本文是一篇软件工程论文,本文提出了自适应知识选择交互会话生成模型,针对将知识选择与响应生成被当作两个独立的步骤分开进行导致最后的响应生成与知识信息融合不足的问题,考虑在响应回复生成的过程进行知识选择。
第一章 绪论
1.1研究背景及意义
目前主流的人机交互方式主要是通过键盘、鼠标等外设,在人工智能时代,人们试图让机器理解人类所说的语言,并以人类语言的方式提供及时的响应和反馈,从而方便人类以更快捷地方式享受机器提供的服务[1]。人机会话技术最早始于1950年,自从Alan Turing提出用图灵测试[2]作为检测机器是否具有人类智能的方法后,人机会话系统的研究就此展开。
早期的人机会话系统,例如Eliza[3]等人机会话系统,这些系统可以与人类进行一些简单的会话,尽管在一定程度上取得成功,但其内部机制主要是依靠手工定制的模式匹配规则,这种方法只在一定规则的限制环境下才能有较好的表现[4],基于这种方法的人机会话系统远远不能通过图灵测试。
随着互联网的发展普及,数据量呈现爆发增长趋势,使以数据为基础的深度学习技术成为当前人工智能领域的主流方法[5],被广泛用于自然语言处理(Natural Language Processing, NLP)任务当中,NLP是当前人工智能的热门研究领域和技术前沿,其中人机会话系统作为NLP的重要组成部分,其目的就是探索机器如何才能与人类进行直接的交互。目前,面向各种任务的人机会话系统也已出现在人们生活中的方方面面,例如苹果的Siri语音助手[6],可以与用户进行交互式问答,获取用户需求,并帮助用户完成查询资料,设置时钟,订购机票等任务。这些人机会话系统应用于各个平台中,为用户提供方便快捷的服务。
.............................
1.2国内外研究现状
人机会话系统是NLP领域的重要任务之一,自上世纪起就倍受人们关注,在人工智能时代更是焕发出全新的生命力。至今为止,人们对于人机会话系统也提出更高的要求,希望人机会话系统与人类展开更有意义的会话过程,使机器为人类提供更高效便捷的服务。会话生成作为人机会话中的关键技术环节,对整个人机会话系统的发展起到至关重要的作用,目前,针对会话生成的研究已有大量显著成果。此外,整合外部知识提供除会话上下文之外的信息是当前提高人机会话系统性能的有力途径。
1.2.1人机会话系统研究现状
会话生成的目的是将机器处理得到的结果转换成人类可直观理解的自然语言,当前会话生成的主要途径分为两类:检索式模型和生成式模型。
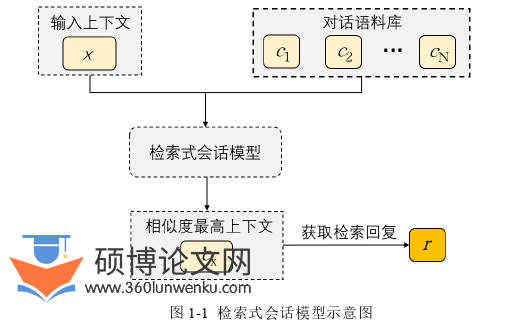
检索式会话模型的一般步骤是先构建一个大规模的会话语料库,其形式与问答系统的问题-答案对类似,在会话过程中,将当前会话上下文作为输入,即查询语句。通过信息检索与语义匹配的方式[12],或者是利用基于深度学习的方式[13]从海量会话语料库中选择与当前会话上下文最匹配的问题-答案句子对,从而获取最恰当的回复。微软的聊天机器人小冰[14]就是检索式会话模型的一个典型应用。检索式会话模型的示意如图1-1所示。通过检索式会话模型得到的回复都来自于语料库,而语料库中的语句都是通过人工修订而得到的,因此语句基本没有语法上的错误,语句质量较高。但受限于当前会话上下文以及会话语料库大小规模的限制,容易出现检索失败或者得到回复与会话上下文不相关的情况。
软件工程论文怎么写
.............................
