本文是一篇软件工程硕士论文,本文提出了一种基于改进 SMOTE 自适应安全半监督极限学习机的软件缺陷预测方法。该方法主要是在上面提及方法的基础上对半监督极限学习机在无标记模块的利用上引入了安全度的概念,通过对无标记模块标记安全度,来减少那些对半监督极限学习机分类效果有负面影响的无标记模块的影响。使用这种方法可以进一步提高无标记模块的利用效率,使得半监督极限学习机的分类效果得到显著提升。
第一章 绪论
1.1 缺陷预测的研究背景及意义
二十一世纪以来,人们对电子电器产品的需求日益增加,这些凝聚着人们智慧的产品无一不给人们的生活带来了极大的便利。软件和计算设备无处不在的 2021 年[1],大约有 360 亿个设备连接到互联网[2],可以确保全球 54%的人口能够上网使用各种软件[3]。所有这些设备上运行着的软件数量是非常庞大的。一个典型的例子是 iPhone 应用程序大约有 1 万 5 千行代码,Google 估计的其代码库约为 20 亿行代码[1]。至此人类的生活质量高低已经变得十分依赖于计算设备和软件。
这些设备都是使用软件程序对硬件调用从而实现种种强大功能的。因此软件的质量和可靠性变得十分重要,而软件缺陷则是导致设备系统异常的主要原因之一,稍有不慎可能会造成非常严重的后果。构建软件是一项独特的工程工作,因为它涉及四个不同的特征:复杂性,一致性,可变性和隐形性,每一项都有可能导致软件缺陷的产生[4]。软件缺陷会导致昂贵的财产损失甚至危险的后果比如:单位转换异常产生的软件缺陷导致 NASA 火星气候轨道器的坠毁最终损失价值 1.25 亿美元,一个数字溢出错误使耗资 80 亿美元开发的火箭阿丽亚娜 5坠毁,苏联最大的无核火箭的爆炸也归因于软件缺陷[5]。开发软件需要花费大量的精力和金钱。劣质软件开发的代价也很高[1]。2018 年,全球在 IT 和电信系统上的成本支出约为 4 万亿美元[6],但由于其软件质量较差,仅在美国,这一损失就达到约 2.84 万亿美元[1]。尽管劣质软件成本损失的近 37%归因于软件故障本身,但仍约有 17%用于发现和修复缺陷[1]。再比如:上个世纪九十年代,东欧阿利雅纳-5 航空器因为软件缺陷导致系统故障从而升空数秒后爆炸带来了 30 多亿人民币的损失;二十多年前美国癌症研究中心的放疗机因为软件缺陷造成使用放射量计算失误,导致了数人死亡数十人受伤,并且后来又持续造成多人先后死亡。因此,要想拥有可靠的设备必须找出潜在的设备搭载软件的缺陷[7]。
...............................
1.2软件缺陷预测研究现状
当前,大多数关于软件缺陷预测的研究都是从两个方面进行的:如何建立缺陷预测模型以及缺陷数据集中的相关问题。1992 年,当时的专家学者们首次提出了软件缺陷预测技术(SDP)[8-10]。研究人员对此开始进行了迄今为止长达数十年的研究。这些年来,人们提出了基于机器学习的方法[11]并将其运用于 SDP,并慢慢成为大多数研究者所采用的方法。1997 年,一个通讯系统,包含 1400 万行代码,Allen 等人[12]建立了人工神经网络模型和判别模型。比较这两种模型,他们发现判别模型比神经网络模型有着更好的分类性能。在 2002 年,Summers[13]提出了一种在软件缺陷预测上有效的多层感知器(MLP)方法。同年,Mahaweeawat[14]使用径向基函数(RBF)预测软件缺陷,达到 83%的准确性和 60%的延迟准确性。与 MLP 的高效率和高检验开销相比,RBF 受到了更多研究人员的认可,被广泛运用于缺陷预测研究领域。2008,Lessmann 等[15]比较了二十多种基于机器学习的预测方法,包括统计方法,支持向量机(SVM)算法,决策树方法,最近邻算法(KNN)。最佳性能的机器学习方法之间并没有太大的区别。研究者们首先查看数据集的类分布。其中,传统方法包括过采样和欠采样的采样方法。两种最常用的方法是随机过采样,和随机下采样方法[16]。但是,使用过采样方法,少数类模块的多次复制会导致信息的重复堆砌,并且容易造成分类器过度拟合。下采样方法会降低分类性能,因为相当部分多数类模块被删除会造成训练数据中包含的信息丢失。Chawla[17]及其同事提出了 SMOTE 方法。这种方法用于软件缺陷预测的数据预处理中以缓解类不平衡问题,其基本思路是对少数类模块的分布进行分析,再将人为合成的少数类模块安插在少数类模块分布区域中,该方法解决了传统过采样方法的过拟合问题。Pelayo 及其同事[18]对 SMOTE 方法在实际应用中的效果进行研究,结果证实这个方法可以将缺陷预测模型的分类性能提高 22%。
.........................
