本文是一篇软件工程硕士论文,本文将来的工作可以分为以下几点: (1) 在无监督领域适应中,可以使用谱聚类进行预先处理数据,把相同特征的样本聚类到一起,然后进行深度对抗域适应。这是比较有研究意义的方向。 (2) DA2NN的前提是源域和目标域具有相同类别空间,由此可以联想在源域和目标域不同类别空间上,同时考虑类内迁移和类间迁移。这也是值得研究。
第一章 绪论
1.1 研究背景
机器学习方法支撑人工智能的发展,在学术和产业界受到了广泛关注。机器学习旨在让机器自动获取数据中的相关信息,从而应对新的数据进行预测[1]。迁移学习是一种学习的思想和模式,作为机器学习的一个重要领域,迁移学习侧重于将已经学习过的信息迁移应用于不同但相关的学习任务。迁移学习要解决的关键问题是,只有找到两个研究任务之间的相似性,才可以顺利地实现知识的迁移。人类与生俱来的能力是模仿,其实这也是一种迁移学习的能力。比如,如果已经学会打羽毛球,就可以类比着学习打网球。再比如,如果已经学会唱儿歌,就可以类比着唱流行歌曲。以上例子都存在极大的相似性,所以可以进行迁移学习。迁移学习,是指利用数据、任务、或模型之间的相似性,将在旧领域学习过的模型或知识,应用于新领域的一种学习过程[2]。
在大数据的时代,每天每时都会产生大量的数据。对于机器学习模型,数据不断增加,可以不断更新模型,达到更好的学习性能。然而存在一个问题:缺乏数据的标注。在现实生活中,机器学习已得到广泛应用。但是存在一些问题。比如推荐系统如果没有大量的数据,就不能准确的推荐。再比如图片的标注系统没有大量的标签,就不能准确的服务。传统的机器学习方法无法解决上述问题。迁移学习可以解决上述难题。研究人员期望迁移学习可以顺利进行。然而,事情却并不总是那么顺利。这就引入了迁移学习中的一个负面现象,也称为负迁移。迁移学习的研究重点是,找到研究问题的相似性。只有发现它们的相似性,才能顺利地进行迁移学习任务。如果两个研究问题之间没有相似性,那么迁移学习的效果可能不是很理想。迁移学习领域权威学者、香港科技大学杨强教授发表的迁移学习的综述文章[2]给出了负迁移的一个定义:负迁移指的是,在源域上学习到的知识,对于目标域上的学习产生负面作用。出现负迁移的原因有:1、数据问题:两个研究问题完全不相似。2、方法问题:两个研究问题是相似的,但是,迁移学习方法不够好,没找到可迁移的成分。迁移学习应用领域广泛,例如对于动作的识别[3],对于计算机的视觉方面[4,5],对于文本的相关分类[6],对于自然语言的处理[7,8,9],对于医疗方面的运用[10]等。近年,迁移学习问题的研究已经成为热门话题,大量的研究成果相继涌出,相关成果将在下一节详细介绍。
.................................
