本文是一篇软件工程论文,本文阐述了如何利用好机器学习以及深度学习的方法,对LBSNs中的兴趣点进行充分挖掘,从而更好地完成用户可能取的下一个位置推荐的任务。
第一章 绪论
1.1研究背景及研究意义
城市化的不断推进给予了人们现代化的生活,科技的持续发展推动了人们日常生活质量的提高,但是例如环境污染、交通拥挤、能耗增加以及规划落后等问题和挑战也随之而来,合理地挖掘与研究城市大数据以解决上述问题越来越收到政府、学者们的重视。与此同时,随着大数据挖掘技术、机器学习尤其是深度学习算法的蓬勃发展,人工智能在大数据预测、规划等相关任务上的优势愈发的明显起来。上海交通大学郑宇教授以城市为背景,将城市与计算机相结合,首次提出了城市计算的概念[1][2],通过城市中产生的多种异构、多模态大数据进行挖掘、融合与分析,以解决在现代化城市中所面临的各种挑战,位置推荐为其重要研究方向之一[3]。
随着移动设备,全球定位系统(Globl Positioning System,GPS)的迅猛发展,基于位置的社交网络(Location-based Social Networks, LBSNs) 逐渐在人们的日常生活中普及。与传统的社交网络相比,LBSNs不仅仅包括了人与人之间的联系,还可以共享人们之间的位置信息,这样一来,线上社交与线下社交相结合,使得虚拟网络与现实生活相结合,在推动社交网络向前发展的同时也促进了社会生活的进步。如Twitter、Foursqure这样的主流社交应用是LBSNs的典型代表,它们每天都在产生TB级别的时空数据,这些数据通常以GPS数据或签到数据(check-ins)的形式记录下来。在这些数据中,不仅包含了普通的社交网络中所包含的用户与用户之间的朋友关系,还蕴含着时间信息(时间戳),空间信息(经纬度),语义信息(位置类别、评论留言、图片视频等)等各种各样结构相依,模态不同的信息。这些信息既是个人行为习惯与偏好的体现[4],也在一定程度上反映了一座城市中人们的生活方式和移动模式。基于以上各种类型的数据,位置推荐应运而生。
...........................
1.2论文研究内容
本小节主要介绍论文研究的三个方面的内容(1)如何根据用户历史移动轨迹对社交网络中的兴趣点进行挖掘,使用深度学习的方法,得到含义丰富的兴趣点深层表示,(2)如何在(1)得到的兴趣点表示经过神经网络的处理,反映出用户偏好表示,并根据兴趣点表示和用户偏好表示对用户推荐其可能感兴趣的位置。(3)在此基础上,在大型的真实数据集上进行验证。
(1)兴趣点挖掘:提出了两种基于图嵌入的兴趣点生成模型。第一个是基础的兴趣点Embedding生成模型,首先根据特定的时间分割规则提取用户移动序列,接着构造兴趣点-兴趣点有向图,然后应用随机游走的思想对用户移动序列进行重新排列组合,最后采用Word2Vec[5]中Skip-gram模型,得到社交网络中所有兴趣点Embedding集合。第二个是改良的兴趣点Embedding生成模型,为了应对数据稀疏与冷启动的挑战,在上述基础生成模型的基础上引入了兴趣点辅助信息,同时根据不同辅助信息所占权重的注意力机制将兴趣点辅助信息与兴趣点融合,完成了对进阶兴趣点挖掘模型GESI(Graph Embedding with Side Information)的构建,为下一章工作位置推荐提供便利。
(2)位置推荐:提出了基于编码器-解码器框架的位置推荐模型GE-ED(Graph Embedding with Encoder-Decoder)。社交网络中的用户存在着长期兴趣偏好与短期兴趣偏好。为了精准挖掘出用户偏好,该模型首先采用了全局编码器捕捉用户长期兴趣偏好,再使用了局部编码器捕捉用户短期兴趣偏好,随后将二者融合生成用户特征向量,接着引入(1)中模型所生成的兴趣点特征向量,最后将用户特征向量与兴趣点特征向量输入解码器中进行位置推荐。
(3)实验验证:对本文提出的兴趣点挖掘模型GESI和位置推荐模型GE-ED,在一个大型真实数据集Foursquare中超过48万条签到数据集上进行了实验,并将实验结果与基准模型进行了对比分析,证实了本文所提出的两种模型融合后的优越性。
................................
