本文是一篇软件工程论文,本文采用词嵌入的技术,分析了需求的结构特点,并结合查询扩展技术提出了细粒度查询扩展跟踪链接恢复算法。本文提出的无监督方法与近些年的方法进行实验比较,同无监督方法比较,在三个数据集上的平均F1数值高于第二名0.041;和监督方法比较,高于部分监督方法。
第一章 绪论
1.1 研究背景与意义
20世纪90年代以来需求工程一直是软件工程领域的重要研究方向之一。自1993年至今,越来越多与需求工程相关的一些国际会议被举办[1],例如:需求工程国际研讨会(ISRE)和需求工程国际会议(ICRE)。需求工程是软件工程的一个分支,是在设计过程中定义、记录和维护需求,被认为是软件系统相关项目成功与否的关键因素,严格的需求工程是保障复杂的应用程序功能和性能健全的关键,特别是在当前软件产品迅速变化迭代的时代[2]。
完整的需求工程包含需求开发和需求管理,其中需求开发主要分为这样几个阶段:需求获取、需求建模、需求规约、需求验证。需求规约是由需求模型生成精确的一种需求描述,这种需求描述在实际的需求管理中就是需求的规格说明书,它将作为用户与项目开发者之间的一致性协议。需求验证就是对需求规约的内容进行检验,判断是否符合规范。而在需求管理的阶段主要是进行需求基线、需求追踪、需求变更等方面的工作,该阶段中需求和源代码之间的可追踪性链接有助于提高影响分析、需求验证和可重用分析的性能[3, 4],同时对于一些对安全性较高的系统,可跟踪性对于证明系统功能的实现起到至关重要的作用[5]。
大多数需求管理软件(例如Rational Doors、禅道)都存在需求跟踪链接建立和编辑功能,该功能作为需求管理软件重要的组成部分往往经常被使用,但是其建立过程几乎都是手动,需要需求管理人员手动建立需求跟踪链接。现代公司所管理的项目成百上千,这些项目需要进行数十万需求的复杂软件任务过程、质量控制以及审计工作。对这样的大型软件项目的需求进行管理时,在数量繁多的需求工件和代码工件之间建立跟踪链接就是一项开销十分巨大且极易出错的工作,这种情况阻碍了大型项目的开发、测试等一系列进度,对项目按期完成造成了的一定的挑战。
.........................
1.2 国内外研究现状
需求跟踪链接恢复的概念上世纪就已经出现。软件需求跟踪性链接恢复的研究伴随着业界对于软件工程领域的研究的深入而深入,由于国外在软件领域的研究先于国内,因此,在需求跟踪性链接恢复领域的研究也早于国内,国外自上世纪90年代就开始相关的研究。上世纪末至本世纪初,需求跟踪链接恢复的研究处于初期阶段,主要使用一些传统的信息检索[6](Information Retrieval,IR)技术进行跟踪链接恢复,同时处理手段较为单一。IR模型通常采用词袋(Bag of Words,BoW)模型,该模型将文档表示为无序的单词集合,忽略了词序[7]。
现有大多数IR模型假定两个工件是否存在跟踪关系与相似度相关[8]。一个十分著名的跟踪链接恢复IR模型是向量空间模型(Vector Space Model,VSM)[9],许多检索框架使用该模型作为检索引擎核心。VSM模型的核心思想是:将每个词项赋予不同的权重,文档就可以表示为一个权重向量,通过比较权重向量的相似性进而得到文档之间的相似性。单个术语在不同上下文语境中意义并不一定相同,因此它们的权重是不同的。术语权重既可以是二进制的(即存在或不存在),也可以是基于术语频率的,但通常使用术语频率-逆文档频率(TF-IDF)作为词项的权重,TF-IDF根据文档的长度和术语在文档和整个文档集合中的出现频率对术语进行加权[10]。在相似性度量方面,余弦相似度(通过向量夹角的余弦计算)是一种使用十分广泛的相似度度量方法,但也有一些模型采用Dice系数和Jaccard指数作为相似度函数[11]。进一步地,为了减少自然语言表述的需求中存在的噪音,一些研究者将潜在语义索引(Latent Semantic Indexing,LSI)[12]这一技术应用到跟踪链接恢复领域。LSI降低了向量空间的维数,使用奇异值分解找到半维数,新的维度不再是单独的术语,而是表示为术语组合的概念。
................................
