
第一章 绪论
1.1 研究背景及意义
阅读理解是指基于一篇或几篇给定文档自动回答一系列相关的问题。其研究可以推动自然语言理解技术的进步,促进机器实现语言智能。
早在 20 世纪 70 年代人们就意识到机器阅读理解的重要性并开始进行研究,但由于当时数据的缺乏和技术的落后,导致机器阅读理解的研究停滞不前,直到 90 年代才开始复兴。1999 年 Hirschman[1]指出阅读理解在语言理解、信息检索等领域的重要性,并且针对 3-6 年级的小学生阅读材料提出了一个自动阅读系统,使机器阅读理解有了初步的发展。近几年,阅读理解受到了学术界和企业界的广泛关注,如微软、Facebook、Google DeepMind、百度、哈工大讯飞联合实验室、Stanford University 等顶级 IT 公司与大学分别展开相关研究,并创建公布了各自的阅读理解数据集,极大提升了机器阅读理解的研究水平。这些数据集中问题的获取方式主要有以下两种:
(1)问题由人工设计。2013 年,微软采用众包方式,通过人工撰写问题,建立了 MCTest 阅读理解数据集,共有 660 个虚构故事,要求机器从 4 个候选答案中选择正确的答案[2]。2016 年,斯坦福大学建立了 SQuAD 数据集[3],阅读材料来自英文维基百科,问题和答案由人工标注,目前该数据集共有 536 篇文章、107785 个问答对,答案为原文中的片段,受到很多研究者的关注,谷歌提出的 BERT 模型在该数据集上已超越人类表现 2-5%[4]。2018 年斯坦福又提出 SQuAD2.0 数据[5],在原来数据的基础上增加了不可回答的问题,增大了数据的难度。2017 年科大讯飞发布了中文阅读理解数据集,语料来自内部收集的 20000 篇儿童读物,包括填空题和问答题,展开了第一个汉语阅读理解评测。
(2)问题源于真实生活。2016 年微软发布了英文 MS MARCO 数据集,由 10 万个问答组成,其问题来自必应搜索引擎和微软小娜人工智能助手的真实查询[6];2018年百度发布了中文 DuReader 数据集,包含 30 万个问题,其问题和阅读材料均来源于百度搜索和百度知道,是目前最大的中文阅读理解数据集[7]。这些数据集是符合现实生活的语料。
.........................
1.2 国内外研究现状
1.2.1 阅读理解研究现状
近几年一些公司和评测组织纷纷推出各自的阅读理解数据集,根据这些数据集,可以将阅读理解问题可分为 cloze 问题、选择题和问答题。针对 cloze 问题的数据集有 CNN/Daily Mail[8]、汉语 PeopleDaily/CFT[9]等数据集;选择题类型的数据集有MCTest[2]、CLEF 高考评测[10,11]等数据集;而问答题相关数据集有 SQuAD[3]、MSMARCO[6]、汉语 DuReader[7]和 CMRC2018 评测①数据集,根据这些数据集中问题答案的长短,还可将问答题分为 Yes/No 问题、简单事实类(实体类、短语类)问题和描述类问题。目前的研究主要针对 cloze 问题和简单事实类问题进行,而且已提出了众多有效模型,但是对描述类问题的研究较少。
随着数据规模的增大,阅读理解方法从早期基于规则的方法逐渐转向基于传统机器学习和基于深度学习的方法。
第三章 基于问题理解的解答策略..................................11(2)问题源于真实生活。2016 年微软发布了英文 MS MARCO 数据集,由 10 万个问答组成,其问题来自必应搜索引擎和微软小娜人工智能助手的真实查询[6];2018年百度发布了中文 DuReader 数据集,包含 30 万个问题,其问题和阅读材料均来源于百度搜索和百度知道,是目前最大的中文阅读理解数据集[7]。这些数据集是符合现实生活的语料。
.........................
