本文是一篇软件工程硕士论文,本文首先介绍了国产大数据一体机中实时流数据预测的研究背景和国内外现状以及选择基于Spark平台进行研究,并将其部署在国产芯片大数据一体机上。然后本文在第二章的论文相关理论和技术基础中介绍了实时流处理平台 Spark Streaming、Kafka 以及支持向量机、梯度下降法和大数据集群监控 Ganglia、Nagios的相关理论知识。
第一章 绪论
1.1研究背景和意义
随着我国城市私家车保有量的增多,交通拥堵问题越来越严重[1]。对于正日益凸显的当前我国各大城市交通出行拥堵突出问题,专家们和学者们正在积极地探索并着力于积极进行城市交通拥堵车流量的预测分析研究,以期彻底解决这一突出问题。在上世纪 60 年代一些学者已经开始对有关道路交通工具运行安全状态的识别方法技术进行了深入的理论研究,研究的识别方法和技术种类已经有很多,大致可以分为以下两类:人工识别法和自动识别法[2]。人工识别法是指出行人通过对道路堵塞情况的自动感知和用识别器来判断道路是否拥堵;交通自动识别法主要是通过自动建立一个以道路交通流量控制参数为主要物理测量数据参数的交通函数测量关系来自动判断交通路面的各种交通拥堵状态。随着现代人们科学研究的深入和现实中的需要,自动识别法的发展极为迅速。其中的代表是城市交通控制系统 UTCS(Urban traffic control system)[3],UTCS 从根据历史数据分析预测发展到经过修正的城市历史数据分析预测最后快速发展到使用实时的城市历史数据分析预测经历了三代的发展,但是这些数据预测和计算法都或多或少地可能存在一些技术问题。
为了在尽可能短的时间内对大量的城市交通流进行挖掘和综合分析,实时预测出一种城市短时交通流运行状态,构建有效的城市交通规划体系,改善其城市交通管理水平,本文需要搭建一个高效的大数据平台对大量的交通流数据进行预处理并提供之后对于城市交通流预测算法的提交平台。如何选择大数据平台变得尤为重要。随着专家学者对大数据框架的跟进研究,发现在综合考虑实时性、计算能力、分布式可拓展性和容错能力这些因素之后,Spark 计算框架成为新一代计算框架中研究的热点[4]。然而,如何对国产服务器集群进行性能监控和数值分析成为难题。主要是因为在国产服务器中,龙芯用户的配置不当或者国产集群资源分配不公平等都可能会造成系统性能下降。
.............................
1.2 国内外研究现状
在上世纪 70 年代,交通流预测算法已经开始在国外进行研究。Nicholusn H.等[8]人在 1975 年探讨了预测交通流算法模型可以谱分析。同时 Amhed S.A.等人探讨其他可以用来预测高速公路车流量的算法模型,于是开始用 Box-Jenkins 技术,但实验结果发现模型的预测精度不高,达不到想要的高精度结果,于是在1980 年提出了时间序列技术在交通流量中的应用[9],可以达到预测高精度效果。Min 等人[10]也在实时交通流预测领域提出时间序列。再一次应用 Box-Jenkins 技术进行预测是 Nihan N.L.等人在 1981 年用测量的某路段 4 年的交通数据进行实验,结果发现预测精度进一步提高。因此可以看出,时间序列技术 Box-Jenkins方法的使用条件较为苛刻,它需要大量历史数据,同时对建模者本人的知识水平与建模技巧要求高。到了上世纪 90 年代,Davis G.A.等人在前人的研究基础上提出了用可调整的预测系统来预测高速公路的交通量,并由此判断交通是否拥堵[11]。同年还建立了更高级的可调整预测系统,不仅应用于高速公路交通的预测,还应用于城市交通路网的数据收集和实时预测等领域中。使用滤波技术来预测交通流的状态也是专家学者研究的热门。
上世纪 90 年代,交通流预测算法模型研究越来越受到学者的青睐,1992 年,Nihan 和 Davis 不满足于时间序列模型,于是他们建立了非参数回归预测模型,实验证明该模型的预测精度要优于时间序列模型。两年后,越来越多的专家学者们加入到交通流预测算法研究中来。其中起到里程碑作用的是 Brain L.Simith 等人,他们利用 BP 神经网络来建立预测模型并且经过实验结果分析表明 BP 神经网络的模型具有很高的预测精度。之后神经网络技术日趋成熟,在 90 年代中期,Maschavan DerVort 等人将之前发展成熟的 ARINA 时间序列预测模型[14]与热门的神经网络模型相结合[15],这样可以增强 ARINA 模型的移植性和适应能力。1998年,H.Kirby,M.Dougherty 等人再次建立神经网络模型研究高速公路短时交通流量预测[16]。
...............................