第二章 相关理论与技术
2.1 无监督跟踪链接恢复技术
2.1.1 IR技术
2.1.1.1 TF-IDF
TF-IDF即词频-逆文档频率,是一种在信息检索领域常见的方法,主要用于对词进行加权。
TF(词频)指的是一个文档????????中,一个词????????出现的频率,计算公式为(2-1)。在同一文本中一个词出现的频率越高表明其重要性越大。
TF-IDF表达了这样一种思想:一个词的重要性由两个方面判定,一方面重要的词在同一个文档中应该反复出现;另一方面,这个词在其他文档中出现频率较低,甚至不出现。这表明这个单词具备很好的区分性,有助于进行文本分类等相关任务。
2.1.1.2 VSM
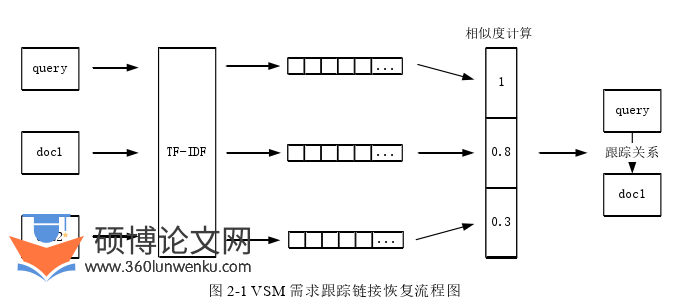
向量空间模型(VSM)在上个世纪被提出并被广泛应用于信息检索领域。VSM通过将自然语言表述的需求使用向量表征,然后使用文本相似性函数计算文本之间的相似性,计算得到的相似性作为建立需求链接的重要判别依据。VSM进行跟踪链接恢复的流程图如图2-1所示。
VSM原理简单,计算复杂度低,但是该方法使用TF-IDF将文档转化为向量,TF-IDF忽略了词在文档中的位置,只考虑词在文档中以及在整个语料库中的频率,从语言理解的角度分析,这种方式是不合理的。同时,对于一些专有名词(例如:人名、地名等)在文档中出现的频率较低,但是在很多情况下这些词对于界定需求跟踪关系存在与否却至关重要,而使用TF-IDF则会忽略这种情况,这些因素导致该方法整体效果不佳。
软件工程论文怎么写
...............................
2.2 有监督跟踪链接恢复技术
2.2.1 WELR
在2017年Zhao[29]提出了一种基于词嵌入技术和学习排序来进行跟踪链接恢复的方法WELR。在过去的一些方法中,对于混合了多种语言的文本、代码片段和专业术语的软件工件进行跟踪链接恢复往往难以达到理想的效果。学习排名[30](Learning to rank)是一种在排序任务中训练模型的机器学习技术,在信息检索、自然语言处理和数据挖掘等领域中到了广泛的应用。在过去的很多跟踪链接恢复方法中,Ltr技术被较少提及,Zhao发现跟踪链接恢复任务中往往存在相似度排序的阶段,因此WELR借助学习排序技术利用到了跟踪链接相似性的排序列表,进一步提升了跟踪链接恢复的效果。
WELR主要包含两个阶段:预处理阶段和词嵌入学习排序阶段。如下图所示,预处理阶段将需求相关的软件工件进行分词、去除不能识别的编码等预处理过程同时使用wiki的数据进行词嵌入学习过程。词嵌入学习排序阶段首先对预处理阶段的文本使用WQI(包括词嵌入、查询扩展和IDF加权策略)进行处理生成排序列表,之后通过学习排序构建预测模型确定跟踪链接。Zhao在五个公共数据集上进行实验,并且考虑了不同工件之间的跟踪链接恢复,实验结果优于传统的IR方法以及当时性能最好的AML[31]方法。
2.2.2 TRAIL
在软件管理和维护过程中,伴随着软件工件的增删和修改,原本的需求跟踪性链接也需要进行相应的更新以确保跟踪性链接的有效性,TRAIL[13]就是为了解决这一问题被提出来。TRAIL利用先前捕获的需求跟踪性的知识来训练一个机器学习分类器,该分类器可以用来派生新的可追溯性链接并更新现有的链接。该方法在6个软件系统的11个常用追溯数据集上进行了评估,并将其与7个常见的IR技术进行了比较。结果表明,TRAIL在准确性、召回率和F指标方面优于所有IR方法。
...........................