1.2 国内外研究现状
1.2.1 阅读理解研究现状
近几年一些公司和评测组织纷纷推出各自的阅读理解数据集,根据这些数据集,可以将阅读理解问题可分为 cloze 问题、选择题和问答题。针对 cloze 问题的数据集有 CNN/Daily Mail[8]、汉语 PeopleDaily/CFT[9]等数据集;选择题类型的数据集有MCTest[2]、CLEF 高考评测[10,11]等数据集;而问答题相关数据集有 SQuAD[3]、MSMARCO[6]、汉语 DuReader[7]和 CMRC2018 评测①数据集,根据这些数据集中问题答案的长短,还可将问答题分为 Yes/No 问题、简单事实类(实体类、短语类)问题和描述类问题。目前的研究主要针对 cloze 问题和简单事实类问题进行,而且已提出了众多有效模型,但是对描述类问题的研究较少。
随着数据规模的增大,阅读理解方法从早期基于规则的方法逐渐转向基于传统机器学习和基于深度学习的方法。
(1)基于规则的方法。即基于手工建立启发式规则来捕捉问题与原文之间的关联。如:Hirschman 等人对句子和问题进行句法或语义分析通过计算其匹配度或相关度,将排名前 N 的句子作为答案[1]。Riloff 等人针对问题的不同类型,手工构建不同的打分规则寻找得分高的句子作为答案候选句,然后对候选句中的人名、地名、月份和时间进行识别来确定答案[12]。
(2)基于传统机器学习的方法。如:Richardson 等人基于滑动窗口的方法解决选择类问题,将问题与选项拼接,得到一个假设句,在一定的窗口范围下,利用词袋模型计算假设句与原文的匹配程度来确定最终的答案[2]。Tan 等人[13]采用基于 LDA的句子主题分布方法,通过计算句子主题间的离散度判断问题与原文句子的相关性,选择排名前 N 的句子作为答案候选句。但此方法对单文档问答效果不是很明显,因为文档内的句子主题都是相关的,句间的主题分布区分度并不大。
.............................
第二章 描述类问题分析
2.1 问题定义
描述类问题通常具有高度概括性,对应的答案一般由多个句子组成。如表 2.1 所示的描述类问题,其中的“原理”是一个语义高度概括的词语,阅读材料来自搜索引擎返回的相关文档,答案由多个句子构成(在材料中用粗体字表示)。

.....................
(2)基于传统机器学习的方法。如:Richardson 等人基于滑动窗口的方法解决选择类问题,将问题与选项拼接,得到一个假设句,在一定的窗口范围下,利用词袋模型计算假设句与原文的匹配程度来确定最终的答案[2]。Tan 等人[13]采用基于 LDA的句子主题分布方法,通过计算句子主题间的离散度判断问题与原文句子的相关性,选择排名前 N 的句子作为答案候选句。但此方法对单文档问答效果不是很明显,因为文档内的句子主题都是相关的,句间的主题分布区分度并不大。
.............................
第二章 描述类问题分析
2.1 问题定义
描述类问题通常具有高度概括性,对应的答案一般由多个句子组成。如表 2.1 所示的描述类问题,其中的“原理”是一个语义高度概括的词语,阅读材料来自搜索引擎返回的相关文档,答案由多个句子构成(在材料中用粗体字表示)。
.....................
2.2 问题解答难点分析
通过分析大量样例,发现描述类问题解答难点具体体现在以下几个方面:
(1)问题涉及范围广。问题涉及教育、科技、体育、生活等领域,如此开放的问题对于训练鲁棒性强的阅读理解系统是极其困难的。
(2)问句简短抽象。问句表述与阅读材料叙述存在巨大的语义鸿沟,问句抽象而答案具体,如表 2.1 中的描述类问题“二维码的原理是什么?”中的“原理”是一个语义高度概括的词,而对应的答案片段是对二维码原理的具体描述。
(3)答案较长。答案一般由多个句子组成,不再限定于单个词或较短的短语。表 2.1 对应的答案由多句话组成,所以无法通过词形、词性或句法等信息与问题进行匹配。
(4)阅读材料含有噪音。若阅读材料来自搜索引擎返回的相关文档,则文档的结构可能杂乱无章,会有错误或干扰解题的信息存在。
(5)缺少科学合理的自动评价指标。常用的 Rouge 和 Bleu 指标仅能评价出两句话在词形方面的同现程度,对表述形式不同但语义相同的两句话无法给出合理的相关性评价。
从以上难点分析可看出,问题抽象和答案具体是描述类问题最突出的特点,所以问题和篇章的理解对解决该类问题尤为重要。
.....................
