本文是一篇医学论文,本文首先介绍了Logistic回归、XGBoost、LightG BM三种模型的相关基本理论和模型评价方法,并且进行了数据预处理、数据探索和特征选择,为后续早产儿支气管肺发育不良预测模型的建立和比较奠定基础。
第1章 绪论
1.1研究背景及意义
1.1.1研究背景
支气管肺发育不良(bronchopulmonary dysplasia ,BPD)是一种在早产儿中较为常见的严重呼吸系统慢性疾病,1967年Northway首次提出支气管肺发育不良称之为经典BPD[1],发展到现在支气管肺发育不良的定义、病理生理学特征和管理方法得到了很大改变。以往在患有严重呼吸窘迫综合征的早产儿中支气管肺发育不良经常出现,其病理特征表现为胸部X线可见弥漫性损伤,多种炎细胞在炎症灶聚集与肺实质纤维化等,患儿需要长住院时间治疗。随着现在医学技术的发展,在产前更多的早产儿使用皮质激素进一步促进胎肺成熟、现代化的新生儿护理方法、先进有效的呼吸支持仪器设备和肺表面活性物质替代治疗的情况下生存率得以提升,早产儿越来越多的是轻型支气管肺发育不良,病理特征表现为肺泡数量减少体积增大肺部微血管表现异常并且伴有结构重建等[2]。
该病症是早产儿较为突出的疾病之一。近年来,新生儿护理治疗水平的不断进步这也使早产儿的存活率得到不断提高,但是在早产儿中支气管肺发育不良疾病发生率依然很高[3,4]。早产儿在支气管肺发育不良发病早期死亡风险较高,然而存活下来的患儿也常发生生长发育迟缓、喘息、呼吸道反复感染等疾病。支气管肺发育不良对患儿的神经、呼吸系统等造成的严重伤害持续时间较长甚至可到成年,对患病早产儿健康造成严重伤害,进一步给家庭和社会带来一定负担[5]。
当前国内外对支气管肺发育不良的研究在不断深入也取得了一些成就,但是支气管肺发育不良的发病途径和病因尚未完全明确,现有研究认为早产儿支气管肺发育不良的发生与发展是由先天性因素和后天性因素相互作用相互影响共同产生的结果。目前对支气管肺发育不良还没有特效治疗的办法,因此应用数据挖掘技术研究早产儿支气管肺发育不良相关数据建立风险预测模型十分重要,可以辅助诊断及早发现及早进行积极干预。
........................
1.2国内外研究现状
本文基于数据挖掘技术对早产儿支气管肺发育不良的预测进行研究,因此本章从早产儿支气管肺发育不良影响因素及预测研究现状和数据挖掘在医疗领域的运用两方面阐述国内外研究现状。
1.2.1早产儿支气管肺发育不良影响因素及预测研究现状
支气管肺发育不良是早产儿较为常见疾病之一,随着当代早产儿医学水平的提高越来越多的早产儿特别是出生体重较低的低体重儿存活率逐步提高,患支气管肺发育不良的早产儿数量也因此增加,同时生存质量较低[6]。对于改善早产儿健康水平进一步提高生存质量,国内国外做过大量临床试验,但治疗成效并不突出,这里有个因素非常关键就是我们无法早期预测该疾病的发生,因此无法把有高风险患支气管肺发育不良的早产儿引入到医疗研究中去[7]。此外,早期静脉激素治疗可有效改善有支气管肺发育不良高危风险的预后[8],所以目前国内外关于早产儿支气管肺发育不良影响因素及预测也做了一些研究。
在国内关于支气管肺发育不良影响因素及预测研究中,很多学者采用单因素分析和Logistic回归模型。沙得哈西·卡马力汗等(2019)[9]回顾性研究表明胎龄不同早产儿BPD的发病率也不同,胎龄与早产儿支气管肺发育发生之间的相关系数小于0.05有统计意义,并且运用logistic回归表明出生体重、宫内发育状况、机械通气时间、吸氧时间、肺部感染、产前感染情况是支气管肺发育的独立危险因素。蒋晓乐等人(2020)[10]将早产儿分为实验组(患支气管肺发育不良)和对照组(未患支气管肺发育不良),采用对照研究的方法得出BPD的保护因素与临床高危因素。徐豆豆等人(2021)[11]首先采用logistic回归进行分析得出胎龄、机械通气时间、SNAPPE-Ⅱ评分的回归系数分别为-0.938、0.308、0.089为BPD发生的危险因素,并且采用ROC曲线分析,用SNAPPE-Ⅱ评分为自变量,是否发生BPD为因变量,结果显示预测支气管肺发育发生的ROC曲线下面积AUC为0.778,敏感性、特异性分别为66.7%、77.4%。邹巧巧(2020)[12]研究得出在不同程度的支气管肺发育患儿中血清中IL-33、TNF-α和 NGAL 的含量不同,并根据各因素ROC曲线下面积得出了各指标的预测性能。贾毅等(2020)[13]同样用了Logistic回归进行危险因素分析,然后用脐血血清IL-33和sST2预测早产儿发生支气管肺发生的AUC分别为0.835(95%CI:0.756~0.908)和 0.809(95%CI:0.718~0.895)。Li等(2013)[14]分别用SNAP评分[15]和包括 SNAP评分、胎龄、早产儿呼吸暂停、动脉导管未闭和表面活性剂的组合来预测BPD和死亡,发现高 SNAP 评分是支气管肺发育或死亡的独立预测因子(曲线下面积 [AUC] = 0.78;95% CI,0.70-0.85;p <0.001),与其它围产期危险因素结合时具有额外的预测价值。
...........................
