本文是一篇软件工程论文,本文所提出的数据资源端边云采样同步机制与实验对比的同步机制相比较,数据资源端边云采样同步时间快了0.06秒;提出的计算副本资源云边部署同步机制将同步时间从3.79秒降到了0.12秒,比原同步时间减少了3.67秒。
第1章 绪论
1.1 课题研究的背景和意义
云边端分布式系统部署的资源中可以封装并运行一个或多个容器[1],对多个容器进行封装组成高耦合应用,并且彼此之间能够共享数据、共享命名空间以及使用本机端口相互通信。将容器内封装的存储资源作为一个实体来管理,并支持数据持久化存储[2],避免其中任意一个容器反复重启从而导致数据丢失情况出现,云边端分布式系统中部署的资源可以进行动态的创建、销毁以及更新修改。端设备收集的数据资源是从边缘计算网络内部的物理设备中抽象出来的,是为用户提供数据存储、归档、备份等服务的基础资源,当涉及到物联网终端设备大规模数据传输至云端时,资源之间的分配协作以及边缘服务器与云服务器之间低延迟同步的需求是具有挑战的。
资源同步[3]是云边端分布式系统最显著的特点,是以最低的成本满足用户的低延迟服务需求,以此获取最好的服务质量[4]。在工业互联网大流量场景下[5],云服务器具有强大的资源服务能力,但是在远距离传输场景下具有不足之处,边缘服务器具有传输低时延的优势,但是资源服务能力受限[6];因此,结合了云服务器与边缘服务器优点的云边资源同步技术既可以实现更低的端到端延迟,又对云边端分布式系统性能的提升至关重要,并垂直于云端服务器节点与边缘端服务器节点之间支持综合资源同步操作。资源同步技术支持数据在云端和边缘端之间有序可控地传输,在云边之间形成一条完整的消息传输路径,以最低的成本挖掘数据价值以及高效率地管理数据的整个生命周期,资源分别保存到云边端分布式系统的云端数据库和边缘数据库中。由于边缘服务器融合分布式系统的设备多样性、位置复杂性和资源动态性等特点,边缘服务器节点之间的资源协作是一个重要的问题[7],有效地提高网络性能,降低边缘服务器与云服务器之间同步的延迟,提升用户的资源服务体验质量[8]是未来无线网络的一个重要目标,引起了研究者广泛的研究兴趣。
..............................
1.2 国内外研究现状
在2014年,由GE、思科、IBM和英特尔等其他巨头成立工业互联网联盟 (IIC) 开始着手制定连接对象、传感器和大型计算系统,后续有博世、华为、施耐德电气、SAP 等诸多公司加入IIC。在2017年,国家加快生产建设,加快高新技术产业发展,推动互联网、分布式数据存储、云计算和边缘计算深度融合,进一步为工业互联网发展做出贡献。工业互联网通过新的方式把传感器设备、控制器、人员等结合在一起,利用互联网通信技术实现自动化、智能现代化以及远程控制管理的网络[14]。
2012年,Zhang等人[15]开发了一个基于BIM的云服务应用框架。2014年,Chong等人[16]对工业互联网中现有的云服务应用进行了研究,并开发了一个决策模型来选择合适的应用。Almaatouk等人[17]研究了云服务改善工业互联网场景中协作的潜力,并得出结论,云计算服务降低了数据存储的成本。Bilal等人[18]详细阐述了云服务在工业互联网环境中的适用性,虚拟集群允许能量地分配可视化的资源[19]。在中心云中,一些节点可能负载较轻,而另一些节点负载较重,导致性能较差[20],为了有效地执行复杂应用程序的作业需要并行处理,在并行进程中,通信和同步的存在允许更有效地使用CPU资源。因此,总的来说,保持并行作业的响应水平,同时实现节点的有效利用对于数据中心来说是强制性的。
中心云通过互联网提供包括服务器、数据存储、信息处理技术、网络通信和数据分析等服务,以提供资源更快的部署和灵活的分配。工业互联网是数据密集型行业,随着万物互联时代的快速兴起,大量设备的接入和关联的海量数据不断生成异构密集型资源,人们将海量异构终端设备产生的数据资源放到中心云上进行管理。中心云具有不需要提供商协助单方面直接获取资源、广泛网络接入、共享资源池的方式统一管理资源、服务规模弹性收缩和计费服务五个基本特征;具有软件即服务(SaaS)[21]、平台即服务(PaaS)[22]、基础设施即服务(IaaS)[23]三种服务模型;还具有公共、私有、社区和混合四个部署模型[24]。可以直接在中心云上管理资源,有即时需求的用户无需与资源的提供者进行人工交互,同时保证了个人隐私和安全,提高了用户服务质量。
.............................
