本文是一篇计算机论文,本实验所用参数共享模型可以共享参数明显比不能共享参数的单语言建模方法的性能要好。
第1章绪论
1.1研究背景及意义
人们的沟通方式主要有手势、文字、语音。语音不仅使用起来便捷简单,还可以快速吸引人的注意力,是生活中人与人间交流时最重要也最为常用的手段之一,也是人机交互中一个非常重要的方法,经常被使用在各种各样的应用中,例如导航系统、语音助手(小米的小爱同学、OPPO的小欧、华为的小艺、苹果的Siri等)、语音到语音的直接翻译系统等。
人类语音的产生是一个复杂的过程,首先文字(或概念)被关联到声带等发音器官进而带动有关器官上的肌肉,然后来自肺部的气流经过通道时产生包含非周期性和周期性(声带振动)分量的声源激励信号,通过舌头、声带和嘴唇等对产生的声源激励信号进行一定的调整和滤波,从而改变声音中的幅度和频率,形成人们听到的声音。
最近几十年,计算机硬件技术飞速发展为研究提供了硬件支持,与之同时海量数据的产生为研究提供了数据来源。随着存储技术的不断创新以及新的机器学习算法和理论的出现,深度神经网络已经在机器翻译、计算机视觉、语音识别、语音合成等领域取得了远远超过传统机器学习技术的成绩,在某些领域其水平甚至超过了人类的专家。传统语音合成方法是分模块进行的,深度学习技术凭借优异的性能可以取代其中的某个模块甚至直接取代所有模块完成合成。基于深度学习的端到端模型合成语音的质量不管是在主观评价指标还是客观评价指标上获得的评价得分都比传统方法高。
....................
1.2语音合成研究现状
1.2.1基于传统方法的语音合成
语音合成技术,又称文语转换(Text to Speech)技术,它涉及声学、语言学、数字信号处理、计算机科学等多个学科技术,是中文信息处理领域的一项前沿技术,解决的主要问题是如何将文字信息转化为可听的声音信息,是一种让机器模仿人类说话者发出类似人的语音的技术[3][4]。
第一个基于计算机的语音合成系统出现在20世纪下半叶,早期的基于计算机的语音合成方法包括发音合成、共振峰合成和拼接合成。后来随着统计机器学习的发展,统计参数语音合成(Statistical Parametric Speech Synthesis,SPSS)被提出,它预测语音合成的频谱、基频、持续时间等参数。从2010年开始,基于神经网络的语音合成逐渐成为主要的语音合成方法,并取得了较之前的模型更好的成果。
发音合成(Articulatory Synthesis)通过模拟人类发音器官(如嘴唇、舌头、声门和活动的声道)的行为来产生语音[5]。Cecil H Coker团队在1976年实现了基于发音的合成。理想情况下,发音合成可能是最有效的语音合成方法,因为它是对人类产生语音方式的模拟。然而,在实践中很难模拟这些关节的行为。例如,很难收集到用于发音模拟的数据。因此,通过发音合成方式合成的语音质量通常比后期共振峰合成和拼接合成方式合成的语音质量要差。
P Seeviour团队在1976年发表的文章中完成了基于可控平行共振峰信号的语音合成。共振峰合成(Formant Synthesis)[6]基于一组控制简化的源滤波器模型的规则产生语音,这些规则通常是由语言学家开发的,以使其尽可能地模仿共振峰结构和语音的其他声谱特性。音是由一个附加合成模块和一个声学模型合成的,该模型具有不同的参数,如基频、发声和噪声水平。共振峰合成不需要像拼接合成那样依赖大规模的人类语音语料库,可以用适度的计算资源生成高度可理解的语音,非常适合嵌入式系统。但是合成的语音听起来不那么自然,并且有人工痕迹。此外,很难指定合成的规则。
........................
