本文是一篇软件工程论文,本文基于最小化类混淆方法,提出两种不同的算法用于应对无监督领域自适应存在的问题。由于领域自适应属于分类模型,在实际应用场景中,需要保证对每个样本的分类预测置信度与真实概率保持一致,以确保分类模型的可靠。同时在实际应用中,对于难以大量的获取带有标签的数据样本的情况,还需要解决数据集中小样本的问题。
第一章 绪论
1.1 选题背景以及研究意义
近些年里,深度学习擅长从具有大量标签标记的数据集中学习判别性特征表示,从而在各种机器学习任务中取得了空前的成功。在有监督场景下的机器学习各个领域都取得良好的成绩。如自然语言处理(Natural Language Processing, NLP),计算机视觉(Computer Version,CV)和机器人控制。伴随着具有大量标注的数据集推出,作为深度学习的研究之一,便是设计出一个更加高效,稳定的神经网络模型结构。首次出现的 AlexNet[1]网络相较于处理图像分类任务的传统算法,在算法的性能上有较高的突破。同时还证实了神经网络具有学习判别性特征表示的能力;随着 2014 年 VGG[2]网络的提出,该模型证明了网络层的深度有助于模型学习判别性特征表示的能力;而 ResNet[3]的提出,再次证实了网络层深度的重要性,同时确立了卷积神经网络在处理 CV 中各类任务的地位。
然而近些年来即便有越来越多的更高效,学习判别性特征表示更强的网络模型被提出,但是它们依赖于大量标注数据学习才能有良好表现的弱点,限制了算法模型的性能。即使在数据足够多的带标注的数据集上,训练得到一个神经网络模型,一旦当我们将它运用到另一个相似但独立的数据集上时,模型的分类性能可能会严重下降。但是在现实中,这种跨域应用是很常见的。例如在白天收集到一个由摄像头拍在高速上通行的汽车所组成的数据集,并使用其训练一个神经网络的分类模型,然而该模型难以对在夜晚对该条公路上的汽车进行有效地分类。训练得到的神经网络分类模型难以适应这种跨域之间的差异,因为两个数据集在光照强度、拍照角度等因素存在差异。如果通过人工重新标注夜晚的公路上的车辆组成新的数据集,需要的开销很大,而且公路会变换不同的场景,不同时刻的光照也不相同,拍摄的相机规格也不尽相同,因此无法对每个情况都单独进行数据标注工作,并训练一个神经网络分类模型。
.............................
1.2 论文研究思路
在无监督场景下的领域自适应进行图像分类任务时会存在的两点不足,本文提出了基于类间显著性的最小化类混淆的方法,解决在闭合集上领域自适应中分类器在目标域上区分正确类和不确定类时会产生混淆的问题,并且使样本的特征分类预测置信度能与真实分类概率差距最小化;其次使用了生成对抗思想,通过在源域中使用风格迁移增加了源域样本的特征空间中能与目标域样本的特征空间进行匹配的共享特征,克服了因源域的样本特征稀疏问题带来的跨域学习目标域能力不足的问题,增强了分类器跨域分类能力,基于此本文提出基于风格迁移的领域自适应算法来解决在闭合集中的领域自适应问题;通过对几个公开数据集,遵循 UDA 的标准评估协议进行了对比实验,证明了本文算法的有效性。
处理图像分类任务,是神经网络最为常见的应用任务。从 2012 年 AlexNet问世以来,在 ImageNet 图像分类大赛上,以绝对的优势夺得冠军开始,卷积神经网络在处理图像分类任务时,越发的展现出了其优良的性能。高度依赖数据驱动向来是卷积神经网络的缺陷,而通过无监督场景下领域自适应算法可减少神经网络对大量标注数据的需求。近些年来大多数主流的无监督领域自适应算法研究都是通过努力拟合源域和目标域之间的特征分布差距[23],来使得模型能有好的正迁移效果。但是仍然有两个问题没有得到解决。其一便是在对目标域样本特征进行分类预测时,分类器会在正确类和不确定类之间产生混淆预测的倾向。源域样本相较于目标域样本而言,会存在拍摄的背景不同,物体遮挡,光照条件不同以及目标物体只有部分出现在图像中等问题。同时在数据集中还会存在多个相似的类别,这些具有细粒度的类别样本也会造成分类器的混淆预测。有研究团队通过对目标域的预测误差分析,发现分类器在目标域上区分正确类和不确定类时会有产生混淆的倾向。这个发现提供了新的视角来解决领域自适应问题:类混淆。如图 1-2 所示,图(a)表示在有标签的源域中训练得到的分类器,进行分类预测的结果。图(b)表示将源域训练得到分类器,跨域在没有标签的目标域上进行分类预测时,产生的混淆预测结果。该团队通过对分类器预测目标域样本概率内积它的转置,揭示了不同类之间的混淆关系。从这个角度量化类混淆,从而仅基于分类器的预测就可以计算出类混淆。他们提出了最小化类混淆(Minimum Class Confusion,MCC)损失函数,发现较少的类混淆会带来更多的跨域正迁移效益。但是,在无监督(Unsupervised Domain Adaptation,UDA)场景中他们仍然无法解决共享特征稀疏带来的分类器正迁移学习能力不足的问题。

软件工程论文怎么写
................................