第2章 相关理论知识
2.1 云边端分布系统技术架构
2.1.1 云服务器
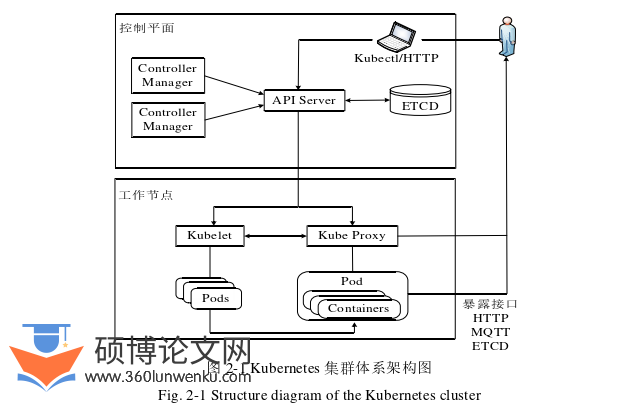
云边端分布式系统中的云服务器采用Kubernetes[39]技术架构。Kubernetes是一个自动编排容器化应用程序的开源平台,在此平台上的容器化应用程序不必手动部署、扩容缩容以及管理,并且支持大规模容器化应用程序分布式部署、编排以及管理操作,能够跨主机构建多容器组成的高耦合应用服务,在集群上进行应用服务调度,以及管理它们随时间变化的健康状态。此外,Kubernetes为了解决容器化应用程序增加过多导致容器管理复杂问题,将容器进行分组并由Pod进行管理,每个Pod抽象地管理一组容器,为系统内正在运行的应用程序调度服务和容器存储必要的网络服务提供帮助,Kubernetes将负载任务均衡分配到其内部的其他组件上共同执行,并维持着系统稳定性。Kubernetes集群体系结构如图2-1所示。
软件工程论文怎么写
.....................................
2.2 资源的定义
2.2.1 数据资源
云边端分布式系统中,终端传感器设备收集的温湿度数据经过MQTT格式映射统一转换传输到边缘服务器的资源称为数据资源。
2.2.2 计算副本资源
在云边端分布式系统中例如Pod、Service、Job以及Deployment等可以申请、分配,最终被使用的都被抽象为计算副本资源。对象是计算副本资源的实例,是持久化的实体,例如系统内部署的某个具体的Pod、某个具体的Node。每个计算副本资源对应的yaml文件中必须含有apiVersion、kind、metadata三个必需字段,此外还包含负责管理计算副本资源配置的spec和status两个嵌套对象字段。使用kubernetes API创建计算副本资源时,必须提供计算副本资源的spec字段,用来描述该计算副本资源的期望状态,计算副本资源的status字段描述了系统中实际运行的状态,Kubernetes控制平面在系统运行的任何时刻会一直保持活跃的状态,管理计算副本资源实际运行状态与期望状态进行匹配。
...........................
