本文是一篇计算机科学与技术论文,本文使用神经网络提取人物的高层语义特征,如人脸、人头和身体姿态特征信息,使用人物多种不同的特征完整描述目标人物,然后计算人物特征距离并加权融合,从而达到搜索同一人物的所有视频片段的目的。
第一章 绪论
1.1 研究背景与意义
近年来,随着技术的迅速发展,多媒体逐渐成为人们获取信息的重要方式之一,同时视频数据也日益丰富。在腾讯视频、爱奇艺、优酷等视频软件的发展下,衍生出一种只播放短视频的媒体软件(或插件),如抖音、快手、哔哩哔哩等,囊括了各种类型的视频。这些软件的崛起表明自媒体网络视频已经大众化,且与人们的生活息息相关,给大家带来了很多乐趣。其中,视频中含有的信息能够直观地表示出来,成为人们获取信息的常用手段之一,视频所产生的流量数据在互联网流量数据中也占据了举足轻重的地位,且大量的高质量视频信息具有非结构化特征。面对飞速增长的视频数据,如何快捷地获取自己感兴趣的视频片段,逐渐受到国内外研究人员的重视。
通过视频表示的信息具有多元化的特征,用户可以根据视频中的多元化特征进行视频搜索,一种是通过提交短视频的方式来搜索视频库中相似或者相同的视频片段,另一种是通过输入关键词的方式对视频标签进行搜索。传统的视频搜索方式主要是人工根据视频内容标注的关键词进行搜索。首先对视频内容所表示的主要含义进行人工文本标注,然后形成对视频内容描述的关键词,最后根据关键词对视频进行检索。这种使用人工标注的方法容易实现,且在一些情况下的查询效果较好,但缺点也比较明显:
(1)标注的视频关键词缺乏客观性,不同标注者对同一视频会有不同的见解,所以会带有标注人员的主观思想,导致对视频标注的关键词存在一定的偏差。
(2)标注的视频关键词不全面。当用户想获取某个人的视频资源时,由于人工标注无法保证是否对视频中的所有人员信息进行了标注,因此用户根据人工标注的关键词从视频数据库中检索时,无法搜索到相应的视频资源。
(3)当前视频数据激增,而人工无法长期持续进行标注,并且易疲劳,因此人工标注的速度较慢。
....................
1.2 国内外研究现状
在最近的几十年中,视频检索从基于文本标签的检索方法到基于内容的检索方法有着质的跨越。随着现代科技的发展和研究人员深入的研究,已经不满足于基于颜色、形状、直方图等低层特征的处理,进军于视频中目标特征的提取和识别。
1.2.1 视频关键帧提取技术现状
随着网络和自媒体的发展,视频文件呈现指数级别增加,面对大量的视频数据,如何快速有效地从这些视频库中检索出人们感兴趣的视频,已经成为当今信息化时代的一个难题[1]。视频数据有着数据量大、维度高等特征,在检索过程中需要消耗大量的内存和搜索时间[2]。在基于多特征融合的视频处理过程中,关键帧提取是关键的步骤之一。由于视频数据量巨大且繁杂,且耗费大量时间,导致视频的检索效率无法达到用户的检索需求。因此,为了压缩数据量,减少匹配特征的计算量,在镜头中需要丢弃冗余帧,最终选取出能够表达视频中主要内容的一帧或者多帧作为关键帧,以此来提升视频检索的效率。
近年来已经出现了许多关键帧提取的算法,但它们的侧重点各有不同。Nagasaka 等[3]人提出基于镜头边界来提取关键帧,能够直接提取视频帧作为关键帧,无需计算,方便快捷,该方法主要是提取视频镜头的首帧、尾帧作为关键帧,或者根据一定的时间间隔对视频帧进行采样作为关键帧,但提取的视频帧随机性较大,无法正确且完整地表达镜头中的信息;WOLF W[4]提出基于运动分析的方法来提取关键帧,通过计算光流并分析镜头内部的物体运动,并将运动最小值的帧作为关键帧。虽然该方法对物体运动有一定的敏感性,但是对于视频帧内部运动的物体无法判断其主次,且对于视频内部目标的特征不敏感,难以对视频帧内部主要目标特征进行提取并识别。李秋玲等[5]提出一种基于背景建模算法的前景运动目标特征提取的关键帧提取算法,使用 SIFT 算法对比相邻帧之间的相似度和片段相似度的均值确定关键帧。但该方法计算量过大,当数据量巨大且视频清晰度较高时,视频检索效率会受到机器运行速度的限制。
............................
