本文是一篇计算机论文,本文主要研究强化学习算法在推荐领域的应用,通过将推荐场景建模为强化学习中智能体与环境的交互过程,从而达到推荐的长期效果最大化。
第一章绪论
1.1研究工作的背景与意义
推荐系统早在上世纪90年代就已经提出,但在最近十年才爆发式的发展。我们日常生活中使用的几乎所有应用、网站,都或多或少的引入了个性化推荐系统。究其原因,是由于信息技术的发展、人们生活水平的提升,导致内容的爆炸式增长,原有的信息组织方式已经无法满足人们获取信息的需求。从互联网诞生之日起,搜索一直是人们获取信息的入口。然而,一方面:内容的增长导致搜索难以准确获取到我们感兴趣的内容;另一方面:移动互联网兴起,各大网站纷纷转移到APP中,并且相互筑起信息的护城河,导致搜索引擎无法检索内容。于是,推荐系统便逐渐替代搜索,成为了新的互联网入口。推荐系统主动的向用户推荐内容,而非被动的返回搜索内容,这降低了用户的使用成本。并且,由于主动推送的特性,系统可以源源不断的推送给用户内容,从而增加用户的使用意愿[1]。
推荐系统的核心是推荐算法。推荐算法通过学习用户过去的历史行为,从海量内容中挑选用户喜欢的内容推送给用户,从而做到千人千面。因此,一个具有高效性、准确性、多样性的推荐算法,是推荐系统的核心技术[2]。强化学习(Reinforcement Learning)是区别于监督学习(Supervised Learning)与无监督学习(Unsupervised Learning)的另一种机器学习方法,强化学习算法通过对环境的探索(获取未知知识)和利用(使用已有知识),来获取利益最大化[3]。目前,随着用户使用推荐系统的时长不断增加,对推荐算法的要求也日益增长,这要求推荐算法除了要具有准确性(推荐用户喜欢的内容),还要有多样性(内容的丰富程度)能力,而这正是强化学习的优势。相比于监督和非监督学习方法,强化学习算法能够更好的对长期反馈建模,并且强化学习的通用性强。目前已广泛的应用到机器人、计算机视觉、博弈、运筹学等领域。因此,强化学习在推荐系统中的应用已成为当前推荐系统领域的研究热点之一,并且,基于强化学习的推荐系统具有很高的使用价值。
......................
1.2国内外研究现状
推荐系统依据其推荐算法,可以分为个性化和非个性化两类,非个性化推荐算法主要使用统计分析数据,通过算法计算得到一个固定且唯一的推荐顺序。例如各大APP中的热门、各类排行榜、今日热点等内容。个性化推荐算法则使用了用户的历史交互数据,对每个用户提供定制的推荐顺序。例如目前各类视频App的Feed流,都采用了个性化推荐算法[5]。
随着推荐系统中对推荐内容运营的需求增加,以及推荐内容量级的指数增长,目前的个性化推荐算法一般会分为召回和排序两个阶段。召回阶段使用一些复杂度较低的算法,从各个数据源中初步筛选出部分内容,这些内容在排序阶段中进行进一步的排序、筛选,最终形成用户看到的推荐列表[6]。
根据具体的应用场景,推荐系统又可以分为交互式推荐、序列推荐、会话推荐、兴趣点(Point of Interest,POI)推荐,可解释推荐等。交互式推荐根据用户的交互,实时改变推荐的内容,如Spotify(一款音乐软件)通过用户是否喜欢该歌曲实时调整推荐内容。序列推荐关注于用户的交互顺序,通过用户历史的有序操作序列,推荐给用户内容。会话推荐与序列推荐类似,只不过会话推荐只关注用户在很短一段时间的实时交互,如点击,喜欢,甚至是与人机对话系统的多轮对话,来分析用户的短期兴趣。兴趣点推荐特指为用户推荐可能感兴趣的地理位置,为人们的未来出行提供建议的推荐。以上各类场景,已经深入了我们生活的方方面面。可以说,推荐系统已经成为了互联网生态中不可或缺的一部分[7]。
..............................
