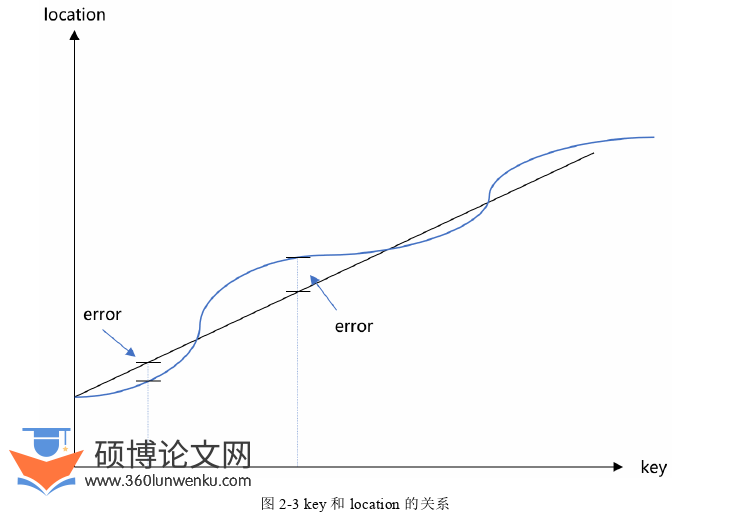
数据拟合算法是构建学习索引的核心,在查询数据的过程中,需要根据映射由一个????????????找到对应的????????????????????????????????。如图2-3所示,我们可以用函数来描述????????????和????????????????????????????????的关系,之后使用线性函数来拟合函数曲线。
软件工程论文参考
其中最核心的问题是,用单条线性函数拟合会存在误差,拟合值可能比真实的值更大或者更小。由于数据排列是有序的,可以继续通过二分查找的方式的定位最终的数据位置,其时间复杂度为O(logN),但如果不能控制误差的范围,那么整个查询的性能就完全得不到保证。所以线性拟合中保证误差有界的机制,对于学习索引的性能和可用性至关重要。接下来会介绍两种学习索引中常用的数据拟合算法。
..................................
第三章LSM-Tree存储引擎的学习索引可行性研究...........................20
3.1 LSM-Tree中的索引过程...............................20
3.2学习索引可行性研究...............................20
第四章基于递归PLR的SSTable学习索引模型............................33
4.1 SSTable学习索引研究问题分析.........................33
4.2 SSTable学习索引模型..............................33
第五章基于Merge-PLR的层级学习索引模型.......................49
5.1层级学习索引研究问题分析.....................................49
5.2 Merge-PLR递归模型.......................................50
第六章分布式存储引擎LIA-LSM实现
6.1 LIA-LSM软件系统模块架构
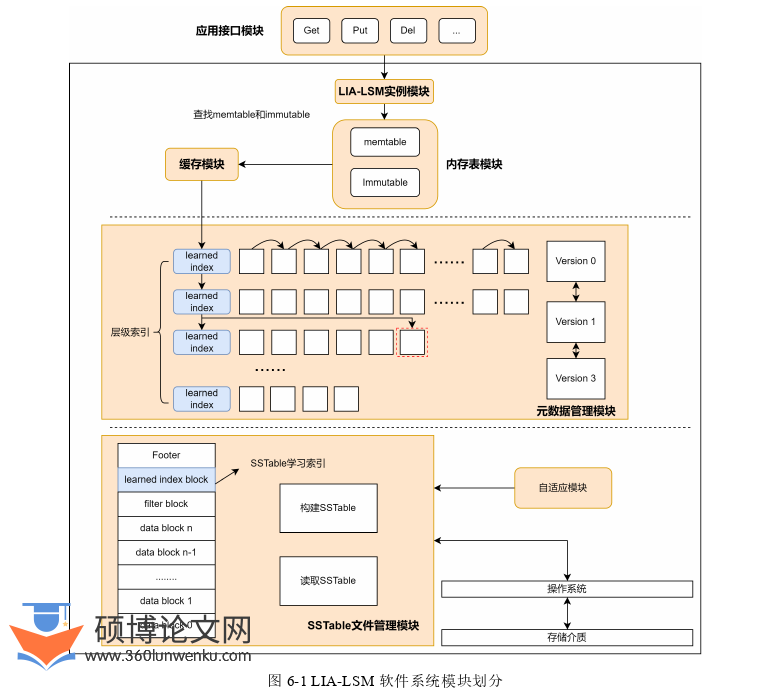
图6-1展示了LIA-LSM的软件系统模块架构,应用接口模块实现了LIA-LSM的接口供上层调用,通用的接口能够使LIA-LSM上层无感知地代替某些常用存储系统。而具体的实现方式由LIA-LSM实例模块进行实现。对于每一个应用层的操作,会直接由内存表模块进行处理。内存表模块由MemTable和ImmuTable组成。在MemTable达到存储上限时会转变为不可变的ImmuTable。在写入SSTable文件之前,会首先由元数据管理模块生成元数据,再由SSTable文件管理模块进行文件的构建。而SSTable文件管理模块处理与本机服务器操作系统的交互,包括读写磁盘上的文件等操作。当操作需要访问SSTable文件时,由元数据管理模块继续处理,通过元数据管理模块可以访问到文件的元数据,进一步通过SSTable文件管理模块进行SSTable文件的读取操作。自适应模块用于指导SSTable文件中学习索引的构建。
软件工程论文参考
..................................
第七章全文总结与展望
7.1全文总结
在分布式存储领域,如何解决海量数据造成的索引空间消耗和索引过程中额外的读取消耗,是十分重要的研究方向。存储引擎作为分布式存储系统中最为核心的部件,存储引擎中的索引结构依然面临着索引空间占用庞大、时间效率低等问题,而且是分布式存储系统索引问题的根本来源,只要解决了存储引擎中的索引问题,就能很大程度地解决分布式存储系统海量数据索引问题。本文以分布式存储系统中的热门存储引擎LSM-Tree为例,研究并应用学习索引,力图最大程度解决分布式存储系统中的索引问题。
本文从存储引擎入手,以分布式存储系统中常用的存储引擎LSM-Tree为例进行自适应学习索引的研究与应用,并形成了以下成果:
1.评估了学习索引在分布式存储引擎LSM-Tree里应用的可行性和性价比,SSTable文件寿命、SSTable文件查询次数、Compaction等实验分析,实验数据证明了学习索引不仅能够在机械硬盘以及固态硬盘等常用存储介质中收益,且能够在日益发展的更快的存储设备中获得更高的性能。
2.在上述研究的基础上,研究并提出了一种在SSTable文件中的学习索引模型以及自适应学习索引构建方法。自适应学习索引构建方法使得学习索引能够以历史的信息为基础指导SSTable学习索引的构建,并且支持和SSTable文件一并持久化到磁盘中。实验证明本文设计的学习索引,对比同类可持久化的Sparse-Index,SSTable学习索引节省了29.23%的磁盘空间占用,对比B+-Tree,节省了91.37%的磁盘空间占用。在查找时延上,SSTable学习索引比Sparse-Index快35%-52%,比B+-Tree快29%-40%。
3.研究并提出了基于Merge-PLR递归模型的层级学习索引模型,通过设计缓冲区来支持键的动态插入,当缓冲区满时,与已构建的学习索引进行合并。在真实数据集的性能对比实验中,层级学习索引对比同类学习索引,读性能提升了0.64%-33.92%,空间占用节省了2.12%-56.74%。对比传统索引,读性能提升了53.77%-196.45%,空间占用节省了56.09%-60.48%。
参考文献(略)