第2章 相关理论介绍
2.1 Logistic回归模型
医学论文怎么写
在线性回归模型中,输出的往往是输入的线性组合,且输出的是一个数值变量,无法解决二分类问题。
Logistic回归模型是广义线性模型的一种。它是一种分类模型,可以通过计算后验概率确定数据类别,在疾病诊断、客户分类等领域有广泛运用。通过该算法可以得到近似的概率从而判断该样本属于哪一类别。它相对于其他线性模型优点在于不用提前对数据的分布进行提前假设,从而可以避免因分布假设不正确带来的问题,Logistic回归的思想是先进行边界拟合,之后再建立边界与分类之间概率联系,实际上是采用回归的方法来解决分类问题。
在分类预测中Logistic 回归可用于二分问题,通过历史数据预测未来结果发生的概率。在早产儿支气管肺发育不良预测分析中,若为支气管肺发育不良,则取值为1;若为非支气管肺发育不良,则取值为0。我们将支气管肺发育不良设置为因变量,将早产儿的临床相关属性,例如性别、孕周、出生体重等变量设置为自变量。根据特征属性来预测是否支气管肺发育不良。
..........................
2.2 XGBoost模型
XGBoost算法[40]最早是由陈天奇博士提出来的,该算法在梯度提升决策树(GBDT)算法的基础上做了一些改进,它是将一组分类回归树(CART)的集成在一起的模型,通常在预测中一棵树的预测强度不足在实践中运用,实际过程中可使用集成模型,它把k棵树中的每棵树对样本的预测相加结合在一起得到最终分数当作该样本中的预测值[41]。在该模型中,不断增加树的数量,树每增加一棵,我们希望可以使模型的性能都有所提高。
近年来,从样本量和特征数量两个方面讲数据量越来越大,因此GBDT在实际时用中也存在着一些新的挑战,在预测的效率与准确性之间难以同时兼顾。在该模型的训练中,当所处理问题维度和样本量都比较大时,该模型就必须通过遍历全部样本进行估计可能分裂点的信息增益。所以,模型在训练中计算的复杂程度与数据量成正比,数据量越大使模型运行效率就会降低。根据GBDT 算法,Light GBM 对其进行了优化提升,从而使得GBDT的训练的速度提高了二十倍以上,同时准确度也与GBDT几乎一样。Light GBM 主要在以下两个方面进行了创新:
在XGBoost中,树的生长方法为按层次生长(Level-wise),虽然在一定程度上使训练速度增快,但是也存在一些问题比如由于部分节点信息增益太小从而进行了一些无谓的计算。与XGBoost不同的地方是LightGBM采用Leaf-wise进行树的生长,该算法每次分裂时都从当前每一个节点中寻找分裂增益最高的节点分裂。在分裂过程中次数相等时Leaf-wise使误差得到了降低,从而提高了精度。为防止太过拟合LightG BM,还在Leaf-wise的基础上限定了树的最大深度,使得模型具有了良好的泛化能力。
.............................
