本文是一篇软件工程论文,本文重新回顾了年龄编辑任务,在本文的第一章和第二章做了详细的介绍引入,并对研究背景和基础进行了综合性的论述,以其全局性的重要特点为切入,引入了近两年新颖的视觉生成领域的Transformer结构。
第1章 绪论
1.1 研究背景和意义
随着互联网的发展和移动设备的普及,人脸图像的拍摄采集、编辑生成随处可见,人们在日常生活中接触人脸属性编辑的场景也非常多。人脸年龄编辑作为人脸属性编辑的关键分支,有着十分重要且广泛的应用场景:在智慧影视领域,后期渲染中利用人脸年龄编辑的相关技术,可以模拟制作演员在特定年龄段的肖像[1];在娱乐社交领域,用户使用年龄编辑技术可以美化照片、看到小时候的或变老了的自己;在公安刑侦领域,对天网捕获的人脸图像进行年龄编辑与生成后,可以用来辅佐追捕长时间逃亡的罪犯[2];利用海量的人脸图像,年龄编辑联合亲属关系验证技术可以辅助寻找遭受拐卖或走失的儿童[3]-[5]等。因此,作者在充分地调研后得出:人脸年龄编辑技术不仅在一定程度上推动了人脸识别、人脸反欺骗等相关领域[6]的发展,也在维护社会治安、丰富社交生活等方面发挥着不可忽视的作用。

软件工程论文怎么写
人脸年龄编辑技术能够生成参照人脸图像在不同年龄阶段的照片并保持编辑人脸图像的关键属性信息(身份、性别)不受篡改,伴随着生成对抗网络[7](Generative Adversarial Network,GAN)和图像翻译技术(Image-to-Image Translation)[8]的蓬勃发展,在人脸图像年龄编辑的生成多样性(quality & quantity)和真实度(Photorealistic)上有了较大的进展和突破;而年龄编辑的实际应用场景中,由于目前还没有数据集囊括了大跨度的不同人种的连续年龄人脸图像,导致人脸年龄编辑的效果和质量以及速度都有所欠缺,比如,要求生成的图像围绕着连续年龄的变化,不仅要在细节和质量方面能够达到既定的要求(评价指标),还要使得模型能够适应肤色、头型、五官等差异较大的不同人种的年龄编辑需求(鲁棒性),这些都是年龄编辑领域具有挑战性和创新性的工作。因此,面对目前人脸年龄编辑的现况,本文基于Transformer[9],充分利用其模块特性,围绕人脸年龄编辑的连续性和跨人种编辑的特定任务,针对上述的问题开展工作,最终设计出了一种能够实现适应跨人种人脸图像的连续年龄编辑模型,该模型能够在较好地保持人脸关键属性一致的前提下,实现人脸图像的老化/年轻化编辑。该研究的人脸年龄编辑技术在影视制作、智慧安防等领域有着良好的应用前景和价值。
............................
1.2 国内外相关研究现状
近年火爆的Transformer结构一直在推进深度学习领域不断向前,并逐渐地从学术研究领域辐射到生活应用中。人脸图像的生成和年龄编辑工作也因其发展而备受启发,在本节,作者围绕视觉Transformer和人脸年龄编辑的关键技术内容进行了分析、整理与归纳,以便为接下来的探索和研究指明方向:
1.2.1 视觉Transformer的研究现状
近年来,视觉Transformer能够在计算机视觉领域独当一面的原因是有迹可循的:Geirhos等人[10]最开始在SIN(Stylized ImageNet)数据集上对不同模型进行了形状特征偏向的测试,普林斯顿大学的Tuli等人[11]又在此基础上继续探讨,将Transformer在特征检测、形状和纹理感知等操作发生时的呈现特征与人类视觉行为进行比对,发现Transformer模型的视觉表现更接近人类(如图1.2所示)。Transformer[12]最开始是用来解决自然语言处理(Natural Language Processing,NLP)中的问题的,直到2018年,在计算机视觉领域(Computer Vision,CV)率先应用了Transformer,Image Transformer[13]的提出,直接带动了一波Transformer在CV领域的研究热潮。可由于Transformer本身的结构性质问题、参数量和固有的应用场景,Transformer一直没有被发扬和发掘。直到2020年,DETR[14]和ViT[15]的出现,敞开了研究视觉Transformer的大门,这两种方法是探讨了Transformer在目标检测和图像分类这两种基础视觉任务上的应用。至此,2020至2021年,Transformer强势袭来,涌现出诸多经典的网络设计思路或流程:包括对Transformer内部结构的改进、前馈和级联的优化、多尺度多通道的提升等[16]- [18]。研究的浪潮中,表现出色的Swin Transformer[19]再度将Transformer推向风口浪尖,Transformer的研究“一发不可收拾”,直至今日,依然是卷积神经网络(Convolutional Neural Network,CNN)最强有力的竞争对手。
........................
