本文是一篇医学论文,笔者认为为了进一步提高HMM算法在PACU呼吸暂停检测中的准确度,我们用深度学习去噪网络对PACU中的呼吸音数据进行了去噪处理,并用HMM对去噪后的呼吸音进行呼吸暂停检测,检测结果表明深度学习算法在呼吸音降噪处理方面要优于自适应滤波算法。
4 材料与方法
4.1实验数据
4.1.1 网络训练数据
(1)选取干净的呼吸音数据:本实验的训练数据与第一部分实验的训练数据均来自同一批受试者,但采集时受试者呼吸模式有所不同。本实验训练数据在采集时,根据研究人员的提示,第一分钟受试者平静呼吸,第二分钟提示受试者快速呼吸一分钟,第三分钟受试者慢速呼吸两分钟,第五分钟开始,受试者恢复正常呼吸直到该阶段结束。该阶段数据采集过程持续时间为13min,呼吸音的采样频率为22050Hz。选取46个受试者的第8分钟~第13分钟的正常呼吸数据,总时长为230分钟,将选取的所有音频按每段10s进行分段处理,共得到1380段呼吸音数据。在这1380段数据中选取呼吸幅度大,无鼾声说话声,无研究人员干扰的呼吸音片段1000段。
(2)合成含噪呼吸音数据:录制一段与医院有关的纪录片的音频,时长为40min,采样率为22050Hz,作为背景噪声。在40min背景噪声中随机选取1000条10s的噪声与1000条10s的纯净呼吸音分别按信噪比为5db,10db,15db,20db合成1000条含噪呼吸音,我们经过实验研究发现,当信噪比为20db时,最接近真实医院环境中的噪声,降噪效果更好。所以最终按信噪比为20db合成1000段含噪呼吸音数据作为训练数据。
4.1.2 网络验证数据
取纯净呼吸音数据和含噪呼吸音数据各1%作为验证数据,纯净呼吸音数据作为网络的目标变量输入,含噪呼吸音作为网络的预测变量输入,选取的1%的含噪呼吸音是通过1%的纯净呼吸音加噪得来的,两者是相对应。每轮训练结束后,通过验证数据来调整网络训练的参数。
.............................
4.2实验方法
4.2.1 级联冗余卷积编解码网络
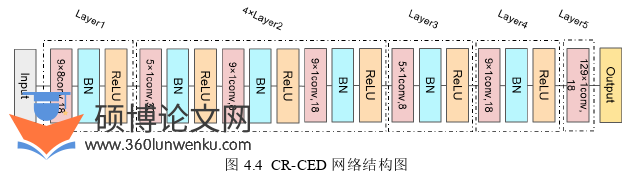
级联冗余卷积编码器-解码器(Cascaded Redundant Convolutional Encoder-Decoder Network, CR-CED)网络,简称CR-CED网络。它是R-CED网络的一种变体,由R-CED网络的重复组成。CR-CED网络由二维卷积(Two-dimension convolution, 1-Dim Conv)、批处理归一化(Batch Normalization,BN)和修正线性单元(Rectified Linear Unit, ReLU)激活层的重复组成[21]。该网络没有池化层,因此不需要上采样层。与卷积编解码网络(Convolutional Encoder-Decoder Network,CED)相反,R-CED网络沿着编码器将特征编码为更高维度,并沿着解码器实现压缩。滤波器的数目保持对称:在编码器处,滤波器的数目逐渐增加,在解码器处,滤波器的数目逐渐减少[30]。编码器首先对特征图进行二维卷积,然后进行批次归一化,最后通过激活函数得到每一层的输出。BN 层对数据进行减均值和去相关等操作,使得卷积后的数据特征满足独立同分布假设,激活函数采用ReLu加快收敛速度,缓解梯度消失、爆炸问题,简化计算。解码层是还原特征图的位置信息[31]。与相同网络大小即相同参数的R-CED相比,CR-CED具有更好的性能,且收敛时间更短。其网络结构如图4.4所示。本实验所用CR-CED网络是由5个R-CED网络级联组成,最后一层是卷积层,这样整个网络是全卷积神经网络,共有16个卷积层。前15个卷积层是由重复5次的含3个卷积层的组级联组成的,过滤器数量分别为18,30,8;过滤器的宽度分别为9,5,9;最后一个卷积层有1个过滤器,宽度为129。在此网络中,卷积仅在频率维度方向上进行操作,第一层卷积沿时间维度的过滤器宽度设置为8,其余卷积层沿时间维度的过滤器宽度设置为1。
医学论文参考
.............................
