本文是一篇农业论文,本文系统构建分为模拟模型构建和管理系统构建,在构建灌溉制度优化模型、种植结构优化模型和系统过程模型的基础上,构建数字灌区管理系统。
1绪论
1.1 研究背景与意义
随着信息化技术的蓬勃发展,现代信息物理空间世界的数字化和普及的程度越来越明显,各行各业不可避免融入数字化的大潮之中。“数字化”作为人们关注的领域和热点,在社会发展中出现的频率也越来越高,将给人们生产、生活和思维上带来彻底改变,也从根本上促进农业行业向智能化的方向发展。灌区在中国社会经济发展中扮演着至关重要的角色,作为大规模的水资源管理和利用设施,确保了大面积耕地的有效灌溉,支撑了粮食生产和经济作物的产出。据统计,全国大约49%的耕地面积依赖于灌区灌溉,为中国的粮食安全提供了坚实的基础。这些灌溉区域生产的粮食占全国总产量的75%,显示出其在国家粮食供应中的核心地位。此外,灌区还承担着生产经济作物的主要任务,其中90%以上的经济作物来源于灌溉农田,整体灌溉水利用系数约为0.548[1]。其水资源浪费主要原因是低效的灌溉和用水管理方式,由此传统灌区转向数字化是转变管理思路、提升管理水平,提高农业用水资源利用率的必然措施,对于节约水资源,适应整个社会向现代化迈进具有重要意义[2]。
在2022年12月,水利部引领了数字孪生灌区的试点项目,正式启动了48个大型和中型灌区的数字化改造工作。同时,官方发布了《数字孪生灌区建设技术指南》,详尽规划了建设内容并针对性的解答了遇到的问题。在其发展的规划中,数字孪生灌区项目着重围绕实际物理灌区为基础,依托时空数据的积累,数学模型的运用作为核心,利用水利专业知识作为指导。目标是构建一个全面涵盖灌区各要素和从建设到运营全程的数字镜像,通过智能模拟,能与实体灌区同步运行、实现实时交互,并通过不断迭代优化,确保对物理灌区的精准管理[3]。在此背景下,灌区需要满足以下条件:基于数据管理需求,利用现代信息技术如卫星、物联网等,采集各类数据的方式是通过不同种类的传感器终端,在此基础上构建灌区多来源的数据感知体系,并且按照数据所代表不同的属性进行分类和调整,建立其数据底板。在算法方面,需要将多种不同模型进行组合,因其灌区水循环特性,将多种模型组合,最终作为各种业务过程决策的依据,以帮助灌区管理结构对水资源、作物等进行更精确的管理。在数据分析上,根据传感终端传过来的数据通过现有模型进一步对数据基本反应的情况进行处理,根据灌区业务需要的基础情况作为对灌区现有状况进行决策,自动化智能管控提供依据。

农业论文怎么写
..........................
1.2 国内外研究现状
数字灌区作为复杂而庞大的信息系统工程,其具有多学科交叉、多行业,覆盖面广、功能要求高的特点[4]。灌区数字化受到诸多环境条件的影响,各国研究针对不同条件下的灌区数字化管理一定程度上存在高度的一致性。数字灌区系统的最终目的是通过集成各种先进的硬件设备和软件技术,构建一个高度集成和智能化的水利管理系统,并为灌区实际管理过程中决策提供准确、可靠、及时的灌区管理信息,实现自动化和智能化管控。
1.2.1数字灌区发展现状
1.2.1.1 国内灌区数字化发展现状
我国灌区发展大致分为三个阶段,第一个阶段是1949年至1979年间,处于大规模工程建设时期,农田灌溉面积从1593万公顷发展到1980年的4889万公顷,主要解决人民吃饭问题。第二个阶段是1980年至1990年期间,农村土地经营及灌区管理体制改革,形成了税费改革、多种经营、多种形式的责任制,与1989年出台了“劳动积累工”制度。第三个阶段是1999年至2017年,以“节水挖潜促进发展”时期,对大中型灌区后续配套与节水改造建设为主要目标,加快了末级渠系建设、田间工程配套建设[5]。自2000年开始的续建配套与节水改造工作取得了显著成效。灌区原先存在的严重病险问题和“卡脖子”工程得到了有效的解决,骨干工程的配套设施得到了显著提升,设施的完好率大大提高,灌排基础设施的整体状况得到了改善,灌溉效益得到了恢复和增强。然而,灌区工程的复杂性不容忽视。作为由多项工程组成的系统,每个环节都可能存在独特的问题,例如老化设施、技术兼容性、维护难度等。此外,由于灌区服务直接服务于农业生产,它的运行管理需要跨多个节点和多个过程进行协调,这要求管理技术不仅要高效,还要具备灵活性和兼容性,以应对不同的需求和情境。因此,灌区管理面临的挑战包括但不限于:如何优化节点间的协同工作、如何提升技术与手段的集成性、如何实现智能化的远程监控和故障诊断,以及如何培养一支能够有效管理多元设施的高素质团队。这些都是保障灌区持续稳定运行和提高灌溉效益的关键因素。但随着社会现代化的逐步加快,仅对灌区灌排工程等进行升级已很难满足数字灌区更高服务的需求。自2020年以来,国家一号文件围绕乡村振兴和农村现代化的篇幅大量增加,《乡村振兴战略规划》提出要加快农村现代化步伐,水利部印发《关于开展“十四五”大型灌区续建配套与现代化改造实施方案编制工作的通知》,指出在十四五期间将开展灌区现代化建设工作。
.............................