第2章 连续年龄人脸图像生成方法概述
2.2 生成对抗网络
2014年,Ian Goodfellow和Yoshua Bengio等人提出了享誉盛名的GAN[7],即生成对抗网络。在此之前,计算机的生成能力总是不被人挂齿而谈,因为在它之前的生成模型,生成能力和稳定性几乎不会引起人们的注意、创作和生成的内容也不具有挑战性。GAN出现之后,计算机仿佛被第二次赋予生成能力,使人们逐渐关注到生成模型,开始对计算机的创造力、生成能力展开研讨。时至今日,人工智能生成创作(AI Generated Content,AIGC)已经风靡全球,而GAN的影响功不可没。
GAN的创作来源是广泛的,不仅受许多基础的编码—解码的网络结构启发,也有来自博弈论的思想。如图2.1所示,基础的GAN网络主要有两个部分:
(1)生成器(Generator),原始的生成器是从随机的高斯噪声中拟合目标图像的数据分布,使得拟合出的数据分布尽可能地和目标图像保持一致,达到同等的数据状态(视觉状态),由生成器生成的图像是假的;
(2)判别器(Discriminator),判别器需要接收来自真实样本和生成样本的输入,其主要作用是尽可能地区分出那些来自生成器的图像。其与生成器二者分工明确,力求纳什均衡[39]Nash equilibrium)的双赢。
GAN的优势明显,具体有如下四点:
(1)GAN不同于VAE[40]的方法,是采取数据拟合的方式来生成目标图像,摒弃了一直以来衡量样本距离、衡量信息损失的生成手段,扩展了生成能力,通常能够得到多样的分布、多样的生成结果,这也是不断有人探索GAN的原因之一;
(2)训练手段简单,只需要设置适当的约束,进行无监督的学习和训练即可,极大地简化了生成过程,不需要预先假设数据分布,可以只从随机的高斯噪声中获取目标结果;
(3)生成速度提升明显,相比于Pixel CNN[41]和WaveNet[42],GAN无需逐像素采样,就能够使用生成器得到目标结果;
(4)GAN的可扩展、可改进性极强,与其他高性能基础网络联动[43][44]。因此,GAN深受众多研究者喜爱。
................................
2.3 生成领域的Transformer
ViT[15]的成功,就如同DCGAN、WGAN的成功一样,不断地推进Transformer的研究热潮,用序列的方式处理图像(如图2.2所示),Transformer便使用超距的视野来提取输入图像的信息,针对全局属性的提取与表征,更容易捕获图像中不同位置、远距离位置之间的特征关系,Transformer的表现一度优异于现有的所有模型。ViT让基础的视觉任务焕发了新的光芒。
在聚焦于ViT时,还要特地回顾生成领域的Transformer,即Image Transformer[13],它首次引入Transformer到CV领域中,它将图像的生成视为自回归的问题,逐步从像素序列回归推断生成像素值。图像中的各个像素值就是序列的上下文信息,只需要利用自注意力关注到生成范围,就能够预测生成像素值从而组成完整的图像,但这样的做法失去了全局的感受视野,可能在生成的表现方面逊于CNN。
Image Transformer作为新颖的生成模型自然有待改进的地方,其计算和存储的成本并不适用于推广生成领域的Transformer。VQGAN[52]的提出,给生成领域的Transformer带来了契机,语义上的引导,类似于cG AN的操作,高质量的像素,可以媲美ProGAN。VQGAN并不是纯粹的Transformer结构,它采用CNN的基础网络进行属性映射,用Transformer来生成图像,两阶段的混合操作,为模型增添了诸多细节信息,而且摒弃了像素级别的回归生成模式,重回宏观的视角,用远程的、长距离的依赖关系生成图像。VQGAN在生成质量上的提升十分明显,把FID值提升了18个百分点之多,而且计算速度还不亚于Image Transformer。
.............................