第三章 系统需求分析 ···························· 17
3.1 系统需求概述 ··································· 17
3.2 系统可行性分析 ······························· 17
第四章 需求链接自动恢复研究 ··················· 25
4.1 概述································ 25
4.2 需求数据集预处理 ······························ 25
第五章 需求变更管理系统总体设计 ····························· 47
5.1 概述································ 47
5.2 需求变更分析设计 ························· 51
第六章 系统实现与测试
6.1 系统部署环境
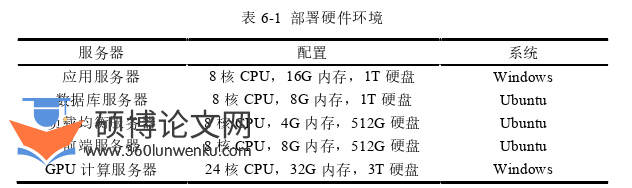
本系统部署环境包括部署硬件环境和软件环境。整个系统的主程序部署在应用服务器中,数据库服务器安装数据库管理软件进行数据管理,负载均衡服务器对来自前端的请求进行负载均衡,前端服务器部署Node环境和Vue等相关环境,GPU计算服务器用于进行高性能计算,具体的服务器配置如表6-1所示。除此之外,还需要进行系统必要软件环境的部署,软件环境如表6-2所示。
软件工程论文参考
..................................
第七章 总结与展望
7.1 全文工作总结
随着软件行业的飞速发展,软件行业对于软件开发的要求越来越高,开发周期越来越短、软件质量越来越高、软件逻辑越来越复杂、集成化程度越来越高,这些因素促使软件需求管理的要求越来越高,而需求管理中十分重要的部分就是需求跟踪链接。然而,该任务十分耗时且易出错。本文对需求管理中跟踪链接恢复任务进行了研究,并实现了能够进行自动化的跟踪链接恢复的需求变更管理系统,辅助需求管理人员建立需求跟踪链接。本文的主要工作如下:
1、分析了传统算法的不足,提出了细粒度查询扩展跟踪链接恢复算法。传统的IR方法由于其忽略了词之前的顺序,并没有真正理解句子的语义,因此在跟踪链接恢复任务中并没有展示足够好的效果,本文采用词嵌入的技术,分析了需求的结构特点,并结合查询扩展技术提出了细粒度查询扩展跟踪链接恢复算法。本文提出的无监督方法与近些年的方法进行实验比较,同无监督方法比较,在三个数据集上的平均F1数值高于第二名0.041;和监督方法比较,高于部分监督方法。
2、对于非关系型的需求数据存储采用了EAV数据库模型,提升了存储效率。同时设计了数据抽取算法,减少了无用数据对于跟踪链接恢复效率的影响。需求变更管理系统存储的需求为非关系型的数据,这种数据使用关系型数据库存储会导致大量的数据冗余;使用非关系型数据库,其功能和性能难以满足系统需求。本文采用EAV数据库模型,将需求实体、属性和属性值分开存储,可以较为高效地进行需求属性的管理。对于从数据库中获得的数据,其内部存在冗余无用的信息,这些信息不但不会帮助提升跟踪链接恢复的准确性,反而会增加系统的资源消耗,本文设计了数据抽取算法以过滤无用数据,提升模型运行效率。
3、设计并实现了变更管理功能。需求变更管理系统十分重要的功能为变更管理,本文采用自动化的方式辅助建立跟踪链接,当需求发生变动时可以通过建立的跟踪链接找到其影响的源代码工件,安全地进行需求的变更操作。
参考文献(略)