第3章 数据预处理与描述性分析..................................21
3.1数据来源........................................21
3.2数据的预处理............................22
第4章 模型的构建与评估..................................32
4.1特征选择............................32
4.2模型的构建........................33
第5章 结论与展望...........................41
5.1主要结论...........................................41
5.2不足与展望..................................41
第4章 模型的构建与评估
4.1特征选择
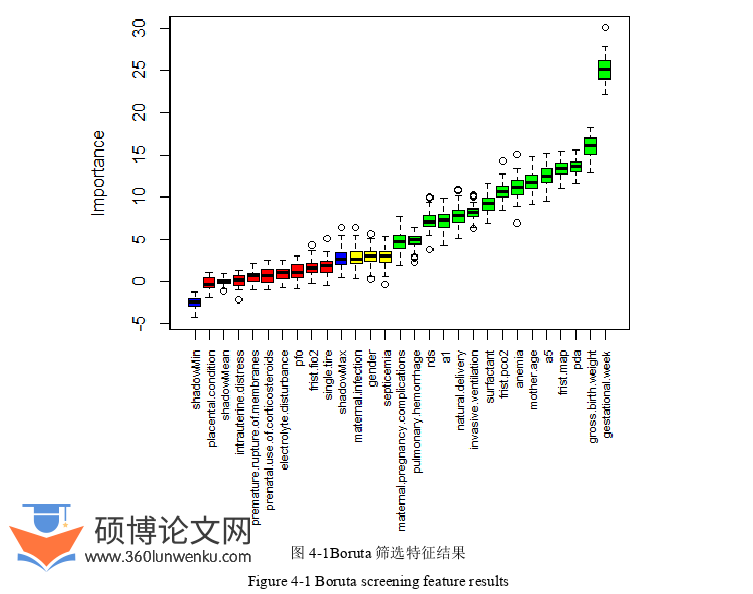
特征选择通常是数据挖掘应用中的一个重要步骤,一般而言现行流行的特征提取方法主要用于提取非冗余的特征,是一个最小最优问题(minimal-optimal problem)[43]而Boruta算法致力于提取与响应变量全相关(all-relevant)特征的问题。这对于医学问题而言是非常有必要的。Boruta算法通过复制所有特征并将其打乱顺序,在每一次迭代中建立一个随机森林模型,并计算每一个属性的Z分数,Z分数的计算为平均损失除以其标准差,将其作为重要程度的度量。在阴影属性中找到最大的Z值,并将其他高于该值的属性分配一个命中值,直到所有属性都被标记重要性或达到随机森林运行限制结束。通过这个过程挑选出与响应变量最相关的特征。Boruta通过增加系统的随机性和从随机样本集合中收集结果,可以减少随机波动和相关性的误导性影响。在这里,这种额外的随机性将使我们更清楚地了解哪些属性是真正重要的[44]。
最初根据早产儿医师建议和相关文献分析使用26个变量其中包括孕母基本情况、早产儿一般情况及治疗情况、早产儿基础疾病及合并症等相关信息作为预测模型变量,但有时候并不是变量越多模型的预测性能也强,变量越多模型的复杂程度越高反而影响了预测结果与预测速度,往往一个小的子集就足以获得强的预测性能。所以我们在研究中运用了Boruta进行特征的选择。
医学论文参考
....................................
第5章 结论与展望
5.1主要结论
本文首先介绍了Logistic回归、XGBoost、LightG BM三种模型的相关基本理论和模型评价方法,并且进行了数据预处理、数据探索和特征选择,为后续早产儿支气管肺发育不良预测模型的建立和比较奠定基础。
在数据预处理与描述性分析部分,本文收集了广西某市妇幼保健院新生儿科接受治疗早产儿临床记录中的相关数据,数据有1135个样本。首先进行数据预处理,处理完的数据剩余1117个样本,然后选出相关变量进行描述性分析。在对数据的描述统计中探索了各变量在是否患病两组中的分布,并且选取了有代表性变量有创通气、RDS、贫血、动脉管未闭(PDA)、母亲年龄、孕周、出生体重等进行了具体分析解释。研究表明早产儿支气管肺发育不良发生受多方面因素影响,因此应重点关注以下几方面问题,以减少早产儿支气管肺发育不良的发生。
在模型构建部分,运用Boruta算法进行特征筛选,筛选出15个重要性较高的变量包括孕周、出生体重、是否PDA、首次使用机时的平均气道压力、母亲年龄、是否贫血、首次使用呼吸机时、是否使用表面活性剂、5分钟Apgar评分、是否RDS、是否使用有创通气、是否顺产、1分钟Apgar评分、是否肺出血、母亲是否有妊娠合并症。然后进行模型建立,通过分析发现数据存在不平衡患病与未患病的比例为1:3.3,这会对模型的预测效果产生影响,所以针对数据不平衡问题本文采用SMOTE算法进行数据集的平衡,使模型可以更好地预测早产儿是否支气管肺发育不良。平衡完数据集之后分别建立了Logistic回归、XGBoost、LightG BM三种预测模型分别用准确率、召回率、精确率、F1值、AUC进行评价,综合比较发现三个模型的准确率都高于80%,Logistic回归模型、XGBoost模型、LightG BM模型的准确率依次提高,其中LightG BM模型的准确率最高,Logistic回归相对较低。LightG BM预测模型整体综合评价指标都比较好F1、AUC分别为0.899和0.956,在临床中可以辅助医护人员进行诊断,提高早产儿生存质量。此外,在建模过程中参数的设置也十分重要,通过调整模型的几个重要参数可以防止过拟合提高模型预测性能。
参考文献(略)