第二章相关理论与技术
2.1传统推荐算法概述
互联网的发展深刻的改变了人们的生活方式,如今人们生活中处处充满了互联网应用的身影。作为其中最为悠久的应用形式之一——推荐系统在过去的二十年间也经历了翻天覆地的变化。几十年来,推荐算法也不断演进,从最早的协同过滤算法、矩阵分解,到后来的基于神经网络的算法,推荐算法对用户与物品间的信息捕捉能力越来越强。
协同过滤(Collaborative Filtering)技术是最早使用的推荐算法之一,并且这种算法至今仍然是推荐系统的研究热点方向之一。协同过滤技术的核心思想是,在过去有相同兴趣的用户,在未来也拥有相同的兴趣。基础的协同过滤模型可以被定义为:给定一个用户-物品矩阵????,表示已知的????个用户和????个物品,其中????????,????表示用户????对物品????的兴趣,要求推荐给用户一个列表,这个列表基于用户的兴趣降序排列。
过滤两大类,其中基于内存的协同过滤又可以进一步分为基于用户和基于物品两类[16]方法。基于用户的协同过滤方法通过汇总与用户????相似的户对项目的评分,来预测用户????对物品的评分,相似用户一般使用皮尔逊相似度或者余弦相似度方法,通过????临近等算法得到与用户????最相近的????个用户来预测评分。基于物品的方法则使用用户曾经评价过的其他项目来推荐项目,对于用户????,使用候选集中的所有项目,与该用户历史评价过的项目的相似度作为推荐的依据。基于内存的协同过滤的缺陷在于,计算用户或项目之间的相似度非常耗时,它的时间复杂度为????(????2)。
...........................
2.2强化学习算法概述
计算机论文怎么写
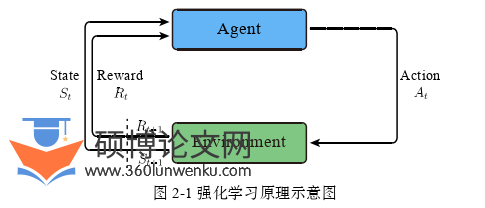
强化学习主要研究如何从环境中极大化奖励的问题。其中,算法部分称为智能体,如图2-1所示,智能体获取环境状态????????,经过算法计算输出一个动作????????,环境接受到动作????????后,会给智能体一个反馈????????,并产生下一个状态????????+1,继续输入到智能体中,如此往复循环,这就是最基本的强化学习模型。
强化学习通过探索来获取对环境的理解,然后利用学到的知识来获取更大的奖励。强化学习与监督学习最大的不同在于,强化学习中没有一个确定的标签,对于一个样本,我们不知道它是否“正确”,智能体得到的反馈只有环境给出的奖励,而这个奖励很有可能是延迟的,即智能体做出这一步动作后,可能不能获得即使的奖励,而在之后的好几部后才获得延迟奖励。此外,强化学习中程序获得的“样本”都是通过与环境交互得来的,而非数据集,这样导致获得的数据相互关联程度大,而不是数据集中那样服从相互独立同分布。
............................