第3章 数据资源端边云采样同步机制 ........................ 13
3.1 引言 ........................................ 13
3.2 相关工作 ................................. 14
第4章 计算副本资源云边部署同步机制 ...................... 30
4.1 引言 ................................ 30
4.2 相关工作 .................................... 31
结论 ......................................... 46
第4章 计算副本资源云边部署同步机制
4.1 引言
容器虚拟化技术[54]在工业互联网使用案例的流程和工作负载方面实现了前所未有的创新,极大地促进了工业互联网领域的发展,工业互联网的应用通常以关键基础设施、物理组件及最终用户交互为中心。
如今,服务器虚拟化[55]技术广泛应用于数据中心,其主要目标是将应用程序从底层基础设施中分离出来,无论是硬件虚拟化还是操作系统软件虚拟化的容器,虚拟化技术正在加强应用程序部署,可以根据操作系统运行的方式区别这两种类型的虚拟化:虚拟机在虚拟化服务器资源的管理程序之上运行自己的操作系统,而在容器中资源在操作系统级别上进行虚拟化,因为它们封装了应用程序的进程和依赖项。Kubernetes是一个用于大规模云系统的编排框架,构建在容器化应用程序管理的基础上,这是当今云环境中的一种现代且常见的做法[56],协调和虚拟化为负载资源提供了多种优势,例如服务隔离、更大的灵活性、无限的可扩展性以及普遍提高的弹性[57]。KubeEdge扩展了Kubernetes容器集群,并支持以无缝方式编排和管理具有资源限制的物理组件[58],云边通信是基于消息的,使用WebSocket[59]在单个TCP连接上提供全双工、异步通信通道,该模型能够更好地控制云端和边缘端之间的通信策略,由于消息可以排队并以周期性方式异步发送,因此开销进一步降低。
软件工程论文参考
..............................
结论
在工业互联网领域中,分布式系统的资源同步技术逐渐成为研究热点,但是在现实复杂的场景中,资源同步受多种因素的干扰,存在一定的延迟问题。本文主要研究了云边端分布式系统的资源同步机制,分别从数据资源端边云采样同步和计算副本资源云边部署同步完成研究,在本文的第三章和第四章分别对数据资源端边云采样同步机制和计算副本资源云边部署同步机制进行了详细地阐述,并针对时延问题分别提出了新的资源同步机制。同时将本文提出的数据资源端边云采样同步机制和计算副本资源云边部署同步机制分别在Kubernetes和KubeEdge搭建的平台上进行仿真实验,在设备数据发射速率不同和端设备数量不同两种情况下,分别验证了数据资源端边云采样同步机制的有效性;在CPU利用率不同和内存占用率不同两种情况下,分别验证了计算副本资源云边部署同步机制的有效性。实验结果表明,本文提出的两种资源同步机制具有更高的同步性能。现将本文主要的研究成果总结如下:
(1)提出了一种数据资源端边云采样同步机制。针对不同边缘服务器连接的不同端设备收集的数据资源同步到云端K8S API Server存在的延迟问题,对云端CloudHub组件进行了改进。首先,CloudHub组件接收来自所有边缘服务器的数据资源,从所有的数据资源中过滤出来自指定边缘服务器连接的指定端设备发送的数据资源;然后,将其直接转发至云端服务器设备控制器组件,由上行设备控制器解析数据资源;最后,将其数据值同步到K8S API Server上。实验结果表明,本文改进的数据资源端边云采样同步机制有效地降低了数据资源同步时延,同步时间比原方案快了0.06秒,实时处理系统数据资源,解决了数据和边缘服务器的异构性和协同性,提高了数据资源端边云采样同步效率。
(2)提出了一种计算副本资源云边部署同步机制。针对集群中部署的计算副本资源由云服务器同步到边缘服务器存在一定的时延问题,对云端同步控制器组件进行了改进,使指定边缘服务器的计算副本资源不必参加系统每隔5秒的轮询,实现计算副本资源云边部署同步。首先,云端ETCD数据库和K8S CRD中存储的计算副本资源在参加系统轮询之前进行分流处理,将来自指定边缘服务器的计算副本资源从总的资源中分离出来;然后,实现消息分发机制,触发相应的更新或删除事件,构建事件消息并将消息直接转发到指定边缘服务器节点的消息队列中;最后,由边缘服务器进行相应的元数据更新或删除操作,实现云服务器和边缘服务器之间的计算副本资源一致性。
参考文献(略)