第二章 相关背景知识介绍
2.1兴趣点挖掘的相关工作
2.1.1 Embedding的相关工作
One-hot编码,又称为独热编码,是一种在科研界普遍使用的用于离散数据的一种表示,假设任务需要表示的样本类别总数为N,那对于每个类别,其都可以用N-1个0以及一个1组成的向量来表示。如此表示的缺点在于,如果样本总数非常大,列如牛津高阶英汉双解词典中的单词数量高达8万条,这样每一个单词表示都是一个维度极高且十分稀疏的向量,另一方面,这样的编码映射之间是完全独立的,不能显现出不同样本类别之间的联系。相比之下,Embedding在映射表示方面表现优秀。
在神经网络中,Embedding表示又称为嵌入,是一个将高维离散数据转换为低维且内涵丰富的低维连续向量表示的一种方式。谷歌公司的Mikolov等人于2013年在NLP(Natural Language Processing,NLP)自然语言处理领域首次提出了Word2Vec[5]的概念,其所使用的两种词向量模型结构CBOW和Skip-gram,不仅让词向量的发展达到了前所未有的高度,更开创了Embedding技术发展的先河。Xin[6]在Word2Vec的基础上,对其技术细节进行了详细的分析和阐述,除了对原始的两个词向量模型CBOW及Skip-gram模型参数进行介绍,还详尽揭示了Hierarchical Softmax分层Softmax和Negative Sampling负采样的训练过程。
Barkan等人将Word2Vec的思想拓展到了推荐系统领域,提出了模型Item2Vec[7],其在基于物品的协同过滤基础上将所有物品映射到一个隐空间中,使得在用户信息不完善的情况下仍然能够很好地表示物品于物品之间的联系。Airbnb公司Grbovic[8]等人通过对用户浏览和预定的房源进行嵌入学习,得到了包含地理位置、租赁价格、房屋类型以及建筑风格等含义丰富的房源Embedding,根据所得到的Embedding之间的相似性进行房源推荐以及实时的个性化搜索,大幅度提高了推荐的时效性和准确性。
...............................
2.2位置推荐的相关工作
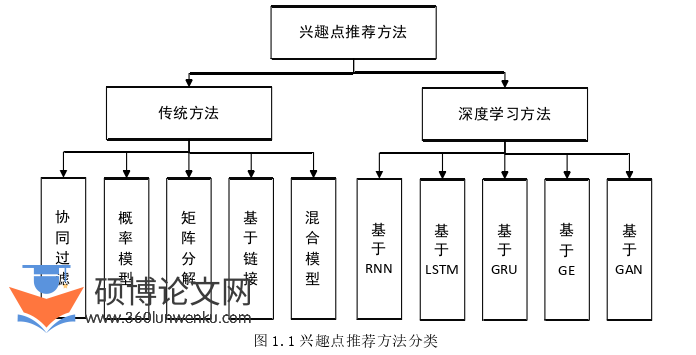
在LBSNs中,有许多种类型的推荐任务,例如朋友推荐、活动推荐以及位置推荐等等。其中,位置推荐即对用户在社交网络中留下的签到记录进行研究与分析,从用户历史移动轨迹中探索和挖掘出用户的移动特征、兴趣点的特征,从而对用户的下一个可能前往的位置进行个性化推荐。如图1.1所示,目前主要的研究方法分为传统的位置推荐方法和基于深度学习的位置推荐方法。
软件工程论文怎么写
2.2.1 传统的位置推荐方法
传统的位置推荐方法可以分为以下五种:
(1)基于协同过滤的方法。该方法基于这样的基本思想:如果两个用户或者位置的兴趣相似,则这两者的相似度也高,通过这样的相似度计算来对用户进行下一个位置推荐。Gregory[14]等人综合考虑了用户偏好,社交因素以及地理位置的影响,在协同过滤的基础上提出了UPS-CF算法,将用户分为本地居民与外地居民,然后再进行推荐,提高了推荐的精度。
(2)基于概率模型的方法。这种方法的思想为:用户-POI这样的签到矩阵分布符合特定的概率分布模型,如高斯分布。Cheng[15]等人基于对用户签到数据的观测,发现大部分用户的签到点集中在家与公司两个地点,于是提出了一个多中心的高斯分布来对用户移动轨迹进行建模,从而进行了高质量的推荐。
(3)基于矩阵分解的方法。该方法将用户签到矩阵分解为用户矩阵U和兴趣点矩阵V两个矩阵,从U和V种可以分别得到所用用户和兴趣点的潜在表示向量,即Embedding表示,通过两种向量内积计算结果给所有位置排序,为用户推荐排名靠前的位置。Cheng[16]等人提出了一种基于矩阵分解和马尔科夫链(Markov Chain, MC)的模型FPMC-LR,一方面依据矩阵分解对所有用户的整体移动偏好进行学习,另一方面又通过兴趣点转移矩阵的马尔科夫链来挖掘出人们在时间维度的移动模式,最后将两者结合实现了高效地位置推荐。
................................