第二章 视频检索相关技术
2.1 视频数据
2.1.1 视频数据特点
图像是人的眼睛对事物的成像,随着技术发展,人们眼睛对事物的感知可以由光学设备获取并保存下来,因此将人眼成像的数据进行数字化。由于图像信息数字化后是二维的,设该二维图像是一个矩阵 f(x,y),其中 x,y 是二维图像任意一个像素点的位置,其对应的是该像素点的灰度值。而视频便是由一系列连续的图像组成,视频的基础单位是帧,即一幅图像。视频信息相当于由图像 f(x,y)变成 f(x,y,t),其中 x,y 的意义不变,t 代表一帧图像出现的时间点。由于视频是集图像、文本、音频为一体的多媒体数据,包含的信息量较大,无法结构化存储、索引和存储。视频数据作为人们获取信息的一种媒介,主要有以下三个特点:
(1)视频所含数据量巨大。视频是由一系列连续的图像组成,物体在快速移动时,映射到人眼的影像消失后,人眼仍然会持续保留其影像 1/24 秒左右的图像,是人眼的一种特性。当人看视频时每秒最少要播放 24 帧连续的视频,人眼才会感觉到流畅。因此,视频每秒至少含有 24 帧,若一帧图像的大小按照 1MB计算,1 秒将会含有 24MB 的数据信息,则一个小时至少将会有 86400MB 的视频数据。如此大的视频会导致服务器空间不足以承载这么大的文件,而且随着分辨率和码率的增加,视频质量有了质的飞跃,数据量也会急剧增加。因此,为了减少视频文件的占用空间,研究人员研究出很多视频压缩技术,例如 H.261、H.263、H.264、H.265 等编码技术,这些编码技术能够很好地压缩视频,但视频文件依旧较大。
(2)视频数据内容丰富。视频中不仅仅包含文字、声音、图像信息,而且引入了时间维度,能够生动形象地表达一个事件的前因后果,描述出用户想要表达的信息。
(3)视频数据的结构复杂。对于文本和图像而言,均为个体,单独表示信息,均与时间无关。而视频需要根据图像的时间线获取信息,单独的某一帧很难表示一段视频的全貌。因此,对于视频进行结构化存储较为困难。
......................
2.2 视频检索的结构框架和关键技术
2.2.1 视频检索的结构框架
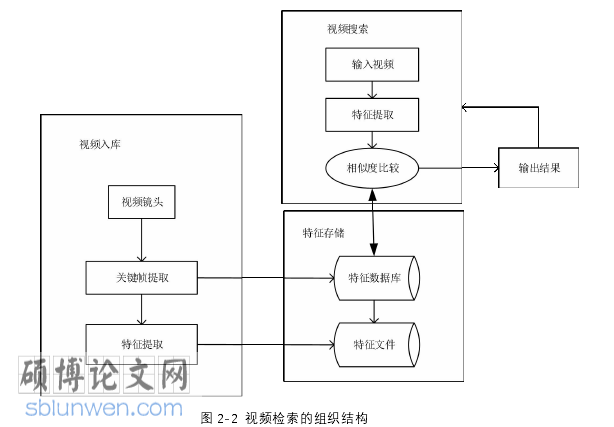
视频检索的组织结构主要分为三大部分如图 2-2 所示,第一部分是视频入库,这一部分是视频检索系统中最重要的一部分。在视频检索过程中,首先要将视频镜头录入到视频库中,然后提取视频中的关键帧,最后根据视频关键帧提取出视频的特征。在视频检索系统中,关键帧提取有着承上启下的作用,要尽可能携带大量视频内容信息,因此关键帧提取的质量和数量直接决定着视频数据占据存储空间的大小,另外,在特征提取时,也会受到关键帧的影响,当提取的关键帧不能够最大程度代表视频内容信息时,会直接影响搜索出的结果。第二部分是特征存储,在特征存储这一个部分,将特征数据库和相应的特征文件结合起来,其中特征数据库存储视频的关键帧,特征文件则存储提取的视频特征。第三部分是视频搜索,这部分主要是利用相似度计算的方式进行匹配,在这部分提供人机交互的界面可供用户直观地获取到搜索视频的结果,在这部分,用户直接输入待检索的视频文件,提取出视频文件的特征,然后将视频特征与特征数据库的特征进行匹配,比较相似度,获取相似度较高的视频数据文件,最后输出结果返回给用户。
计算机科学与技术论文怎么写
................................