第二章 相关理论与技术
2.1文本向量化技术
在NLP任务中,输入模型的并不是人类语言,而是一种经过处理后的语言表达形式,因为不论何种人类语言都无法直接参与到深度学习神经网络模型的计算,所以需要使用向量化的技术表示要输入模型中的文本。文本表示的好坏程度对模型性能有极大的影响,因此该处理过程十分关键。
2.1.1 文本预处理
文本预处理工作是文本向量化工作的基础,预处理结果的好坏对NLP任务有着直接的影响,是会话生成任务至关重要的一环。预处理的目的是将数据变为结构化形式,接着再将其映射到向量空间。文本预处理的基本步骤一般是:取得原始文本数据、分词处理、文本清洗以及标准化[40]。对于英文文本则不需要分词处理的操作,因为英文中存在天然的空白符号做分隔符。文本清洗操作一般是去除非必要的标签,英文大小写转换,去除停用词以及归一化等。在文本中,可能存在大量的高频词,比如“a”、“of”、“the”等介词或冠词,这些词语并不会携带特殊的信息,除了使文本显的更复杂外,对于最终会话的生成并无太多意义,去除停用词的一般方法是使用常见的停用词表。标准化的操作一般是词形还原和词干提取,二者的作用都是将将英文单词统一为相同的表达方式,达到降低文本复杂度的目的。词形还原一般是将词语变成最原始形态,是一种“转变”的方式,比如单词breaks,broke,breaking都可以被还原成为break。词干提取通过“缩减”方式将词转换为词干,也就是将词形变为最基本的形式,比如connection,connecting,connected都能被提取词干为单词connect。通过这些方法去除了单词的各种后缀,能有效降低单词的数量,可以为下一步的操作节省时间和空间,降低文本生成任务的复杂性。经过者一系列的预处理操作之后的文本,通过进一步特征提取,就转换成相应的向量空间形式作为模型的输入。
...........................
2.2循环神经网络
循环神经网络(Recurrent Neural Networks, RNN)[47-50]是NLP任务中最重要的一种神经网络,NLP任务所处理的基本都是序列信息,前后的输入是有关联的,这要求网络需要具备一定的记忆性。循环神经网络获取文本序列数据,按照序列演进方向进行递归计算,按照链式连接的方式将网络中的节点依次相连,这种结构让网络中每个节点都会受到前一个节点的影响,从而使网络具有记忆性。正是这一特点,循环神经网络被广泛应用到会话生成任务中。本节将对基本的RNN以及其两种常用变体LSTM[18]和门控循环单元(Gated Recurrent Unit,GRU)[51]进行简要介绍。
(1) RNN
传统的神经网络模型基本结构主要有输入层、隐藏层和输出层,每个层间相互连接,但输入和输出之间相互独立,t时刻的计算只和前一时刻t-1有关,而对于比如翻译任务,天气预测任务来说,传统神经网络具有局限性。RNN除了考虑当前时间步t时刻的输入外,还将之前节点的输出也作为输入,赋予网络记忆的能力,这种方式在处理与序列相关的问题上更具优势。
(2) LSTM
理论上RNN可以处理任何长度的序列数据,但经过实践后发现,RNN在处理较长序列时表现不佳,这是因为每一次信息传递时,上一时间步保留信息都在一定程度上被削弱,一旦序列规模较长,这种削弱会不断累积,最终使得序列靠前的信息被网络“遗忘”,也就是长期依赖问题(Long-Term Dependencies Problem)[55]。为了解决这个问题,针对RNN模型的改进有很多,其中最著名的就是LSTM。
.......................
