本文是一篇计算机论文,本文从相关的无监督模型和监督模型的理论发展,以及利用标签信息来增强模型鉴别性的理论研究进行了介绍。针对如何利用特征编码和标签矩阵的天然属性得到更具鉴别性的数据表示,在已有理论的基础上,提出了三种鉴别性稀疏低秩理论为基础的图像分类方法。
第一章 绪论
1.1 研究背景及意义
随着信息技术的不断进步和发展,图像采集设备、网络传输设备和大规模存储设备等硬件设备性能持续提升,以及移动端智能设备的普及,多媒体数据的大量产生也大大促进了计算机视觉与模式识别技术的发展。在模式识别领域,如何从繁多且冗余的图像数据中高效地获取简洁判别的有效信息成为研究的关键。其中,图像分类一直是计算机视觉领域中一个基本任务,是许多高层视觉任务的基础,实际应用非常广泛。图像分类的主要任务是为给定的输入图像,为其分配已知的多个类别中的某一个标签。当前日益增长的信息数据规模,以及各领域对图像分类技术的实际应用(例如安防领域的人脸[1]和指纹识别、交通领域的交通场景识别[2]和车辆识别[3]以及多目标识别[4]等等)需求,都对图像分类技术的进一步研究发展提出了要求。图像分类领域的发展包含诸多分支技术,不论是各个分支自身还是不同分支之间思想的相互借鉴,都有研究者们在进行持续地探索[5]。在这样的研究背景下,本文的研究工作基于鉴别性稀疏低秩的图像分类方法进行展开。
1.1.1 研究面临的挑战
图像分类是计算机视觉领域中的一个基础任务,关于图像分类的研究已经持续了相当长的时间,但其实际应用中仍然面临诸多挑战,需要更多研究和经验的积累。如图 1-1 所示,图像分类问题面临的主要挑战包含如下几点:
视角变化:视角变化通常是由于图像采集过程中摄影机相对于同一目标的拍摄角度变化而造成的,例如记录了同一目标正面侧面仰角俯角等不同视角的多张图像。
形变:由于目标可能是非刚体,目标可能由于自身的不同类型和动作产生不同的变化,例如人类脸部的表情变化会造成局部的非刚性变化。 遮挡:在采集目标图像时,目标可能处于被其他物体遮挡的情况,只有一部分是可见的,例如人脸图像采集时很容易遇到被眼镜围巾遮挡的情况。
光照变化:在实际情景中,光线不是恒定不变而是时刻变化的,不管是由于室内室外还是由于自然阳光由于太阳东升西落造成的明暗变化,都会对分类任务造成影响。
类内差异:哪怕是同属于一个类别的不同个体,也会存在个体差异,这可能包括细节纹路图案的变化,也可能包含具体的结构上的差异,例如具体到每一个椅子,都有着不同的颜色结构上的变化。
.....................
1.2 发展及研究现状
图像分类问题一直是计算机视觉和模式识别领域一个非常活跃的课题。自稀疏表示被应用到分类问题中后,吸引了越来越多研究者的关注,在这个领域中如何获得判别的数据表示成为研究者始终关注的重点。从是否利用标签信息这一角度,鉴别性稀疏低秩相关的研究可以被分为无监督方法和监督方法两类。
稀疏表示最早被应用在信号分析领域,用于对信号进行稀疏分解,以获得信号更简洁表示形式。Wright 等人[9]在 2009 年提出基于稀疏表示(Sparse Representation-based Classification,SRC)的人脸识别算法,开创了稀疏表示在图像识别领域应用的先河。其关键点是假设样本可以被同一类别的少量其他样本线性表示。在其工作的基础上,许多学者对 SRC 的理论进行了研究并提出了改进版本[11]。在对 SRC 的机制进行了探讨后,Zhang 等人[13]的工作指出了 SRC 模型中协同表示的作用。他们提出的协同表示(Collaborative Representation based Classification, CRC)算法的分类精度与 SRC 相当,但非常有效地提升了运算效率。Cai 等人[14]从概率的角度解释了 CRC 的机制,并以此为基础提出概率协同表示方法(Probabilistic Collaborative Representation Based Classifier,ProCRC),在保证了运算效率的同时也有效地提升了识别率。Jiang 和 Lai 等人[15]提出了一种稀疏和稠密的混合表示方法(Sparse- and Dense-hybrid Representation,SDR),它是通过类特定字典的稀疏表示和非类特定字典的稠密表示来实现的,它将图像分解为三个组成部分:类特定信息,非类特定变化和稀疏噪声。
稀疏表示对于图像中的随机噪声具有一定的鲁棒性,但是当存在连续的图像损坏和噪声时,基于 SRC 的模型性能将会下降。针对图像中的噪声损坏问题,Liu 等人[16]提出的低秩表示(Low-Rank Representation,LRR)模型可以很好地分离图像中的噪声以恢复干净图像,并且得到样本的准确子空间分割。潜在低秩表示(Latent Low Rank Representation,LatLRR)[17]是低秩表示的增强版本,针对无噪声样本不充足问题额外考虑了未观察到的隐藏数据。同时 LatLRR 可用于特征提取,从原始数据中得到显著特征以用于分类问题。Fang 等人[18]指出 LatLRR 学习的特征维数与原始数据相同,并提出了一种近似低秩投影学习(Approximate Low-Rank Projection Learning,ALPL)用于特征提取,引入两个矩阵来代替 LatLRR 中的单个低秩投影矩阵。为了使提取的特征更具鉴别性,通过采用回归模型,将 ALPL 扩展为监督版本(Supervised Approximate Low-Rank Projection Learning,SALPL)。
.........................