第二章 相关背景知识介绍
2.1软件缺陷预测
在本章开头先是对软件缺陷预测的有关概念进行了介绍,接着对缺陷预测研究领域中经常使用的算法模型进行梳理回顾。然后对常见项目内软件缺陷预测进行介绍。最后,细致地论述了本文中提出方法的有关知识,涵盖了初始的极限学习机和加权极限学习机。
2.1.1 缺陷预测相关概念
1)问题描述
将待预测项目模块分为有缺陷和没有缺陷两类,这就是软件缺陷预测(Software Defect Prediction, SDP)。当研究人员使用机器学习相关方法进行缺陷预测时,往往要求有充足的有标签数据来进行训练,然后利用机器学习的相关方法来构建算法模型,最后对待预测数据进行分类。我们熟知的一些度量元,比如代码行数[20],McCabe 环路复杂度[21]和 Hasstead 科学度量[22]等均和软件质量有着千丝万缕的联系[23]。为人所熟知的软件缺陷预测分为两类,即项目内缺陷预测和跨项目缺陷预测。项目内缺陷预测可以较为轻松地使用同一个项目内数据进行模型训练并使用该项目内剩余数据进行测试,满足传统机器学习中训练数据和测试数据分布一致假设。跨项目缺陷预测则是研究不满足传统机器学习假设时的情况,该研究的重点是如何使用源项目中大量有标记数据和目标中相关但是无标记的数据构建算法模型并对目标无标记模块进行较为准确的预测。
2)预测过程
众所周知,软件缺陷预测的宗旨是较为准确地定位出那些有缺陷的软件模块,以便更加精准的对其进行人工测试。SDP 的完整处理过程主要包括四个阶段:数据收集阶段和特征选择阶段和模型构建阶段。在数据收集阶段中,主要通过包含项目源代码以及缺陷的细节和其他软件发展相关的数据的项目数据。在特征选择阶段中,有两种指标或特征从源数据中提取出来,这些指标和特征通常和软件模块的复杂度以及修改次数等有关,将帮助预测缺陷。模型构建阶段,预测模型使用下列三种手段构建:统计,机器学习方法和基于搜索的技术[24],在模型评估阶段,使用训练数据集训练的预测模型将被测试数据集测试其准确度。
................................
2.2极限学习机有关算法
Huang 等人[40]在 2006 年,为了使单隐藏层前馈神经网络具有良好的训练效果,首次公开提出了极限学习机(ELM)的算法模型。传统的反向传播算法[41]是通过算法的迭代对神经网络的权重与偏置向量进行不断调整,而极限学习机则不需要这样操作。它在隐藏层随机生成输入权重和偏置向量的值,最后借助广义逆矩阵的理论数学求解得到输出层的权重,正因为如此极限学习机的学习速度相比较传统神经网络算法快很多,并且部分缓解了传统神经网络算法容易过拟合的问题。
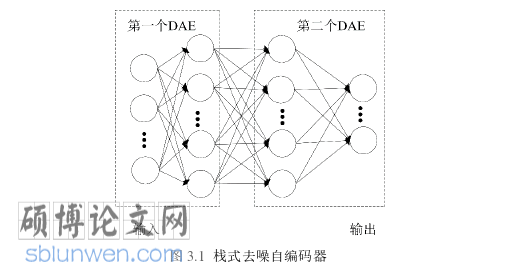
为了缓解模块的类不平衡问题,本章采用了 k-means&SMOTE 进行模块的类不平衡处理。传统的极限学习机只有一个隐藏层,这导致其对于特征的学习能力较其他深度学习方法偏弱。为了弥补极限学习机网络层数少带来的特征学习不充分的问题,本章引入了核函数。其次使用栈式去噪自编码器进行辅助特征提取,不会过多增加时间开销同时进一步解决了特征学习问题。本章先对核方法做简单的介绍,再对本章提出的基于改进 SMOTE 的多核极限学习机算法进行详细的阐述。
软件工程硕士论文怎么写
..........................
