本文是一篇软件工程论文,本文的研究成果不仅为API编排任务提供了高效解决方案,还可广泛应用于科学数据分析、金融建模、医疗诊断和编程辅助等领域。其设计理念和方法为解决大模型的“幻觉”问题提供了一个透明、可追溯的系统化方案,而且显著提升了大模型在实际应用中的可靠性和实用性,进一步推动AI技术的工程化进程,为未来只能系统的开发和应用奠定了重要基础。
1 绪论
1.1 研究背景与意义
大型语言模型(Large Language Model, LLM),如ChatGPT[1],在自然语言处理(Natural Language Processing, NLP) 领域取得了显著进展。以GPT[2]、BERT[3][4]等为代表的预训练模型通过大规模语料训练,展现出卓越的语言理解和生成能力。这些模型在文本生成[5]、机器翻译[6]、问答系统[7]等多个任务中均展现出卓越性能,特别是在零样本[8](zero-shot)和少样本[9](few-shot)学习场景下表现出显著优势。LLM的快速发展不仅革新了传统的人机交互模式,更为人工智能技术的演进提供了新的驱动力。
然而,尽管LLM在许多任务上表现出色,其仍然存在一些固有的局限性。如图1-1-(a)所示,直接将需求输入LLM并期望得到完全正确的答案,往往是不现实的。首先,LLM 对特定领域知识的掌握有限,尤其是在需要高度专业化知识的场景中,其表现往往难以满足实际需求。其次,受限于静态训练数据的特性,LLM 缺乏实时信息处理能力,无法动态获取和整合现实世界的最新数据。例如,在需要查询实时天气、股票价格等涉及真实世界数据的任务需求时,LLM的响应往往滞后于实际情况。这些局限性严重限制了LLM在复杂场景下的应用效果和推广价值,尤其是在需要高实时性、高准确性的任务需求中。
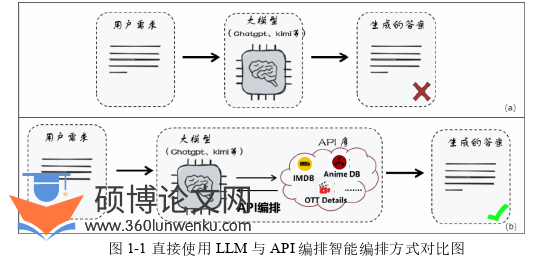
代写软件工程硕士论文API编排方式对比图
.........................
1.2 国内外研究现状
当前,研究人员广泛关注LLM与外部API的结合以提升LLM的能力。现有的API编排方法主要可以分为两大技术路线:基于模型微调(Fine-tuning)的方法[10][11][12][13]和基于上下文学习(In-context Learning)的方法[14][15]。
1.2.1 基于模型微调的API编排方法
随着大模型技术的快速发展,一些研究人员开始探索通过微调开源 LLMs 来增强其在特定任务中的表现,尤其是在集成外部工具和 API 方面。该方法通过在特定任务数据上对预训练模型进行二次训练,使模型能够适应新的任务分布。在工具学习和 API 调用领域,微调方法被广泛应用于增强 LLMs 的能力,使其能够根据用户需求生成调用外部 API 的函数或请求,从而弥补其在特定领域知识和实时数据处理上的不足。
一种典型的微调方法是指令微调[11](Instruction Tuning),该方法通过使用任务特定的指令数据集对LLM进行微调,使其能够更好地理解人类指令并生成适当的响应。例如,Wei等人提出的FLAN框架[12]通过引入多样化的API调用指令,成功增强了模型在多API场景下的泛化能力。此外,自指导(Self-Instruct)方法[13]通过利用现有的 start-of-the-art (SOTA) LLM生成高质量的API调用指令数据,不仅降低了数据标注的成本,还推动了多轮对话数据的构建。
另一种重要的微调方法是提示微调(Prompt Tuning)。该方法通过设计特定的提示模板来指导模型学习API调用模式。Schick等人提出的PEA(Pattern-Exploiting Training)框架通过模式挖掘技术优化提示设计,提升了API调用的准确性。在API编排场景重,该方法通过构建“指令-API”映射模板,如“请调用{API名称}获取{参数}信息”,有效指导模型生成正确的API调用序列。Lester等人提出的P-Tuning v2方法[14]通过引入可训练的连续提示(Continuous Prompts),在API调用任务中实现了更好的参数效率和性能表现。该方法特别适用于处理复杂的API调用链,能够有效捕捉API之间的依赖关系。
......................
2 相关技术和理论概述
2.1 RESTful API
RESTful API(Representational State Transfer API)是一种基于REST架构风格的网络接口设计规范,广泛用于分布式系统和Web服务。其核心思想是通过HTTP协议的标准方法(如GET、POST、PUT、DELETE等)对资源进行操作,从而实现客户端与服务器之间的交互。在RESTful API的设计中,资源通过URI(统一资源标识符)进行唯一标识,客户端通过HTTP方法对资源进行操作,服务器则返回JSON或XML等格式的响应数据[18]。这种设计模式不仅简化了接口的调用方式,还使得不同系统之间的集成更加高效。
在现实世界中,RESTful API被广泛应用于各种场景,例如社交媒体平台(如Twitter、Facebook)、电子商务系统(如Amazon、eBay)以及云计算服务(如AWS、Google Cloud)。这些API为开发者提供了访问海量数据和服务的入口,例如获取用户信息、处理支付交易、管理云资源等。本文选择RESTful API作为API编排的主要对象,主要基于其在现实世界中的广泛应用及其标准化特性[19]。RESTful API的通用性和易用性使其成为智能API编排的理想选择,同时也为本文的研究提供了丰富的实践场景和数据支持。
然而,随着API数量的快速增长,开发者在选择和调用合适的RESTful API时面临诸多挑战。例如,不同API的功能描述、参数说明和使用场景可能存在较大差异,导致开发者在集成过程中需要耗费大量时间进行文档解读和调试。为了解决这一问题,API聚合平台应运而生,其中Rapid API Hub1作为全球最大的API市场之一,为开发者提供了集成的环境,支持多种RESTful API服务的搜索、连接和管理。通过统一的Rapid API密钥,开发者可使用多种编程语言便捷地调用这些API,显著简化了API管理与集成流程。该平台涵盖从数据分析到社交媒体管理等多个领域,每个领域包含多种工具,而每种工具又提供多个API接口。本文从Rapid API Hub上收集了大量RESTful API的原始文档,并对其进行了系统化的分析与增强。
............................