通过分析大量样例,发现描述类问题解答难点具体体现在以下几个方面:
(1)问题涉及范围广。问题涉及教育、科技、体育、生活等领域,如此开放的问题对于训练鲁棒性强的阅读理解系统是极其困难的。
(2)问句简短抽象。问句表述与阅读材料叙述存在巨大的语义鸿沟,问句抽象而答案具体,如表 2.1 中的描述类问题“二维码的原理是什么?”中的“原理”是一个语义高度概括的词,而对应的答案片段是对二维码原理的具体描述。
(3)答案较长。答案一般由多个句子组成,不再限定于单个词或较短的短语。表 2.1 对应的答案由多句话组成,所以无法通过词形、词性或句法等信息与问题进行匹配。
(4)阅读材料含有噪音。若阅读材料来自搜索引擎返回的相关文档,则文档的结构可能杂乱无章,会有错误或干扰解题的信息存在。
(5)缺少科学合理的自动评价指标。常用的 Rouge 和 Bleu 指标仅能评价出两句话在词形方面的同现程度,对表述形式不同但语义相同的两句话无法给出合理的相关性评价。
从以上难点分析可看出,问题抽象和答案具体是描述类问题最突出的特点,所以问题和篇章的理解对解决该类问题尤为重要。
.....................
3.1 问题类型识别.......................................11
3.2 问题主题和焦点识别..........................................12
3.3 融入问题理解的解答模型.................................13
第四章 基于篇章表示的解答策略........................................21
4.1 篇章的层级表示方式..............................21
4.1.1 基于 LSTM 句子编码的篇章表示............................... 21
4.1.2 基于 CNN 句子编码的篇章表示..........................23
第五章 基于篇章与问题理解的解答策略..........................................29
5.1 基于问题理解与篇章表示的解答模型...................................29
5.2 实验............................29
第五章 基于篇章与问题理解的解答策略
5.1 基于问题理解与篇章表示的解答模型
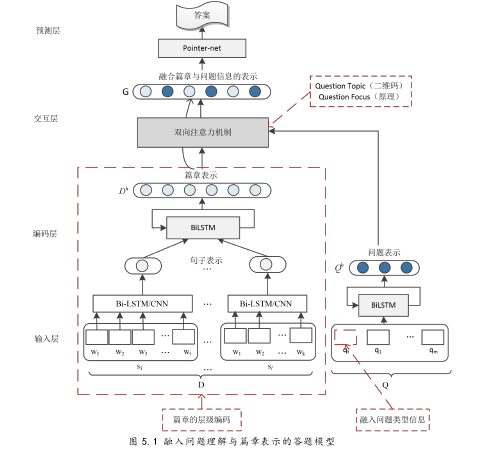
如图 5.1,我们在输入层融入问题类型信息,在编码层对篇章进行层级编码,在交互层融入问题主题和焦点信息。具体实现细节与 3.3、4.2 节一致。
........................
第六章 结论与展望
6.1 结论
本文的主要研究及结论为:
尝试了基于问题理解的解答策略。通过识别问题类型、问题主题和问题焦点这三种信息加强模型对问题的理解,其中问题类型通过卷积神经网络和关键词识别,问题主题和焦点通过句法分析获取。最后,将问题类型融入模型的输入层,问题主题和焦点融入交互层得到融入问题理解的解答模型。相关实验表明:问题理解对问题解答有一定帮助,其中问题类型对模型的帮助更大。
研究了基于篇章表示的解答策略。采用层级编码方式对篇章进行表示,获得了更好的篇章语义信息。在相关数据集上的实验表明:对篇章进行层级建模能提高模型对描述类问题的解答能力。同时,我们在上述模型的预测层融入时序关系,对方式类问题的解答进行了进一步的研究,系统性能获得了一定的提升。
实现了基于篇章与问题理解的解答策略。在答题模型中同时融入问题理解信息与篇章的层级表示,并使用文档排序信息和答案后处理策略。在相关数据集上进行测试,模型效果提升明显,最终的 Rouge_L 值和 Bleu_4 值分别提高了约 9%、11%。
参考文献(略)