第二章 论文相关理论及技术基础
2.1大数据实时流处理平台
2.1.1 Spark Streaming 的相关技术
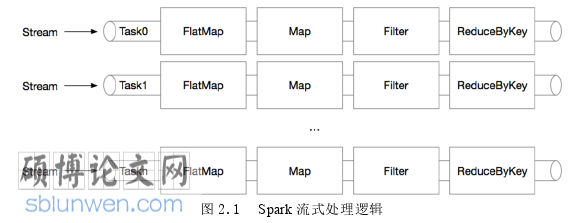
Spark 是 UC Berkeley 的 AMP Lab 于 2009 年发起的,基于弹性分布式内存数据集(RDD)实现的分布式计算框架[24]。Spark Streaming[25]是 Spark 核心 API 的一个扩展,它在处理数据流之前,会按照时间间隔对数据流进行分段切分成DStream(Discretized Stream),由于切分的时间间隔可以自主操控,当时间间隔定义为秒时,Spark Streaming 可以达到秒级响应即实时处理。DStream 是小批处理的 RDD(弹性分布式数据集), RDD 则是分布式数据集,可以通过任意函数和滑动数据窗口进行处理,实现并行操作。
Spark Streaming 可以实现高吞吐量的、具备容错机制的实时流数据的处理。其支持从包括 Kafka、Flume、Twitter 以及 TCP sockets 等多种数据源获取数据,紧接着可以对数据进行复杂的处理比如使用 map、reduce、join 和 window 等高级函数。最后还可以将处理结果存储到 HDFS 文件系统或者 Redis 内存数据库等。Spark Streaming 的数据读取方式分为基于 Direct 的方式和基于 Receiver 的 Kafka数据消费模式。基于 Direct 方式的数据消费对内存的要求不高,只需要考虑批量计算所需要的内存即可,同时 Batch 任务堆积时,也不会影响数据堆积;基于Receiver 方式的数据读取需要专门的 Receiver 持续不断的异步读取 Kafka 的数据,读取事件间隔以及每次读取 offsets 范围可以通过配置文件进行参数调整,读取的数据会通过队列保存在 Receiver 中,当 driver 触发 Batch 任务的时候,Receiver中的数据会转移到剩余的 Executor 中去执行。在执行完之后 Receiver 会相应更新 Zookeeper 的 offsets[26]。
软件工程硕士论文怎么写
..........................
2.2支持向量机 SVM
2.2.1 线性 SVM
支持向量机(support vector machines,SVM)是一种二分类模型[31],它的基本模型是定义在特征空间上的间隔最大的线性分类器,间隔最大使它有别于感知机[32],建立在统计学习的 VC 维 (Vapnik-Chervonenkis Dimension) 理论和结构风险最小原理基础上[33],擅长解决具有小样本、高维数、非线性特点的分类问题,而且很少过度拟合,适合应用于文本分类领域。但面向大规模数据集时,由于该算法计算复杂度高,会导致计算时间大大增加。SVM 还包括核函数,这使它成为实质上的非线性分类器。SVM 的学习算法就是求解凸二次规划的最优化算法[34] ,它的学习策略就是间隔最大化,可形式化为一个求解凸二次规划的问题,也等价于正则化的合页损失函数的最小化问题。
SVM 算法基本原理是求解分离超平面,对于线性可分的数据集来说,这样的超平面有无穷多个,但是能够正确划分训练数据集并且几何间隔最大的分离超平面却是唯一的。???????? + ???? = 0即为分离超平面。
对于非线性 SVM 分类问题,可以通过非线性变换将非线性 SVM 分类问题的转化为某个维度特征空间中的线性 SVM 分类问题。在上一节的线性 SVM 学习的对偶问题里,目标函数和分类决策函数都只涉及实例和实例之间的内积,因此不需要显式地指定非线性变换,而是使用核函数替换当中的内积[37]。
梯度下降法[39]作为机器学习中较常使用的优化算法,其有着两种不同的常用形式:批量梯度下降(Batch Gradient Descent)、随机梯度下降(Stochastic Gradient Descent)。梯度下降法是求解无约束最优化问题最常用的方法,它是一种迭代方法,每一步主要的操作是求解目标函数的梯度向量,将当前位置的负梯度方向作为搜索方向[40]。梯度下降法特点:越接近目标值,步长越小,下降速度越慢。
................................