第三章 基于人脸识别和 K-MEANS 的视频检索.................................. 16
3.1 关键帧提取常用方法...................................................16
3.1.1 基于镜头边界的方法..............................................16
3.1.2 基于内容分析的方法.................................17
第四章 基于多特征融合的视频检索..............................25
4.1 目标检测和特征提取...................................................25
4.1.1 人脸检测和特征提取..............................................25
4.1.2 人头检测和特征提取........................................31
第五章 视频检索系统.........................40
5.1 系统设计.....................................................40
5.2 系统实现展示................................................41
第五章 视频检索系统
5.1 系统设计
本文设计的视频检索系统,属于在本地视频库中进行检索,系统中主要含有基于 K-means 聚类的关键帧提取技术和基于多特征融合的视频检索技术,多特征融合是在提取关键帧的基础上进行处理。本文设计的视频检索系统的系统功能模块如图 5-1 所示。

计算机科学与技术论文参考
本文设计的视频检索系统主要分为两个模块,第一个模块是将视频入库,建立视频特征数据库,第二个模块是进行视频搜索。视频入库模块中含有三个功能,分别是关键帧提取、特征提取和特征数据库。视频搜索模块中含有关键帧提取、特征提取和相似度计算的功能。
.........................
第六章 总结与展望
6.1 论文总结
随着多媒体的发展和自媒体的普及,视频内容越来越丰富多彩,但是也变得越来越复杂,对于检索感兴趣的人物也有一定的挑战。传统方法提取颜色直方图或者纹理等特征信息已经无法完成人物的识别,为了解决这个问题,许多研究人员引入了神经网络,提取感兴趣区域的特征并训练模型,从而更加方便地提取感兴趣区域的高层语义特征。
然而,由于视频非结构化的特点,对于人物视频的检索存在一定的问题:
(1)在检索目标人物的所有视频片段时,使用传统的方法提取关键帧,仅是根据视频内容的全局特征进行处理,而并非考虑到视频中的人物。因此,使用传统提取特征的方法和 K-means 聚类无法提取以目标人物为主的关键帧,故难以搜索到用户感兴趣目标人物的所有视频片段。
(2)使用传统的底层特征提取方法提取人物的特征,识别人物效果不佳,并且人物具有不同的特征,例如人脸、人头和身体姿态等特征,使用其中一种特征在人物识别过程中有一定的效果。但是在整个人物识别中,一种特征只能表示人物的一部分,因此受到一定的限制。
针对以上问题,本文研究分为以下部分:
(1)使用 K-Means 聚类时,结合人脸识别的方法,提取视频中人脸的特征信息,为了保证特征信息的可靠,本文增加了置信度加权,提取模糊的人脸图片特征后使用置信度对特征加权,以增加人脸特征的可靠性。对于视频中人脸个数不确定,无法设定 K 值,本文使用人脸相似度边界,作为距离半径,迭代分为多个簇,从而提取出关键帧,以达到检索目标人物所有视频片段的目的。
(2)使用多特征融合检索目标人物的视频片段。对于低层语义特征难以识别人脸,本文使用神经网络提取人物的高层语义特征,如人脸、人头和身体姿态特征信息,使用人物多种不同的特征完整描述目标人物,然后计算人物特征距离并加权融合,从而达到搜索同一人物的所有视频片段的目的。
参考文献(略)