第二章 基于稀疏与低秩的相关算法理论
2.1 实验数据集介绍
本小节将简单介绍本文所涉及的图像数据库,包括人脸数据库 AR[41]、CMU PIE[42]和 LFW[43],物体数据库 COIL20[44],场景数据库 Scene15[45]和图片分类数据库 Tiny ImageNet[46]。本小节将对本文涉及的数据集以及相应的实验设置进行简短介绍。本文实验均在 CPU 为 Intel core i5-4460 @3.20 GHz,内存为 12.0GB,操作系统为 Windows7 64 bit,Matlab 版本为 Matlab R2015a 环境下进行。
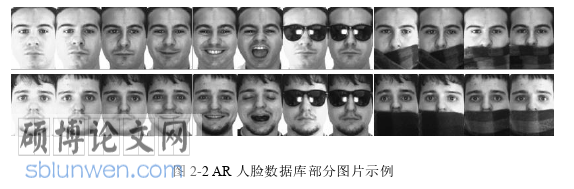
AR 数据库:AR 数据库是由 Aleix Martinez 和 Robert Benavente 在.A.B 的计算机视觉中心创建的[41]。数据库包含 4000 多张彩色图像,分别对应 126 个人的面部(70 位男性和 56 位女性),并且包含不同的表情,光照条件和遮挡物(墨镜和围巾)。AR 数据库部分示例图像如图 2-2 所示。在我们的实验中,选取了其中的一个子集,包含 50 位女性和 50 位男性受试者的 2,600 张图像。在此子集中,每个人都有对应的 26 张图像并且可以将其分为相同数量的两个部分。对于每个图像,使用随机投影方法进行降维,最后得到的特征维数为 540 维。
计算机论文参考
..........................
2.2双转换矩阵学习(DTML)
如前所述,在分类问题中,样本数据包含各种信息,例如类特定信息、样本之间的关联信息、类内变异和类间差异信息等等。在这种情况下,单个转换矩阵无法提供灵活的投影来消除复杂信息带来的负面影响。同时,从原始数据中提取信息的最直接方法是使用特征提取方法对原始数据进行预处理。受这些启发,为了处理原始数据????中的复杂信息,我们使用 LatLRR 对原始数据进行预处理。如第 2 章所述,LatlRR 从原始数据????的两个方向(列和行)提取两个对应的主要特征和显著特征。在这两个方向上提取的特征包含样本之间的关联以及样本本身的关键信息。
尽管删除了稀疏噪声项,但是在实际问题中同类的“干净”特征间仍然存在差异。而且,如 DRR 中所述,对于复杂的分类任务而言,单个转换矩阵可能过于严格以至于无法获得更灵活的投影。而且,单个变换矩阵不能充分利用所提取特征中包含的信息。换句话说,在这样的任务中,对于单个投影矩阵而言,同时处理从两个不同角度提取的特征的问题并不合适。 为了充分利用这两个特征中包含的信息来进行分类任务,我们引入了两个分类器????1和????2分别处理这两个特征并将相应的特征信息投影到标签空间中。因此,我们使用两个变换矩阵将这两个特征共同投影到唯一的分类标签空间中,以获得最终的分类结果输出。
求解 DTML 目标函数的详细流程如下。

计算机论文怎么写
.............................