2. 数字灌区系统模型与管理系统构建方法
2.1 数字灌区管理系统模型
数字灌区管理系统模型包含了作物仿真模型与基于作物生长模型的灌区管理决策模型。同时,灌区数字化作为深化灌区建设的关键途径,其数字化能力能够为提高灌区资源利用效率、提升用水效率和优化管理提供有力的支撑[61],模型在灌区管理系统中起着重要作用[62],能够将基础数据转换成为评价和决策的直观数据。本节主要介绍数字灌区管理系统的具体模型,分别为气象数据分析模型、土壤数据分析模型、病虫害识别模型和作物仿真模型。
2.1.1 作物生长模型
AquaCrop模型源于FAO关于作物的产量与水分关系模型的改进,主要用于模拟作物对水分供给的敏感性及生物量产量的响应过程。通过生物量与收获指数来表示农作物生产力,其中生物量的生成过程通过模拟植物冠层发育和根系生长来实现。同时模型侧重于作物对环境因素的影响,如土壤湿度和施肥量等,因为这些因素能直接影响冠层对变化的适应,以上相应的响应机制进一步对作物产量起影响从而间接影响作物的产量[43]。
........................
2.2 数字灌区管理系统构建方法
数字灌区管理系统主要由两部分组成,首先是整体系统的构建,通过使用Spring Boot微服务框架来搭建。其次是模型与系统之间计算数据交互,通过FastAPI作为模型计算的框架来实现计算过程。(针对关键框架图)
2.2.1 Spring Boot 微服务框架
Spring Boot通过Spring框架发展而来,由Pivotal团队开发的全新框架[81],其框架的理念是简化微服务开发,通过约定优于配置的方式,为了让开发者更快能够启动和运行项目。采用MVC(Model-View-Controller)模式,但它的设计更加现代化,允许组件化和模块化,使得前后端分离更为清晰。前端专注于用户界面,而Spring Boot的后端主要处理数据处理、API的创建和管理,通过RESTful风格的接口与前端进行通信。它也支持前后端技术栈的多样性,可以轻松地与其他现代前端框架集成,利用其他模块来提高代码质量[82],基本满足本文的系统开发需求。这也是现在较为主流的Web网站开发风格,Spring Boot简化了配置流程以便可以更加便捷快速进行开发,主要利用了微服务架构将应用拆分为小的、独立的服务,每个服务更加专注于一个特定的业务功能。此外Spring Boot还有以下特点:
(1)Spring Boot允许服务模块化,每个服务都是独立的jar包,可以独立部署,相互不受影响。表现为其应用程序可以单独的导出为jar格式文件,能够独立运行。从而有利于提高开发的效率和降低其耦合度[83]。
(2)不强制绑定到特定的容器,而是提供容器的灵活选择例如Tomcat、Jtty等。框架直接内置网页端运行的环境,直接使用命令行开启运行,无需传统的网站部署模式。使得微服务可以根据实际需求选择合适的运行环境[84]。
(3)Spring Boot提供了许多的预设配置,例如:自动配置数据库连接、RESTful API、健康检查等。原则上使用约定大于配置,尽可能简化配置做到打开即用。
(4)易于扩展,提供了丰富的特性扩展,由于其模块化和插件化设计,新功能添加通常只需要引入新的依赖,无需修改现成的的代码,如指标、外部化配置和健康检查等。
(5)提供了丰富的管理端点,便于监控和调试。其使用了RestTemplate和Actuator模块使得创建Restful API变得简单,简化API开发。
..........................