第三章好奇心驱动的强化学习推荐算法研究....................21
3.1引言...................................21
3.2模型设计...........................22
第四章强化学习推荐算法中的状态表示研究............................48
4.1引言...........................48
4.2模型设计............................48
第五章基于强化学习的个性化推荐系统实现...........................61
5.1需求分析..............................61
5.2总体设计..........................63
第五章基于强化学习的个性化推荐系统实现
5.1需求分析
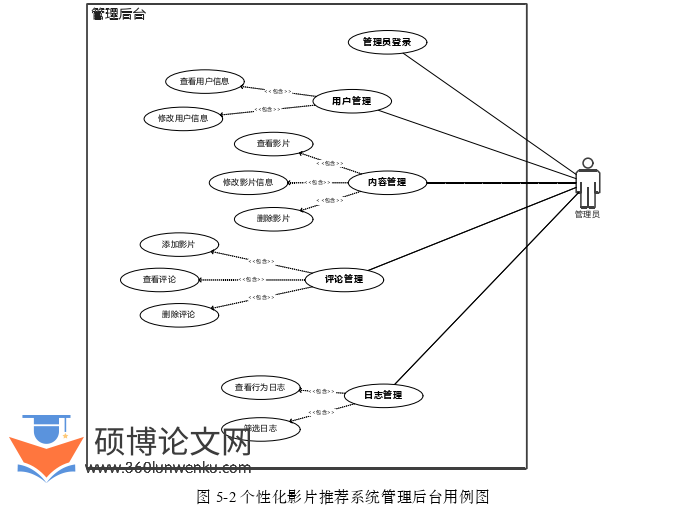
本系统是一个基于强化学习的影视推荐系统。该系统的主要功能是让用户在线浏览最新的影视信息,根据用户的兴趣推荐影片。依据以上目的,本文的系统分为两个子系统,一是面向普通用户的系统,称之为主端,二是面向管理员用户的系统,称之为管理后台,或管理端。主端面向用户提供登录、个人主页,选影片,搜索,推荐等功能。管理端提供用户管理,内容管理,日志管理等管理功能。
主端的用例图如图5-1所示,主端用户的用例主要有以下几个部分组成:
•登录/注册。登录注册负责用户的账号注册,登录功能,本系统提供邮箱注册功能,注册后系统中保存用户的邮箱,用户名等信息。
•个人信息管理。提供用户修改个人信息的功能,用户通过个人主页可以修改自己的用户名、头像、个性签名。
•影片Feed流。根据强化学习推荐算法,提供给用户个性化的推荐内容。在页面中以Feed流的形式展现给用户,用户可以不断的刷新想看的内容。
•影片检索。提供给用户影片搜索的功能,用户可以根据不同维度的分类,包括年份、类型、标签等来筛选影片。
•影片详情。提供用户查看影片具体信息的功能,用户可以在影片的详情页浏览影片的名称、年份、标题、类型、简介、海报、语言、时长、演职人员等内容。
•影片评论。影片的评论系统,提供给用户评论影片和查看其他人的评论的功能,用户通过影片详情页能够查看评论,或给影片打分和评论。评论可以仅查看本人评论,也可以根据热度或时间筛选。
计算机论文参考
.............................
第六章全文总结与展望
6.1全文总结
本文主要研究强化学习算法在推荐领域的应用,通过将推荐场景建模为强化学习中智能体与环境的交互过程,从而达到推荐的长期效果最大化。
本文首先介绍了推荐系统的发展历程和应用场景,说明了推荐系统及其算法在如今互联网中的重要研究价值。然后,本文简要介绍了推荐算法的演进,阐述了强化学习算法在推荐系统中的研究意义。强化学习通过智能体和环境的交互得到的反馈来使得长期的奖励最大化,这种方式非常适合在推荐算法中使用。这种形式可以让推荐算法具备更高的灵活性,能够更好的适应用户多变的兴趣,从而提供更加准确和多样的推荐。
本文概述了与强化学习和推荐系统相关的技术。首先本文介绍了传统的推荐算法,包括协同过滤算法、矩阵分解、深度学习等技术,这些方法至今仍有大量研究。然后,本文继续介绍了强化学习的基本原理,简要归纳了强化学习的基本方法和定理公式。然后,本文阐述了强化学习应用到推荐场景的实践挑战,包括状态表示问题、奖励函数设计问题以及探索与利用困境。最后,本文总结了强化学习在推荐领域的具体应用,包括基于价值的推荐算法:主要是DQN及其改进算法的应用;基于策略的算法:以PG算法为基础提出的PPO,DPG等算法;基于Actor-Critic模型的算法:基于价值和基于策略的算法的结合,Actor作为策略网路,Critic作为价值网络,二者结合以充分利用两种算法的优点。最后,本文还介绍了一些新兴的强化学习算法以及其在推荐领域的应用。
参考文献(略)