第三章 基于低秩特征的双转换矩阵学习算法 ................................. 15
3.1 引言 .................................. 15
3.2 双转换矩阵学习(DTML) ........................ 16
第四章 基于类内低秩约束的子空间学习算法 ................ 26
4.1 引言 ............................ 26
4.2 类内低秩子空间学习算法(ICLRSL) ....................... 27
第五章 基于结构化分类器的字典对学习算法 .......................... 38
5.1 引言 ...................................... 38
5.2 基于结构化分类器的字典对学习算法(SCDPL) .................. 39
第五章 基于结构化分类器的字典对学习算法
5.1 引言
表示学习已经在模式识别的众多领域都取得了成功,其关键思想是认为每一个样本都可以被表示为样本的线性组合,从而得到其对应的表示系数[66]。 为了将表示系数应用到分类问题当中,Wright 等人利用????1范数作为系数约束来得到稀疏的表示[10]。稀疏表示学习中,样本的表示更倾向于选择同类样本,即最大的表示系数应该来自于同类的表示系数。但是 Zhang 等人[13]提出在表示学习当中其他类别的样本对于样本的表出也做出了贡献,并且其关于协同表示的工作与 SRC 相比速度大大提升精确率却相差无几。在最近的工作当中,非负表示(Nonnegative Representation,NR)[67]也被提出,指出非负约束能自然导致稀疏并且更符合直观。
上述的表示学习方法使用全体的训练样本来进行组合,但是原始数据往往包含众多冗余信息,因此字典学习的方法被提出来得到紧凑的字典原子。根据标签信息是否指导模型的学习,字典学习方法可以被分为两类,无监督和监督。在无监督字典学习中,KSVD[25]是相当典型的算法,其概括了????均值聚类并且从训练样本中学习一个过完备字典。但是 KSVD 旨在对图像进行重构,并将以最小化重构误差为标准学习字典并且可以应用到分类任务当中。但是实际能得到最好的重构效果并不等同于能够得到最好的分类效果。并且已经有很多工作表明,有标签信息参与的情况下,能获得更好的分类效果。在 KSVD 的基础上,判别 KSVD(Discriminative KSVD,D-KSVD)[68]和 LCKSVD[26]学习了一个分类器来构建从系数到标签信息的映射,在重构图像和分类之间找到平衡,来得到能兼顾重构与判别性的字典。与此同时,为了让字典学习到的同类系数具备相似性,LCKSVD 加入了判别稀疏系数误差项,建立系数和给定的判别系数之间的关系。从KSVD 到 LCSKVD,也验证了标签信息的引入即监督版本下拥有更好的分类效果。除了应用分类器建立映射关系之外,FDDL[27]基于标签信息构造类内和类间散度矩阵,并希望获得的表示系数拥有较小的类内散度和较大的类间散度。通过基于散度矩阵的费舍尔判别项,FDDL 来得到一个结构化的字典。但是 FDDL 需要逐类优化子字典和系数,带来了巨大的计算开销。针对这一点,LRSDL[28]的工作中提出了 FDDL 的快速算法,并且针对训练样本中的共有信息学习了低秩 共享字典。同时,为了学习结构化的字典及表示,分块对角结构[69]也被应用到模型当中来增强同类样本系数的相似性和异类的差异。并且,松弛块对角字典学习(Slack Block-Diagonal Dictionary Learning,SBD2L)[33]指出严格的 0-1 块对角结构约束同类系数完全相同会限制模型的灵活性并提出了松弛的块对角结构,可以动态地更新目标结构矩阵。
..............................
总结与展望
论文工作小结
图像分类问题一直以来都是模式识别一个很有实际应用价值但又存在众多挑战的研究课题。自稀疏低秩在分类问题中的作用得到广泛关注后, 已经取得了诸多成就。本文从相关的无监督模型和监督模型的理论发展,以及利用标签信息来增强模型鉴别性的理论研究进行了介绍。针对如何利用特征编码和标签矩阵的天然属性得到更具鉴别性的数据表示,在已有理论的基础上,提出了三种鉴别性稀疏低秩理论为基础的图像分类方法。具体工作如下:
(1)提出一种基于双转换矩阵的图像分类方法。针对线性回归模型中单个转换矩阵因复杂数据信息而面临的投影压力,提出使用特征分解技术和转换矩阵松弛来缓解压力并获取更为灵活的投影。对转换矩阵的松弛一个自然的做法即是使用多个转换矩阵,出于这一目的和特征分解的要求,在特征分解阶段选用 LatLRR 将数据分解为三个部分。LatLRR 主要特征中包含对某类数据信息的整体描述和类别间的关系信息,显著特征则包含某图像中最关键的特征信息,而噪声部分则往往因为影响分类效果不参与后续工作。在线性回归阶段,引入两个转换矩阵分别处理两个特征,并且共同完成到标签空间的投影任务。在数个数据集,尤其是较为复杂的 LFW 数据库上验证了,所提出的方法能够获得与基于标签松弛技术的方法相当甚至更好的结果。
(2)提出一种基于类内低秩子空间学习的分类算法。第三章中特征提取与回归任务之间是相互独立的,特征提取过程并未受到标签信息的监督。为了将特征提取和回归任务相结合,一方面在回归任务前获取中间特征以优化后续回归任务并且减轻转换矩阵压力,另一方面也使特征提取过程受到标签信息的影响而得到更具鉴别性的信息。基于这一目的,在线性回归的基础上引入子空间学习,利用子空间投影和标签空间投影分别完成中间特征和回归向量的学习。同时鉴于最终回归目标即标签矩阵所包含的类内一致性,为了使从原始数据到中间特征再到回归向量逐渐向标签矩阵逼近,为子空间学习引入类内低秩约束。在 AR、COIL20、CMU PIE 和 Scene15 图像数据库上的大量实验结果验证了,引入子空间学习的效果和所提出的方法的有效性。
参考文献(略)