第三章 基于孪生网络的知识驱动会话生成后验知识选择模型 ........................... 20
3.1概述 ............................................... 20
3.2模型设计 ........................................... 21
第四章 自适应知识选择交互会话生成模型 ............................ 35
4.1概述 ........................................ 35
4.2模型设计 ................................ 36
第五章 总结及展望 .................................... 47
5.1工作总结 ....................................... 47
5.2研究展望 ................................... 47
第四章 自适应知识选择交互会话生成
模型4.1概述
通过上一章节内容的实验分析,我们发现所提出的模型方法在知识选择和最后的响应回复生成中都可以取得不错的效果,但通过后续的研究也发现诸多不足。主要体现在对于相关知识信息的检索与利用方面。首先,利用非结构化文本的生成模型很大程度上依赖于文本的质量,而且非结构化的知识信息因其结构形式,存在很多冗余知识信息,这导致知识关键点提取难度大。此外,生成式会话模型在解码阶段,会从语义相近的词汇中选择出现频率高的词语,例如,如果在训练语料库中“北京”的出现频率比“华盛顿”高,当会话上下文询问“美国的首都是哪里?”,生成模型很可能会回复“北京”。其次,上一章节中将知识的选择和响应生成视作两个独立的步骤并按照顺序依次进行处理,将知识选择中所挑选的知识送入解码器中辅助响应回复的生成,这是一种静态使用知识信息的方式。但现实生活中人类的会话过程不是静止的,在会话时人类会结合已产生的回复信息并结合自身的背景知识给出接下来的回复,是一种发散跳跃的动态方式。而包括本文上一章节在内的很多方法都只是选择与会话上下文最相关的固定知识信息引导模型逐步生成响应回复,但在回复响应不断产生的过程中,已出现的回复词对之后的会话状态也会产生影响,所需要的知识也应该随着会话状态的变化而变化。这种方式会导致挑选的知识信息与响应生成器无法充分融合,有可能会导致解码过程中知识信息的置信度下降,从而产生不恰当知识词的搭配。

软件工程论文参考
............................
第五章 总结及展望
5.1工作总结
随着科技的不断进步以及人力资源成本的增加,让机器与人类展开会话,为人类提供能直接理解的响应回复的需求越来越强烈,人机会话系统有望成为主流的人机交互方式。然而传统的人机会话系统还有很多地方需要改进,以深度学习为当代主流方法的人机会话系统,仅仅通过会话数据进行训练,其最后生成的响应回复中包含的信息量较低,人类语言的表达使用背景知识作为支撑,因此本文在深度学习会话系统的基础上,整合外部知识信息,聚焦带有知识信息的会话生成技术研究。现将本文的主要工作内容概括如下:
(1)本文提出了基于孪生网络的知识驱动会话生成后验知识选择模型,通过由先验-后验知识选择模块和基于孪生网络的多粒度匹配模块组成的知识检索器,提升模型选择恰当知识的准确性。在先验-后验知识选择模块,利用真实响应回复中蕴含的正确知识信息得到后验知识分布,同时将后验分布作为软标签指导先验分布的生成,使得模型在无法获取真实响应信息时也可以选择正确的知识信息。为解决先验知识分布和后验知识分布中的暴露偏差问题,设计基于孪生网络的多粒度匹配模块,进一步提升检索正确知识的准确率。为了将知识信息更好的融入响应生成中,设计知识事实感知解码器,提高响应回复中包含的信息量。
(2)本文提出了自适应知识选择交互会话生成模型,针对将知识选择与响应生成被当作两个独立的步骤分开进行导致最后的响应生成与知识信息融合不足的问题,考虑在响应回复生成的过程进行知识选择,设计基于双重拷贝复制机制的动态知识选择解码器,根据当前已产生的响应回复信息从候选知识集合中进行挑选,将与当前时间步最相关的知识信息融入解码生成的过程,同时利用指针网络,从输入上下文和所选知识中进行知识实体词的复制,提高包含的知识信息性以及与输入上下文的相关性。
参考文献(略)