第三章 基于图嵌入的兴趣点挖掘 .................... 13
3.1基本的兴趣点特征生成模型 .............................. 13
3.1.1 提取用户轨迹 ....................... 14
3.1.2 兴趣点有向图构造 ........................... 14
第四章 基于编码器-解码器模型的位置推荐 ..................... 20
4.1GE-ED模型结构 ..................................... 20
4.2基于编码器的用户特征生成模型 .............................. 21
第五章 实验及分析 ................................. 29
5.1实验配置 ........................................... 29
5.2数据集介绍 .......................... 29
第五章 实验及分析
5.1实验配置
本文的实验依托于Linux环境下开发,其操作系统为Ubuntn 18.04.3 LTS,CPU为Intel(R) Xeon(R) E5-2690 v4 @ 2.60GHz,内存为128G,GPU为NVIDIA Tesla K40C,显存大小为12G。本文基于图嵌入的兴趣点挖掘模型是基于深度学习框架Tensorflow进行开发,版本为1.14.0基于编码器-解码器模型的位置推荐是基于Pytorch进行开发,版本为1.2.0。CUDA版本为10.0,Python版本为3.6.8,Numpy版本为1.16.0,pandas版本为0.25.3。
本文所使用的是一个典型的LBSNs数据集Foursquare[56],其中包含了美国加利福尼亚州中众多城市于2010年4月至2011年9月的用户签到记录。其基本数据如下表所示。该数据集包含7个维度信息。

软件工程论文参考
..............................
第六章 总结与展望
6.1研究工作总结
随着城市计算与人工智能的发展,城市中的大数据量增长迅速,基于位置的服务近年来不断发展壮大,其中基于位置的社交网络中的位置推荐为其重要任务之一。本文阐述了如何利用好机器学习以及深度学习的方法,对LBSNs中的兴趣点进行充分挖掘,从而更好地完成用户可能取的下一个位置推荐的任务。本文的主要工作如下:
(1)首先,根据对兴趣点挖掘工作的分析研究以及结合以往的研究方案,提出了综合考虑兴趣点本身及其辅助信息,并将其很好地进行了融合的兴趣点特征生成模型GESI。该模型基于图嵌入与权重分配机制,经过提取用户轨迹、构造有向图以及随机游走等策略,生成了高质量的兴趣点特征向量,为后续章节的位置推荐模型提供便利。
(2)接着,根据位置推荐工作以及编码器-解码器框架相关工作的研究分析,结合前人思想,提出了一个基于编码器-解码器的位置推荐模型GE-ED。该模型采用全局编码器捕捉用户长期兴趣偏好,局部编码器挖掘用户短期兴趣偏好,二者融合得到了含义丰富,精准反映用户偏好的用户特征向量。在此基础上,该框架融入了(2)中GESI生成的兴趣点特征向量,二者联合输入解码器中,为GE-ED模型产生了较为精准的位置推荐。
(3)最后,在一个真实的LBSNs数据集Foursquare上对引入了GESI兴趣点向量的基于编码器-解码器位置推荐模型的精度进行了测试,并在不同的场景下设计了不同的实验方案。通过实验结果表明,本文的位置推荐模型GE-ED相比于baseliine方法在Accuracy@k上有着较好的表现,在各种实验方案中,GE-ED的位置推荐精度、效率都综合评价最优。
参考文献(略)