第3章 基于Transformer的特征映射模型(TPN) ...................... 18
3.1 引言 ..................................... 18
3.2 模型概述 .................................... 18
3.3 核心模块设计 ...................................... 20
第4章 基于渐进式架构的双向年龄编辑生成模型(FormerAge) ...................... 29
4.1 引言 ........................... 29
4.2 模型概述 ........................................ 29
4.3 核心模块设计 ............................... 30
第5章 细粒度的连续年龄人脸图像生成(FormerAge++) .................... 41
5.1 引言 .................................... 41
5.2 模型概述 ..................................... 41
5.3 核心模块设计 ............................... 43
第5章 细粒度的连续年龄人脸图像生成(FormerAge++)
5.2 模型概述
FormerAge是围绕特定的人脸年龄全局属性编辑的任务,人脸年龄属性是人脸属性中的特殊部分,其具有全局性的特点。往广泛了思考,人脸年龄的变换和编辑,与人脸图像风格的迁移如出一辙[26]。Transformer在视觉领域的应用,给类似StyleGAN这一类的风格编辑任务带来了契机。本章提出的FormerAge++,重点围绕人脸年龄编辑中的连续性和跨人种编辑的问题出发,着重关注年龄编辑前后身份一致性的问题,即在整个人脸图像年龄编辑的任务实施中,要尽可能地保持身份信息一致;FormerAge++还从风格约束的角度来进行优化,以新的视角探讨Transformer在图像编辑生成这一下游领域所能展示的强大表现力;FormerAge++还改进了输入、优化了损失约束,并从多个角度进行了比对验证。FormerAge++能够较好地完成连续年龄人脸图像编辑与生成的任务。FormerAge++的模型示意图如图5.1所示:
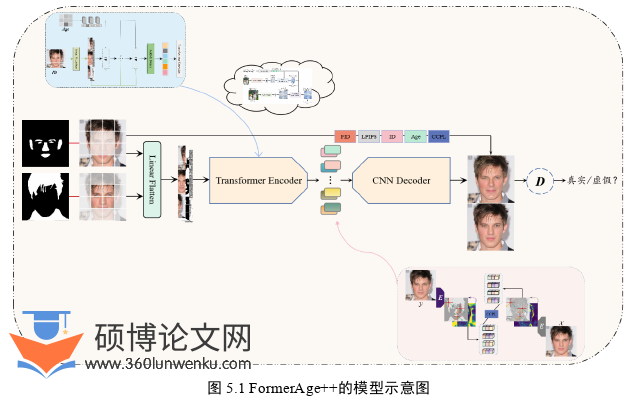
软件工程论文参考
...................................
第6章 总结与展望
本文重新回顾了年龄编辑任务,在本文的第一章和第二章做了详细的介绍引入,并对研究背景和基础进行了综合性的论述,以其全局性的重要特点为切入,引入了近两年新颖的视觉生成领域的Transformer结构,从编码映射、解码生成两端入手研讨,在以下三个方面展开相关实验:
(1)年龄特征本身承载着人脸图像丰富的信息,如身份和全局的属性结构等,在某些认证的任务中,年龄属性是判断其他属性是否真实的先决条件。那么在年龄编辑的任务中,应该如何才能合理把控并实现操作编辑是首要解决的问题。通过详细调研,作者基于在全局特征上有较强表现力的Transformer结构出发,引入新的基于Transformer的映射网络,在本文的第三章,通过实验证明了新的映射结构(TPN)在全局属性表征上性能稳固,在人脸图像重建和人脸图像细节建设的能力上也较为突出,不亚于近年来先进的CNN结构。该部分也是后续开展实验的基础。
(2)年龄编辑任务的目的是得到合理的目标编辑结果,如编辑后的人脸图像要具有目标年龄的面部特征,这就要建立在编辑后的结果是高质量的基础之上。以往数据集和年龄编辑实验产生的质量通常不高,而近年来在其他图像编辑领域有超分辨率崭露头角,FFHQ数据集的出现正契合硬件加速发展的今天。通过前期的研究积累,作者基于渐进式的生成架构,改进了传统的输出生成模式,在生成器的不同层都进行了输入优化,在本文的第四章,FormerAge展现出了它在高清人脸图像生成上的强大表现,在某些以往容易被忽略的年龄编辑任务细节上表现良好,作者开展的实验和对比也验证了所提出模型的有效性。
参考文献(略)