2.2 大型语言模型
语言模型(Large Language Model, LLM)是近年来人工智能,尤其是自然语言处理(Natural Language Processing, NLP)领域的关键技术突破。其本质是基于深度神经网络,通过在大规模文本语料上进行自监督学习,掌握人类语言中的语法、语义、上下文推理以及任务迁移等能力。LLM的广泛应用不仅革新了传统语言任务的解决方案,也成为推动通用人工智能(AGI)研究的重要支柱。
LLM的发展得益于神经网络结构的持续创新,特别是Transformer架构的提出[19]。Transformer摒弃了传统循环神经网络(RNN[20])和长短期记忆网络(LSTM[21])的串行处理方式,转而采用自注意力机制(Self-Attention),可以并行处理整段文本并捕捉词与词之间的长距离依赖关系,从而显著提升建模效率和语言表达能力。这一机制允许模型动态调整对不同上下文词的关注程度,增强了对语义关系的理解与建模能力。
在模型训练方面,LLM通常经历两个阶段:预训练(Pretraining)和微调(Fine-tuning)。预训练阶段,模型在大规模通用语料(如维基百科、网络新闻、书籍语料等)上通过语言建模目标(如自回归语言建模或掩码语言建模)进行学习,掌握通用语言规律[22][23][24];而在微调阶段,模型针对特定任务(如问答、摘要、对话等)或特定领域语料进行进一步训练,以提升在特定应用场景下的表现[25][26][27]。
..........................
3 软件工程化AI驱动的API编排规划方法 ....................... 20
3.1方法总体设计 .................................... 20
3.2 API知识库构建 ....................................... 21
4 软件工程化AI驱动的API编排反思方法 .......................... 32
4.1方法总体设计 .................................. 32
4.2 控制流图生成 ............................... 33
5 实验设计与分析 ................................... 42
5.1 实验设置 .................................. 42
5.1.1 需求数据集构建..................................... 42
5.1.2 基线方法............................. 42
5 实验设计与分析
5.1 实验设置
5.1.1 基线方法
为评估本文所提出方法的有效性,本研究选取了以下基线方法进行实验对比与分析:
(1)Yao等人提出的ReAct[15]方法采用“Thought-Action”机制,通过推理与外部API调用的交替执行完成任务。为实现该方法,本文从GitHub上获取其标准提示模板,并将基于相似度检索得到的前k个候选工具及对应文档整合至提示模板中,以实现API的精准调用。此外,为确保方法执行的完整性,本文额外设计了一个结果解析模块,利用大语言模型(LLM)从API返回的JSON响应中提取当前推理步骤所需的关键信息,从而提高信息处理的效率与准确性。
(2)Wang等人提出的CodeAct[16]框架创新性地将LLM的推理能力与代码执行相结合,通过生成并执行代码来实现复杂用户需求。为保证实验对比的公平性,本文采用与代码生成模块相同的提示模板(不包括伪代码生成部分)来生成可执行代码。同时,为提升代码执行的成功率,本文沿用代码修复模块的提示模板,对执行过程中出现错误的代码进行自动修复,从而确保实验结果的可靠性。

代写软件工程硕士论文API编排反思方法效果评估图
............................
6 总结与展望
6.1 总结
为了提升LLM对复杂任务的解决能力,本文聚焦于API智能编排研究,提出了一套基于软件工程化AI驱动的API编排与反思方法。
针对API编排规划过程难以选择正确API问题,本文设计了一种软件工程化AI驱动的API编排规划方法。该方法基于软件工程宏观架构原则,将API编排过程划分为设计和实现两个阶段。在设计阶段,通过合理的任务分解,明确需求各个子任务的职责,从而为完成需求而选择正确的API,并在伪代码中设计出合理的API调用逻辑。特别地,本文还提出了一套API知识库构建流程,用于构建高质量的API知识库,为API选择和使用提供了可靠的数据支持。
此外,针对无法避免的错误发生,本文提出了一种软件工程化AI驱动的API编排反思方法,旨在实现快速错误恢复。具体而言,本文提出了一种动态迭代与反馈驱动的策略,通过逐步缩小问题范围,判断错误源自API规划的设计层还是实现层,进而有针对性地对设计层的伪代码或实现层的可运行代码进行修复,这不仅实现了更精准的问题定位,还显著提高了修复效率。
在实验部分,本文从多个角度对所提方法进行综合评估。实验结果显示本文所提的API编排规划与反思方法在任务完成的准确性和资源消耗方面均优于传统方法。消融实验也进一步证实了本文任务分解与API指派单元、伪代码生成AI单元以及控制流图生成非AI单元在提升方法性能中的关键作用。同时,动态迭代与反馈驱动的策略显著提高了错误定位与修复的准确性和效率。此外,体现在每个AI单元中的微观实现原则,进一步提升了LLM输出的准确性。
参考文献(略)