第二章 无监督领域自适应图像分类研究现状及难点
2.2 基于特征的领域自适应研究现状
近些年,领域自适应算法已经广泛的运用到了 CV 的各类场景任务中,主要的目的是减少两个领域数据样本在特征空间上的特征分布差异,减低人工标注成本。基于特征的领域自适应算法主要是利用特征提取器获取到样本数据的特征,利用有效的度量手段估计出该领域的样本数据特征空间分布,最后再最小化两个领域之间的特征空间分布差异,使得特征提取器能很好的提取到两个领域的共享特征[27]。
2.2.1 最大均值差异度量
在以往的研究中,大多数算法利用最大均值差异(MMD)的方式来度量两个领域之间的特征空间分布差异。对给定的两个领域的样本数据,通过构建一个样本数据的特征空间连续函数 f ,使用 f 映射得到函数值并求出均值,经过作差运算后,便可求出两个领域样本数据集在函数 f 上的均值差异。通常在领域自适应任务中会将函数 f 定义成核函数,它的作用是将特征提取器所提取的特征,通过映射到可再生核希尔伯特空间(RKHS)上,再对两个领域的数据特征的空间分布差异,在 RKHS 中进行计算。常用的核函数包括高斯核以及线性核等。
近些年来,随着深度神经网络迅速发展,相关研究表明利用神经网络来提取特征,可以具有良好的迁移效果,之后的相关算法研究注重设计不同的神经网络结构,以此来发挥出 MMD 的能力。
DAN[9]算法是基于 MMD 并使用到神经网络结构中的经典领域自适应算法之一。DAN 算法通过在不同网络层多次使用最大均值差异,解决先前研究只在一层网络结构中使用 MMD 来最小化导致的迁移性能受限的问题。DAN 算法的提出者认为只进行一层网络层的 MMD 计算是不够全面的,只使用一个且固定不变的核函数并不一定会是最好的核函数。所以 DAN 算法在网络深层结构中,使用不同的核函数对不同的全连接层进行 MMD 最小化。
RTN[10]算法对 DAN 算法进行了改良。先前的研究都是通过假定特征提取器能够提取出两个领域之间的共享特征,因此对于源域和目标域是可以使用同一分类器。RTN 算法则提出了一个更加可靠的设想:两个领域的分类器之间存在摄动方程。RTN 算法提出者通过使用残差连接的方式来模拟出这种摄动方程,又将 MMD 使用到神经网络中,从而在学习到领域之间共享特征的同时,又学到目标域中特定的分类器。
..............................
2.3 基于样本的领域自适应研究现状
领域自适应研究除了使用基于特征的方式进行,也有相关的研究工作着重于探讨数据集样本之间的关联。例如利用聚类的方式来研究样本类别间存在的多模态结构信息。利用基于样本的方式进行领域自适应的算法可追溯到传统的非深度学习上。这类算法主要是对目标域中所有的样本进行分析,从而找出其与源域中每个样本之间关系。
2.3.1 传统的领域自适应方法
在深度学习被提出之前,关于领域自适应的研究是利用统计方法或是传统的机器学习方法来获取样本浅层中特征。早些年[36][37]等研究工作是通过计算两个领域之间的样本的相似度,然后选取与之对应最相似的源域中的样本,同时对目标域样本的特征加权进行优化。这种递进式的方式从易到难地减少两个领域之间的特征空间分布差异。在 2012 年 GFK[42]算法提出通过测地线的方法将源域样本数据的特征分布转换到目标域。它是通过将两个领域的样本数据映射至高维的空间(Grassmann 流形)中,再对这两个领域样本数据映射在高维的特征空间的点的测地线中间的距离切分成多个细小的中间点,然后依次将它们连接起来,从而在两个领域之间形成一条测地线。最后使用合适的转换方式进行每一步的中间点之间的变换,从而完成由源域至目标域数据样本变换。
这类算法使用了递进式由易到难的迁移学习思想和原型网络算法中簇心这一概念,但是该类算法仍然存在缺陷,那便是忽略了噪声样本对于领域中样本数据的统计分布进行估计时干扰,即噪声样本会干扰估计簇心。另外筛选伪标签需要人为制定阈值,这需要有足够的调参经验。有相关的研究探寻用样本数据中具有重点可迁移的区域和领域中具有重点可迁移样本来细化整个领域自适应的实验过程,TADA 算法通过将注意力机制添加进无监督场景下的领域自适应算法的网络结构中,同时在局部特征的层面增加特征注意力机制和全局特征的层面增添了样本的注意力机制,重新标记了样本的局部和全局中存在的可迁移的特征。
...............................
