本文是一篇软件工程论文,本文以人脸图像最优潜向量为基础,利用表情的语义方向向量为导向,提出了新的可控人脸表情编辑模型。该模型考虑到生成器潜空间的可解释性,基于样本矩阵主成分与语义边界的优点,通过计算各类表情的语义方向向量来实现模型的可控性。
第1章 绪论
1.1 研究背景与研究意义
人类情感主要通过面部表情来进行传达,与声音、手势、肢体等传递方式相比,面部表情能传递更丰富的信息且具有较好的通用性和普适性[1]。因此,人脸表情在智能生产、信息安全、智慧交通、智慧医疗等领域有着非常广泛的应用。例如:在智能生产领域[4],通过实时捕获工作人员的表情变化来获取其当前的心理状态,当出现异常情绪时,能够及时采取措施来舒缓工作人员的这种情绪,从而保证生产安全;在智慧交通领域[5],通过对人脸表情检测能够实时监测司机是否处于疲劳驾驶状态,当发现异常时能够发出预警并限制车辆的行驶速度以保证驾乘人员的生命安全;在智慧医疗领域[6],当医护人员和家属无法24小时关注病人的状态时,人脸表情检测系统可以通过捕获病人的面部表情得到病人的实时状态,在病人需要帮助时,系统能够及时向医护人员和家属发送信息,以免错过最佳救助时间。
但随着研究的深入,人们发现人脸表情的类别越来越丰富。因此,为了详细描述人脸表情变化,瑞典生物学家Carl-Herman结合心理学和生物学提出了一套完整的面部动作编码系统(Facial Action Coding System,FACS)[2]。FACS根据人脸表情的细微运动变化,分别以面部各个肌肉群为对象,通过对不同动作的类别进行编码实现对人脸肌肉群分类,从而得到人脸表情图像所对应的44个面部动作单元(Action Units,AU),有效地建立了人脸表情分析的外观标准。
...........................
1.2 国内外研究现状
1.2.1 人脸图像映射
由于生成对抗网缺乏对真实图像的推理能力和生成能力,导致生成对抗网大多数应用均体现在随机向量合成的虚假图像(Fake Image)上而非真实图像。然而,人脸图像映射可以作为连接生成对抗网和真实图像的桥梁,它能够将真实图像从图像空间映射到生成器的潜空间中,以获取该图像所对应的潜向量(Latent Vector),使得生成器既可以根据得到的潜向量来生成该图像的重建结果,也可以在生成器潜空间中通过语义方向向量来编辑真实图像[8]。Richardson等人[67]提出了一个通用的人脸图像映射框架(pixel2style2pixel,pSp)。pSp框架利用编码器实现图像的映射,并且在网络中通过map2style模块来学习图像的风格样式,以提升图像的可编辑性。Wei等人[9]提出了一种用于StyleGAN映射的网络模型(E2Style),该模型能够从图像的浅、中、深三个层面提取图像的特征。文献[67]通过引入迭代细化机制来改进编码器以提升图像映射的可靠性。文献[56]提出了一种基于优化的人脸图像映射算法,该算法提供了两种初始潜向量:随机向量与StyleGAN的平均向量,任意选择一种初始潜向量后,利用梯度下降的优化方式将真实图像映射到StyleGAN潜空间中。尽管该方法能够实现人脸图像的映射,但是要想获得可靠的重建结果,需要用大量的初始潜向量来进行测试,导致计算量较大。Zhu等人[10]提出了一种域内生成对抗网映射方法,该方法设计了一种新型的域引导编码器,用于将输入的真实图像映射到生成对抗网的潜空间中。不仅能够生成自然的重建图像,并且获取到的潜向量还具有较好的可编辑性。Daniel等人[11]提出了一个用于StyleGAN潜空间的人脸图像映射方法,该方法使用随机向量作为初始潜向量,然后通过对生成器进行调优来获得最优潜向量。Alaluf等人[12]将人脸图像映射分为两个阶段:在第一个阶段,通过训练一个编码器来提取输入图像的初始潜向量;在第二个阶段,该模型引入了一个超网络(Hyper-Network)在映射过程中恢复丢失的信息以提升重建图像的质量。
................................
第2章 人脸表情编辑相关理论与技术
2.1 生成对抗网
2.1.1 生成对抗网的原理
生成对抗网(Generative Adversarial Network,GAN)是Ian Goodfellow于2014年提出[51]。与传统的深度神经网络不同,GAN包含生成器和判别器两部分,通过相互博弈的方式进行优化训练,最终达到两个网络的平衡点。在对抗训练中,生成器学习真实图像的特征,生成以假乱真的结果;判别器对真实图像和生成器生成的图像进行识别区分,二者相互对抗相互优化,直到判别器无法识别图像属于真实图像还是生成图像为止。这一过程可以用一个有趣的比喻来帮助理解。生成器好比一个假币制造者,试图制造假币而不被发现;判别器类似于警察,试图识别假币。假币制造者和警察不断改进自己的技术以期望赢过对方,这样一来就会使得假币越来越接近于真币导致警察无法识别[52],生成对抗网的原理如图2.1所示。

软件工程论文怎么写
在图2.1中,将一个随机向量作为生成器的输入,真实样本和生成样本作为判别器的输入。在训练过程中,生成器通过对抗训练优化自身参数,拟合真实样本的分布,使生成的结果尽可能符合真实样本分布。将生成样本和真实样本一起输入判别器,判别器通过识别真假尽可能地将二者区分开来。其中,若是真实样本,判别器得到的样本标签尽可能靠近1;若是生成样本,判别器得到的样本标签尽可能靠近0。在这个相互博弈的过程中,生成器和判别器都能得到优化,从而提高各自的性能。直到生成器和判别器达到纳什均衡(Nash Equilibrium)状态,即判别器无法判断输入的样本为真还是为假。
.............................