1.2 研究现状
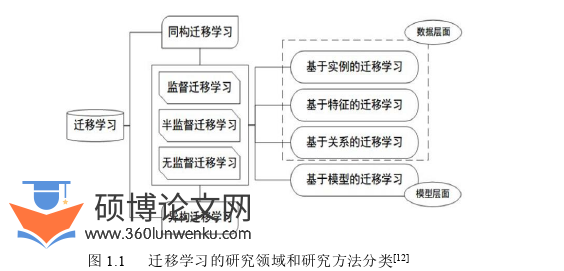
机器学习分为有监督、半监督和无监督机器学习三大类方法[11]。同理,迁移学习也能如此分类。根据当前较为主流的方法对其进行划分[12]。图 1.1 展示了迁移学习的分类方法。
软件工程论文参考
迁移学习有四个分类准则:按目标域有无标签分、按学习方法分、按特征分、按离线与在线形式分。按目标域有无标签划分,迁移学习主要分为三类:监督迁移学习(Supervised Transfer Learning)、半监督迁移学习(Semi-Supervised Transfer Learning)[13,14,15]和无监督迁移学习(Unsupervised Transfer Learning)[16,17]。按方法分类主要分成四类:基于实例的迁移学习方法(Instance based Transfer Learning)[18,19]、基于特征的迁移学习方法(Feature based Transfer Learning)[20,21]、基于模型的迁移学习方法(Model based Transfer Learning)[22,23]和基于关系的迁移学习方法(Relation based Transfer Learning)[24,25]。基于实例的迁移,前提是源域和目标域的数据是相似的,将源域和目标域的数据进行权重重用,实现迁移。基于特征的迁移,前提是源域和目标域的特征原来不在同一个空间,而如果可以把它们变换到一个空间,特征就会相似。基于模型的迁移,构造参数共享的一个模型。基于关系的迁移为挖掘和利用关系进行类比迁移。按特征主要分为两类[26]:同构迁移学习(Homogeneous Transfer Learning)[20,21]和异构迁移学习(Heterogeneous Transfer Learning)[27,28]。例如,不同图片的迁移,就是同构;而图片到文本的迁移,则是异构。按离线与在线形式分为两类:离线迁移学习(Offline Transfer Learning)和在线迁移学习(Online Transfer Learning)。目前,迁移学习方法大多数采用了离线方式,迁移一次即可。缺点为新的数据无法被加入算法来学习,模型也不能被实时更新。但是在线方式,新的数据可以被加入算法来学习,模型可以得到实时更新。
.................................
第二章 课题研究基础
2.1 问题形式化
迁移学习的问题形式化,是进行一切研究的前提。它有两个基础的概念:领域(Domain)和任务(Task)。领域(Domain)是研究的对象,由两部分组成:数据和它对应的概率分布。如果用符号来表示,域用大写斜体????来表示,概率分布则用大写斜体????表示。迁移学习有两个基本的领域:源域(Source Domain)和目标域(Target Domain)。源领域为有丰富监督信息的领域,是要迁移的对象;目标领域为赋予标签的对象。把源领域的信息迁移到目标领域,就是迁移学习。对于领域的数据表示,用小写粗体????来表示,它也是向量的一种表示方式,比如ix 为第????个样本或特征。用大写的黑体????表示一个领域的数据,这是一种是矩阵表示方式。符号????是数据的特征空间。两个领域的符号表示为小写下标????和????。把它们和领域的表示方式结合起来,可以得到 s 是源域, t 是目标域。任务 (Task): 是学习的目标。可以将其划分为两部分:标签和它相应的函数表示。符号????是标签空间,符号????是学习函数。源域的类别空间为s和目标域的类别空间为t,同理,源域的类别数目为 ys和目标域的类别数目为 yt。
软件工程论文怎么写
.........................
2.2 基本方法
领域适应的一个重要分支为无监督领域适应,它在前人的总结下,可以大致分为两类:传统无监督领域适应和深度无监督领域适应。接下来,将会重点介绍与研究内容相关的无监督领域适应方法和工作。
2.2.1 传统无监督领域适应
目前已有大量无监督领域适应方法相继涌现,主要分为四种:基于样本的迁移学习方法根据一定的权重生成规则,对数据样本进行重用,进行迁移学习。基于模型的迁移方法是指从源域和目标域中找到两者共享的参数信息,从而实现迁移的方法。这种迁移方式要求的假设条件是:源域中的数据与目标域中的数据可以共享一些模型的参数。基于关系的迁移学习方法比较关注源域和目标域的样本之间的关系。基于特征的迁移方法是指采用特征变换的方式相互迁移,从而缩小源域和目标域的差距;或者将源域和目标域的数据特征变换到统一特征空间中,然后利用传统的机器学习方法进行分类识别。基于特征的迁移学习方法是迁移学习领域中最热门的研究方法,可以将其划分为三类方法,分别包括数据分布自适应、子空间学习和特征选择。下面将系统介绍它们的基本思想以及相关领域成果。
(1) 数据分布自适应
数据分布自适应(Distribution Adaptation)的基本思想是,因为源域和目标域的数据概率分布不相同,所以可以采用一些变换,将不同的数据分布的距离拉近。从图 2.1 中可以看到几种数据不同的分布情况。具体来说,如果从整体上看,数据不太相似,可以理解为它们在边缘分布上是不太相同的。如果数据的类条件分布不一样,这表示从整体上看,数据相似,但是对于类内的数据而言,它们是不太相似的。
...........................