5 结果
5.1 实验结果
5.1.1 网络训练结果
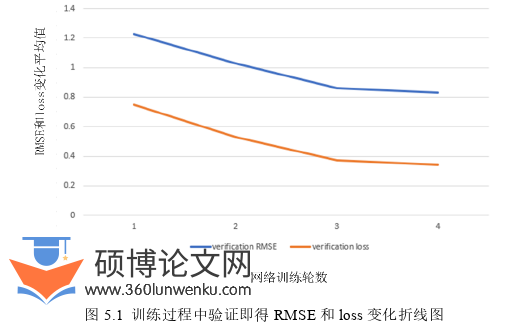
本实验通过验证集在网络训练过程中预测该模型的好坏并及时根据预测结果调整参数,以达到训练为最优模型的目标。图5.1即为训练过程中验证数据的RMSE的值以及损失函数loss的变化曲线。网络一共迭代4轮,所以我们记录每轮迭代后的RMSE和loss的平均值。经过多次训练与调参,我们最终得到,RMSE值为0.83,loss值为0.34时,网络训练结果是最好的。
医学论文怎么写
..........................
5.2 HMM对网络测试后的数据进行呼吸暂停检测结果
本实验所用的测试数据来自PACU,其中患者得统计学资料如表5.1所示。有121名患者参与该次实验,其中5名患者的统计学资料不慎丢失,用于本实验的呼吸音时长为52.6小时,在此期间共发生呼吸暂停236次,暂停持续时间为122.2分钟。

医学论文参考
用CR-CED网络对测试数据去噪处理之后,用HMM对去噪后的呼吸音数据做呼吸暂停检测,具体检测方法与第一部分所描述方法相同。下面主要展示检测结果。
............................
4 材料与方法................................ 17
4.1实验数据 ........................................ 17
4.1.1 网络训练数据................. 17
4.1.2 网络验证数据......................... 17
5 结果........................ 22
5.1 实验结果 .......................... 22
5.1.1 网络训练结果........................ 22
5.1.2 网络测试结果........................ 22
6 讨论 ........................... 26
6讨论
用HMM方法对中度镇静状态下的呼吸音数据进行呼吸暂停的检测,其检测结果的敏感度为98%,特异度为95%,准确度为96%,相比于阈值法来说,敏感度、特异度和准确度均提高了3%。该结果验证了我们的假设,HMM算法不仅可以应用于PACU中同样也适用于患者处于中度镇静状态下的场合,且该方法的表现性能比阈值法要好。
第一部分实验所用到的测试集数据相对于PACU中的呼吸音数据来说是比较纯净的,没有复杂的背景噪声的干扰,所以噪声对HMM识别过程中的干扰时比较小的。我们从以下几个方面分析了漏诊与误诊的原因以及实验改进的方法:一是患者在呼吸暂停期间,由于喉咙发出声音,使HMM将其误认为呼吸声从而导致暂停时间未持续15s,从而导致漏诊;另一个方面是有些时刻呼吸音短小急促并伴随着打鼾声打呼声,HMM作为一种机器学习模型无法将其识别为正常呼吸,造成误诊;第三个原因是呼吸声音太弱,幅度太小,HMM将其误诊为呼吸暂停,造成误诊。以上三个方面是造成实验漏诊和误诊的主要原因,我们针对这些原因提出了改进方法:首先可以将呼吸状态进行多分类,比如吸气,吐气,暂停,打鼾,说梦话等,训练多类模型可以提高HMM识别的准确度;其次针对呼吸声音幅度小的问题,可以通过放大呼吸音强度来增强其识别特征。
通过图3.2来看,HMM方法和幅度阈值法对同样的呼吸数据进行了呼吸暂停的检测,其检测结果的敏感度,特异度和准确度分别从数值上进行了比较,其结果都是HMM方法表现更好。由于两个数值无法进行统计学分析,所以我们单从数值上进行了大小的比较来证明HMM方法的优越性是可行的。
............................
7 结论
本文用HMM方法对中度镇静状态下采集到的呼吸音数据进行了呼吸暂停的检测,实验结果证明了HMM算法用于中度镇静患者的呼吸暂停检测是可行且有效的;为了进一步提高HMM算法在PACU呼吸暂停检测中的准确度,我们用深度学习去噪网络对PACU中的呼吸音数据进行了去噪处理,并用HMM对去噪后的呼吸音进行呼吸暂停检测,检测结果表明深度学习算法在呼吸音降噪处理方面要优于自适应滤波算法。
参考文献(略)