第三章 基于国产大数据一体机的批量式离线交通流预测算法研究 .............. 22
3.1研究背景 ..................................... 22
3.2相关工作 .............................................. 23
第四章 基于国产大数据一体机的增量式实时交通流预测算法研究 ..................... 29
4.1研究背景 .......................................... 29
4.2相关工作 ....................................... 30
第五章 系统设计与性能测试 ................................. 39
5.1系统设计 ................................... 39
5.2大数据平台监控预警模块设计 ................................. 42
第五章 系统设计与性能测试
5.1系统设
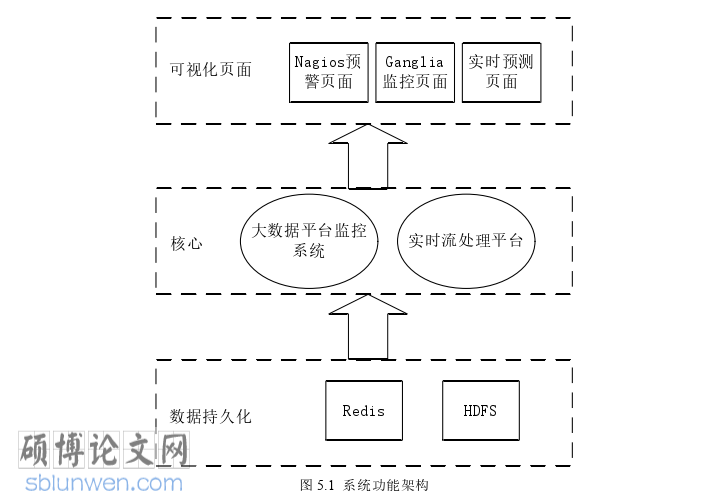
整体系统的功能架构如图 5.1 所示,共分为三层。系统的最上层是可视化的前端页面。用户可以更加方便的对集群进行监管以及各标记的卡口路段历史交通流数据和经过 L-BFGS 预测后的交通流数据直观地展示在页面上。然后最底层为数据持久化模块,这部分主要是基于 Redis 和 HDFS 对交通流数据进行存储管理。持久化模块的上层是项目的两大核心模块:大数据平台监控系统和实时流处理平台。其中,大数据监控系统实现对国产大数据一体机集群所有服务器的监控、预警等功能;实时流处理平台提供交通流预测算法环境,实现数据实时处理和提交预测算法等。
核心模块中的大数据平台监控预警模块设计包括 Ganglia 集群监控和 Nagios预警。启动集群中的 Ganglia 和 Nagios 监控预警系统,得到如图 5.2 三台服务器都 UP 的状态,以及 Services 中服务器的不同监控内容的状态。本章利用三台龙芯服务器搭建集群,一台龙芯服务器主节点作为监控中心节点同时也是 Hadoop的 NameNode、Spark 的 Master 节点。
软件工程硕士论文参考
................................
第六章 总结与展望
6.1总结
本文首先介绍了国产大数据一体机中实时流数据预测的研究背景和国内外现状以及选择基于Spark平台进行研究,并将其部署在国产芯片大数据一体机上。然后本文在第二章的论文相关理论和技术基础中介绍了实时流处理平台 Spark Streaming、Kafka 以及支持向量机、梯度下降法和大数据集群监控 Ganglia、Nagios的相关理论知识。
在论文第三章中,针对城市车辆饱和,交通拥堵等实际问题,本章综合分析现有解决方案的优缺点,提出一种基于国产大数据一体机的批量式离线交通流预测算法,并基于该模型实现交通流处理和预测系统同时在国产大数据一体机上系统部署运行。利用 Kafka 和 Spark Streaming 搭建实时数据处理平台保证了数据实时性,再利用基于梯度优化的 SVM 算法来实现交通流的时空变化趋势分析,与经典的串行算法 LibSVM 算法相比较,梯度优化后的 SVM 算法提高了模型训练速度。
在论文第四章中,针对城市交通难以实时处理大量数据等问题,本章综合分析现有解决方案的优缺点,提出一种基于国产大数据一体机的 L-BFGS 算法,该算法可有效预测网络覆盖区域内未来一段时间的交通数据变化情况,以确定是否存在发生异常事件的可能。与第三章相同使用 Kafka 和 Spark Streaming 解决了在国产大数据一体机实时性弱的问题。再利用基于 Spark 平台的逻辑回归预测算法来实现交通流的时空变化趋势分析,并将预测的结果保存至 Redis 数据库中,提高了模型预测精度和实时性。
最后本章在龙芯大数据一体机上搭建了实验环境,部署了实时交通流数据处理系统和大数据平台监控系统,Ganglia 以图形化界面展示国产服务器龙芯集群的 CPU、内存、磁盘等硬件指标,同时 Nagios 可以通过自定义插件调用 Ganglia监控数据。当 Spark 平台提交异常作业时,Nagios 页面可以预警提示。利用 Ganglia的可视化界面可以平衡集群各节点资源,提高集群各节点资源利用率。同时为第三、四章的算法提供一个良好的集群环境。
参考文献(略)