第2章端到端语音合成模型
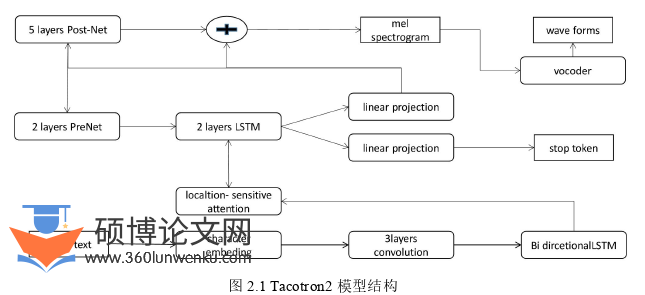
2.1 Tacotron2模型
一个标准的神经网络往往包括输入层、隐藏层、输出层,网络中非线性激活函数的引入使得神经网络具有极强的处理能力。Tacotron2模型由两个模块组成分别是特征预测模块和神经声码器模块。特征预测模块负责从文本到mel频谱的映射,声码器模块负责mel频谱到音频的映射[27]。Tacotron2模型架构如图2.1所示。
计算机论文怎么写
Tacotron2的特征预测模块是一个采用注意力机制的序列到序列框架,旨在更好地将输入文本转换为对应的声学特征。它的特征预测模块由四部分组成,分别是编码器、注意力机制、解码器以及后处理网络。在序列到序列模型框架下很难做到输入序列长度相同,正常情况下输出序列也往往是不等长的。传统的序列到序列的框架模型并没有将注意力机制引入,其往往通过编码器将输入的文本序列编码为一个固定长度的张量,然后这个固定长度的张量被直接送到解码器,由解码器将编码后的张量直接解码为输出序列。这种直接将所有输入信息不论多少直接压缩为一个固定长度张量的方式存在着一定局限性,这种情况下很难找到一个合适的长度来存储充足的输入信息,这会导致在解码过程中解码器由于信息不足出现偏差,提高解码效果需要编码序列包含足够多的信息。此时注意力机制应运而生,引入了注意力机制,编码器不必将输入序列编码为一个指定长度的张量,在解码过程中使用注意力机制选取编码器的输出中与解码器的输入相关的上下文张量,选取结果输入解码器后再进行一个解码操作得到输出序列。声码器的作用是将前面模块输出的声学特征映射到时域波形信号,这一步人们也称之为音频还原。
...............................
2.2多语言模型的参数生成器
2.2.1参数生成器的作用
在局部共享参数的多语言模型中多种语言同时参与训练,网络参数是共享的,训练出来的模型在每种语言上的表现相同,由于在训练时模型受到自各个语言的掣肘所以最终模型在每种语言上的表现性能都不是特别好。
为了完成跨语言的参数共享,还需要保存一部分特定于语言的信息[38]。这里就有了参数生成器的概念。参数生成器接收来自语言的信息,然后把语言向量进行编码,再将编码后经过网络处理的结果与编码器的每一层建立连接。这里编码模块就包含了两部分,原来的编码器和新加入的参数生成器,编码模块的输出由参数生成器和编码器共同决定。编码器本身对于各种语言来说是共享的。而参数生成器生成的参数对于每种语言来说又是唯一的,这样编码模块不仅可以很好地实现参数共享来促进不同语言的知识共享,又可以通过参数生成器生成的参数来保留每种语言独特的信息[39]。
2.2.2参数生成器结构
局部共享参数的多语言模型的编码器中加入了多语言的参数生成器模块,编码器便能够实现高效地跨语言参数共享,编码器的参数是由一个基于语言向量的参数生成器模块生成的,参数生成器模块本身由多个特定于站点的生成器组成,每一个生成器接收输入的语言向量对给定语言的编码器参数进行生成。
生成器的加入使得可控的跨语言参数共享成为可能,减少生成器的大小可以阻止高度特定于语言的参数生成。本文将他们实现为全连接层[40]。
...........................