2.2 自编码器
传统的自编码器因其全连接的方式忽略了图像中的二维结构,在训练过程中就会因为模型的参数冗余造成效率低下。卷积自编码器与自编码器的网络结构相同,包含一个编码器和一个解码器,但是为了解决自编码器所存在的问题,在自编码器的基础上,引入了卷积和池化操作,实现了局部连接和权值共享。使得卷积自编码器在训练过程中,减少了网络参数,使其利用更多的卷积核进行卷积操作获取更丰富的图像特征。
ResNet残差网络[55](Residual Networks,ResNet)改善了深度神经网络中因为层数增加带来的梯度消失/爆炸问题,解决了因模型准确率饱和带来的网络退化问题。
传统的卷积神经网络期望学习到一个最优的非线性映射函数????(????),使得同一个类别的数据在经过该映射时能够相互靠拢。RseNet通过在前馈网络中增加一个快捷连接(Shortcut Connections)将????(????)改写为????(????)=????(????)+????来实现最优映射。如图2.4(a)所示。快捷连接能够以不同的步长跳过一个或多个权重层后回到主干网络。因此,在训练过程中,低层误差就可以通过快捷连接快速地向上一层进行传播,使得ResNet模型中因网络层数增加导致的梯度消失/爆炸问题得到缓解,网络的输出可以由公式(2.9)进行解释。
............................
第3章 基于面部动作单元分块的人脸表情图像映射 ................................ 16
3.1 模型概览 .................................. 16
3.2 ROI块的划分 .................................. 17
第4章 可控人脸表情编辑 ................................... 32
4.1 所提出的模型 ....................................... 32
4.2 表情语义方向向量 ............................... 32
第5章 总结与展望 ..................................... 50
5.1 总结 ....................................... 50
5.2 展望 ................................... 50
第4章 可控人脸表情编辑
4.1 所提出的模型 本章提出的可控人脸表情编辑模型由一个表情识别模型和一个基于生成对抗网的表情编辑模型组成,其目的是通过语义方向向量(Semantic Direction Vector)来控制表情编辑的生成结果。另外,本章还设计了新的损失函数来提升生成图像的质量。模型的结构如图 4.1所示:
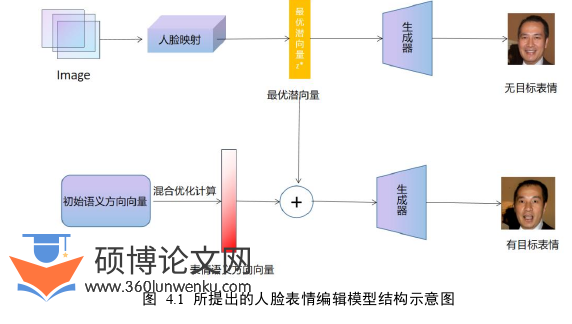
软件工程论文参考
...........................
第5章 总结与展望
5.1 总结
本文基于面部动作单元提出了可控的人脸表情编辑算法,其目的是实现人脸图像的表情编辑。主要研究工作概括如下:
第一,本文针对人脸映射过程中存在的质量较差、特征映射不完整等问题基于面部动作单元在各类表情图像上的分布情况,确定了每组面部动作单元的中心位置及分布范围,对完整的人脸表情图像进行了局部图像块的划分。并在此基础上,训练了用于特征提取的卷积自编码器,不仅能得到人脸表情图像的局部特征,还能获取人脸表情图像的全局结构特征,使其映射为潜向量时可以确保结构信息、纹理信息等不被破坏,提升重建图像的生成质量。此外,为了确保映射时身份信息不受改变,引入了新的损失函数(身份信息损失和内容感知损失),并利用梯度下降法来计算出人脸图像的最优潜向量用于后续的重建和编辑任务。实验证明,本文提出的人脸表情图像映射模型能够有效改善重建图像的质量,避免伪影、身份信息丢失等情况的出现。
第二,针对人脸表情编辑所存在的可控性差、身份不一致等问题,本文以人脸图像最优潜向量为基础,利用表情的语义方向向量为导向,提出了新的可控人脸表情编辑模型。该模型考虑到生成器潜空间的可解释性,基于样本矩阵主成分与语义边界的优点,通过计算各类表情的语义方向向量来实现模型的可控性。同时设计了新的损失函数,将人脸图像的内容信息与结构信息考虑在内,使得编辑的图像保留原有的内容和结构,提升图像的生成质量。并且通过定性和定量两种度量方式来证明了该模型在表情编辑方面的有效性与优越性。从定性评估的可视化结果可以看出,本文算法表情编辑后生成的图像最自然,且表情编辑过程中的可控性更高,更符合真实的人脸表情。
参考文献(略)