第三章 基于判别感知对抗神经网络 ............................... 15
3.1 问题描述 ......................................... 15
3.2 相关工作 ............................................ 15
第四章 基于语义信息的无监督领域适应 ........................... 27
4.1 问题描述 ....................................... 27
4.2 相关工作 ....................................... 27
第五章 总结与展望 ................................ 38
5.1 总结 ................................. 38
5.2 展望 ............................................. 38
第四章 基于语义信息的无监督领域适应
4.1 问题描述
在现实生活中,由于人工标注的标签代价比较大,将知识从标记丰富的源域转移到未标记的目标域是非常重要的。现有方法通过调整源域和目标域的全局分布统计信息来解决这一问题,但是忽略了样本中的语义信息,例如目标域中背包的特征可能被映射到源域中汽车的特征附近。这点非常重要,为了将源域和目标域进行域适配,考虑到有三种重要的信息,分别包括数据语义信息、域标签和类标签。现有的领域适应方法通常只利用了上述一种或两种信息不能使它们相得益彰。研究人员对于聚类提出很多方法,例如 K-means 聚类[76]和谱聚类[77],这对于数据的处理有极大的意义。
为了解决以上难题,本章提出基于语义信息的无监督领域适应(SCAN)。试图在深度模型中联合建模数据语义信息、域标签和类标签来适应。首先,在无监督域适应的深度模型中采用聚类方法处理样本语义信息,其次对所提出的模型进行三种对齐机制包括样本语义信息的对齐、域对齐和类质心对齐,可以学习域不变性和语义,以有效减少域差异。实验结果表明了该方法的良好性能。
..........................
第五章 总结与展望
5.1 总结
在大数据的时代,每天每时都会产生大量的数据。对于机器学习模型,数据不断增加,可以不断更新模型,达到更好的学习性能。但是绝大多数的信息都没有标注,这就导致人工标注费时和费力的,甚至还花费好多钱。此时,迁移学习的出现可以帮助解决这一难题,迁移学习是利用已经学习到的知识迁移到新的领域中。 近年,领域适应已经成为一个热门的研究领域。目前领域适应主要利用源域上的丰富注释从而实现目标域上的强大性能,而不管注释的好坏。然而,仅在源域上训练的模型在目标域显示出本质上不同的特性时会产生以下不足: 第一点是它只考虑域之间的整体对齐,而没有考虑域间的类间区分信息。第二点为忽略了样本中包含的语义信息,例如目标域中背包的特征可能映射到源域中汽车特征附近。这样可能会导致负迁移。
首先简单介绍了机器学习的发展,其次介绍了迁移学习的发展,研究热门方向及国内外的研究成果,然后提出本文的相关研究内容,最后呈现本文的脉络框架。然后,提出本文第一个研究工作。领域对抗神经网络(DANN)方法近年来得到了广泛的关注。在 DANN 中,一个判别器被训练来区分由生成器生成的特征的域标签,而生成器试图混淆特征,使得域之间的分布是一致的。因此,DANN 实际上鼓励了域间的整体对齐,而没有考虑域间的类间实例的差异。本文提出了一种判别感知的域对抗神经网络(DA2NN)方法,将判别知识或跨域类间实例的差异引入深度领域适应学习中。考虑了多个判别器实现域间的同类知识传递和异类判别感知。实验证明,DA2NN 与 DANN 方法相比,该方法具有更好的分类性能。
其次,提出本文第二个研究工作。对于领域适应,为了连接源域和目标域,有三种重要的信息需要被考虑,分别包括数据语义信息、域标签和类标签。现有的领域适应方法通常只利用了上述一种或两种信息不能使它们相得益彰。与现有方法不同,提出一种基于语义信息的无监督领域适应。试图在深度模型中联合建模数据语义信息、域标签和类标签来适应。首先,在无监督领域适应的深度模型中采用聚类方法处理样本语义信息,其次对所提出的模型进行三种对齐机制包括样本语义信息的对齐、域对齐和类质心对齐,可以学习域不变性和语义有效减少域差异。实验证明,该方法具有良好的性能。
参考文献(略)