第三章 最小化类混淆、ECE 校验以及风格迁移的技术分析 .............................. 18
3.1 引言 ................................... 18
3.2 图像分类的网络结构 ................................... 18
3.3 最小化类混淆的技术分析 .................................... 20
第四章 基于显著性水平的无监督领域自适应 ............................. 29
4.1 引言 .......................................... 29
4.2 算法流程描述 .................................... 29
4.3 无监督领域自适应图像分类的网路结构 ....................... 30
第五章 基于风格迁移的最小化类混淆领域自适应 ..................... 40
5.1 引言 ................................. 40
5.2 算法描述 .................................. 40
第六章 实验与分析
6.1 引言
在此章节中,将使用数据集 Office-31 和数据集 ImageCLEF-DA 并遵循 UDA的标准评估协议来与最先进的无监督的领域自适应算法进行比较,评估本文所提出的算法。为了公平,本文使用了已公布论文的实验结果。本文比较了 2020 年公布的 RADA 算法和近些年最先进的基于 ResNet-50 网络结构的迁移学习方法:深度域混淆(DDC)[52]、深度领域自适应网络(DAN)[53]、残差转移网络(RTN)、域对抗神经网络(DANN)、对抗性鉴别领域自适应(ADDA)、联合适应网络(JAN)、多个域对抗网络(MADA)、协同对抗性网络(CAN)、联合鉴别领域自适应(JDDA)。传统的机器学习方法有:通过转移成分分析的领域自适应(TCA),无监督领域自适应的最短线流核(GFK)。
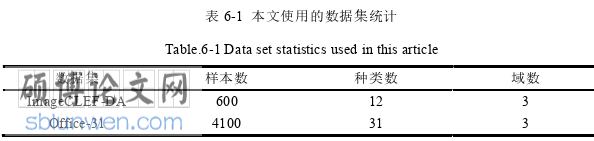
在标准的闭合集场景下进行领域自适应实验,如表 6-1 所示。本文将在数据集 Office-31 和数据集 ImageCLEF-DA 中验证本文算法的效果。ImageCLEF-DA数据集是从三个已公开的数据集里面挑出 12 个具有公共类别的图像所组合而成的数据集。所有的图像都来自于三个公共数据集:Caltech256 (C)、ImageNet ILSVRC 2012 (I)和 Pascal VOC 2012 (P),三个数据集共有 12 个共同类别,每个类别 50 张图像,一共 600 张图片数据。用 I→P, P→I, I→C, C→I, C→P, P→C 的所有域组合来测试本文的迁移学习算法。Office-31 数据集也是无监督的领域自适应实验的基准数据集之一,共包含 31 个类别的 4110 幅图像,所有的图片都是从三个不同的领域收集的: Amazon (A)、DSLR (D)和 Webcam (W)。A→B 表示 A 作为源域、B 作为目标域的领域自适应学习。各个数据样本的可视化如图 6-1所示。
软件工程论文参考
..............................
结论与展望
总结
本文基于最小化类混淆方法,提出两种不同的算法用于应对无监督领域自适应存在的问题。由于领域自适应属于分类模型,在实际应用场景中,需要保证对每个样本的分类预测置信度与真实概率保持一致,以确保分类模型的可靠。同时在实际应用中,对于难以大量的获取带有标签的数据样本的情况,还需要解决数据集中小样本的问题。本文针对这两类问题,通过研究影响分类预测置信度的因素,使用了新的概率输出函数替换了 softmax 函数,使得预测置信度与真实概率之间的差距最小,保证率算法模型的可靠。同时,利用生成对抗网络在带标签的源域上进行分类迁移,以提供更多可以与目标域特征空间匹配的有相关性的共享特征,从而解决小样本问题带来的负迁移效果。
在 UDA 的标准评估协议下,在多个数据集中与近些年提出的先进的无监督的领域自适应算法进行多次的实验比较,表明了本文提出的算法在解决上述问题上均优于其它方法。
参考文献(略)