第三章 基于改进 SMOTE 的多核极限学习机的软件缺陷预测 ............................11
3.1方法动机与思路 ....................................11
3.1.1 核相关理论介绍 ....................................11
3.1.2 方法模型 .................................. 12
第四章 基于改进 SMOTE 的半监督极限学习机的软件缺陷预测 ............................... 22
4.1动机与思路 ............................. 22
4.2方法介绍 ........................................ 22
第五章 基于改进 SMOTE 的自适应安全半监督极限学习机的软件缺陷预测 ................... 30
5.1动机和思路 ................................... 30
5.2方法介绍 ................................ 30
第五章 基于改进 SMOTE 的自适应安全半监督极限学习机的软件缺陷预测
5.1动机和思路
本章中,提出了一种基于改进 SMOTE 自适应安全半监督极限学习机的软件缺陷预测方法(Adaptive Safe Semi-Supervised Extreme Learning Machine Based on Improved SMOTE, ASELM)。该方法主要是在上一章方法的基础上对半监督极限学习机在无标记数据的利用上引入了安全度的概念[53],通过对无标记数据标记安全度,来减少那些对半监督极限学习机分类效果有负面影响的无标记数据的影响。使用这种方法可以进一步提高无标记数据的利用效率,使得半监督极限学习机的分类效果得到显著提升。下面将详细说明本章方法的动机和思路,并对该方法的详细步骤进行阐述,然后展示该方法在 NASA,AEEEM 和 ReLink 三个数据集上的实验结果,并对这些结果进行分析。最后进行本章小结。

软件工程硕士论文参考
上一章中涉及到的半监督极限学习机可以充分利用无标签数据,解决了有监督极限学习机不能利用无标签数据的问题。但不幸的是,不是所有无标签数据对分类效果具有正向增益,某些无标签数据反而会影响分类的效果。为了缓解这个问题带来的影响,本章引入了安全度的概念。通过算法自动对无标签数据标识安全度来提升半监督极限学习机的性能。
............................
第六章 总结与展望
61.论文工作总结
近几年来,软件缺陷预测吸引着国内外相关专家学者们的目光。目前的软件缺陷预测研究主要面临着以往标记的有缺陷模块不足的问题,通常为了缓解这个问题有的研究者会使用半监督学习来充分利用无标签模块增强训练效果。尽管现有的半监督缺陷预测方法取得了不错的效果,但是仍有很多改进的余地。极限学习机是一种单层前馈神经网络,它可以随机指定输入层的权重值和偏置向量,利用广义逆矩阵理论一次性求解出输出层的权重,从而完成预测模型的构建。极限学习机具有结构简单,泛化性强以及训练速度快等优点。本文的主要研究成果简要概括如下:
首先,极限学习机是一种强大的机器学习算法,但是特征学习能力不够强,本文提出了一种基于极限学习机的多核软件缺陷预测方法。为了缓解模块的类不平衡问题以及更好地帮助特征学习,本文采用了 k-means&SMOTE 进行模块的类不平衡处理与栈式去噪自编码器进行特征提取。
其次,在软件缺陷预测研究的实际应用中充斥着大量的无标记模块,为充分利用这些无标记模块使实际操作具有更高的可行性,本文提出了一种基于极限学习机的半监督软件缺陷预测方法。为了缓解模块的类不平衡问题,本文采用了 k-means&SMOTE 进行模块的类不平衡处理。
最后,本文提出了一种基于改进 SMOTE 自适应安全半监督极限学习机的软件缺陷预测方法。该方法主要是在上面提及方法的基础上对半监督极限学习机在无标记模块的利用上引入了安全度的概念,通过对无标记模块标记安全度,来减少那些对半监督极限学习机分类效果有负面影响的无标记模块的影响。使用这种方法可以进一步提高无标记模块的利用效率,使得半监督极限学习机的分类效果得到显著提升。
参考文献(略)