第3章 多语言模型的数据预处理 ................. 30
3.1 音频时长分布调整 ................ 31
3.1.1 音频失配问题 ............................ 32
3.1.2 缩短音频方案 ......................... 32
第四章 多语言模型研究 ............................ 48
4.1 基于 Tacotron2 的验证实验 .................... 48
4.1.1 语音质量评价指标 ........................... 48
4.1.2 Tacotron2 模型介绍 ........................... 49
第五章 语音克隆与语码转换 ............................. 64
5.1 基于对抗学习的域适应方法 ...................... 64
5.2 语音克隆与语码转换实验模型 ................................ 66
5.3 实验数据 ........................... 67
第五章语音克隆与语码转换
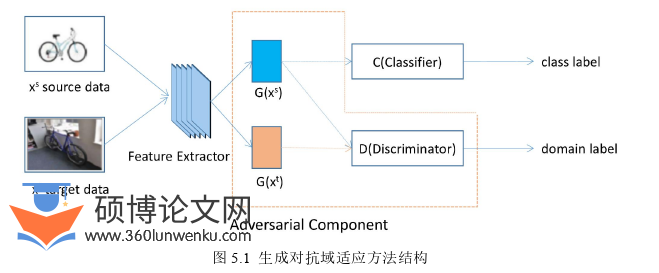
5.1基于对抗学习的域适应方法
生成对抗网络GAN(Generative Adversarial Networks)由Ian Goodfellow等人提出,自被提出以来就被广泛应用于各个领域并不断刷着新各个领域的纪录。域适应领域也同样包括在内,生成对抗网络在域适应领域取得了不错的效果。
域适应是指源域和目标域的分布不一致,如何利用源域的数据在目标域上完成给定的任务。这个现象很普遍比如在图像方面使用合成数据或者半合成的数据训练一个人脸识别系统,系统在真实场景中的表现就很差,这是合成数据与真实数据的分布不一致导致的,域适应方法是迁移学习中的一个经典领域。
计算机论文参考
..........................
第6章总结与展望
6.1研究总结
本实验以藏语为目标语言,使用基于多语言建模的方法对低资源语言的语音合成进行了探究。本实验所用参数共享模型可以共享参数明显比不能共享参数的单语言建模方法的性能要好。从实验中我们发现,本文使用的模型可以高效的共享知识,在目标语言上的学习效率明显提升。本文实验使用的多语言模型添加了参数生成器,模型的网络参数相比为每种语言单独建模的模型的总参数明显要少。本方主要工作如下:
(1)对音频中的静音片段进行了探索并提出了针对音频帧的拼接还原方案。在多语言实验中需要来自不同语言的语料同时参与训练,本实验使用的藏语语料是实验室在完成其它任务时录制的,这批语料在采样率、音频时长等方面与公开的语音合成语料CSS10有较大差距。首先本文对藏语语料中的语音进行了去静音和拼接处理,为了防止VAD(Voice Activity Detection,语音活动检测)对静音的误判以及去除应保留的静音(语音中的正常停顿)导致拼接后的音频品质变差、拼接后的音频在音频时长分布方面与其它语言相差较大,本文在VAD的基础上对语音帧拼接逻辑进行了优化,使得去除静音后的音频听起来更顺畅,在音频时长分布方面与其它语言更接近。然后对模型训练时使用的全部样本(来自训练集中所有语言)的文本长度和对应音频长度做了一个统计分析。当两个样本的文本长度相差不大时对应的音频时长也应相差不大,根据这一准则,本文把文本长度相同的样本划分到一个组,对组中样本的音频时长进行了统计分析,把单个样本的音频时长与该组所有样本音频时长的均值进行比较,通过删除音频时长与均值相差较大的样本来剔除潜在存在问题的样本。
(2)本文从实验和理论两个层面验证了在藏语中选用字母序列做为文本比选用音素系列效果好。本文在Tacotron2上通过实验证明对于藏语选用字母序列做文本,模型合成音频的质量比以音素序列做文本合成音频的质量好。实验中,本文在单语言模型上分别使用音素与字母做为文本来训练模型,然后对合成语音的质量进行主观评估,在这两个实验中使用相同的模型并且设置相同的网络参数,在超参数设置上也保持一致例如两个实验的epochs均设为5000。然后对藏语中选用音素序列与字母序列做为文本的优劣从理论层面进行了分析,最终发现对于藏语而言使用字母序列做为文本要比使用音素序列做为文本更合适。
参考文献(略)