3. 数字灌区管理系统设计和功能实现 ...................... 39
3.1 系统总体设计目标 ..................... 39
3.2 系统架构设计 ............................... 40
4.基于灰狼算法的旱区典型作物灌溉制度优化方法 ........................... 71
4.1 灌溉制度优化模型 ............................ 71
4.2 棉花灌溉制度优化 ................................. 73
5. 基于多目标优化的种植结构优化方法 ........................... 106
5.1 种植结构优化模型 ............................ 106
5.2 种植结构优化效果 ............................. 108
5. 基于多目标优化的种植结构优化方法
5.1种植结构优化模型
本节优化目标是总产量和总经济效益。通过种植制度优化模型,不断寻求最小绝对值,使模拟目标继续接近目标值,最终达到最优总产量和总经济效益。模型中的决策变量分别是种植面积和灌溉量组,约束条件是种植总面积和单次灌水量的上限和下限。
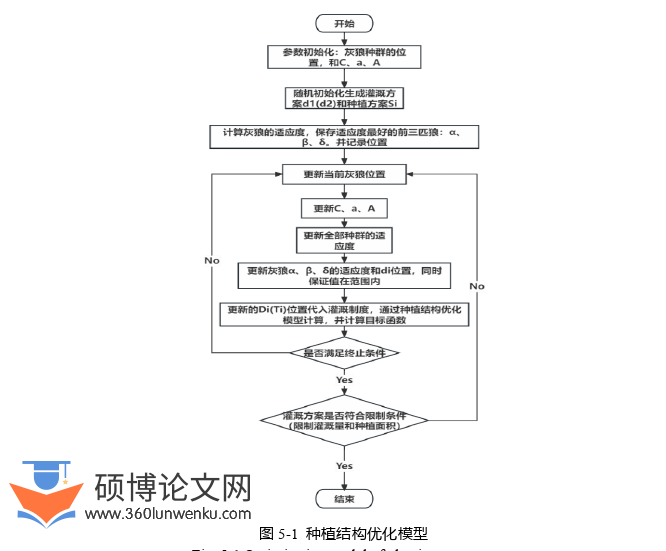
在种植结构优化模型中使用优化单次灌溉量的方案来获得最优产量。在限制了每种作物的种植面积和单次灌水量的基础上,通过固定的总灌溉量来优化分配在所有作物上的单次灌水量,同时在优化目标函数中设置了灌区总经济价值和总产量两种优化目标函数。在种植结果优化模型中,每种作物除种植面积为该作物种植面积外,还有灌水量的组数n设置为10。如在本节优化中总计需要初始生成22个数据,前两个数据分别为棉花和玉米的种植面积,后20个数据分别对应棉花和玉米的单次灌水量。在灰狼优化中,搜索代理的数量为100,最大迭代次数为10000。种植结构优化过程如图5-1所示:
农业论文参考
............................
6. 展望与结论
6.1 主要结论
随着国家对灌区的投资力度逐渐加大,其数字化的程度占比不断增高,同时也给数字灌区的建设带来挑战。面对复杂灌区情况的背景下,我们围绕灌区作物生长实际的各个过程进行设计分析研发了基于作物生长的旱区数字灌区水资源优化管理系统,能够满足数字灌区中数据可视化以及模型模拟等需求,并且将数字地图同设备还有灌区中实体农田等进行管理,数据有效融合操作等方式结合,为灌区管理人员提供实时可视化的监控手段。同时在决策上,通过群智能优化算法同作物模型进行耦合构建了灌溉制度优化模型和种植结构优化模型,初次融合作物整个生育期的时空尺度上优化设计,并为其在系统中提供操作模块,为数字灌区提供决策支持。本文的主要贡献有以下结论:
(1)基于作物模型的灌溉制度优化模型的构建。灌溉制度是灌区中作物生长的重要管理措施,通过对灌溉制度的分析,其主要受到作物生长过程中多因素影响,例如:气象条件,耕作土壤,作物等。由于传统的灌溉制度为固定灌溉频率和灌溉量的情况,存在一定不合理。本文结合群智能优化和作物生长模型构建了灌溉制度优化模型。探讨两种优化策略,固定灌溉频率下优化灌溉量和固定灌溉量下优化灌溉频率。在统一气象条件和土壤条件下,对棉花作物进行灌溉制度优化。优化结果在固定灌溉频率下优化灌溉量的方案中,相比传统灌溉制度产量提升10%~20%,且最高产量为7.3 t/ha。在固定灌溉量下优化灌溉频率的方案中,相比传统灌溉制度产量提升14%~27%,且最高产量为8.3 t/ha。表明灌溉制度中灌溉频率更为重要,同时灌溉制度优化模型效果较好。
(2)同时灌溉制度优化过程中在总灌溉量为450 mm下,三种灌溉制度(传统灌溉制度、优化灌溉量和优化灌溉频率)的作物生长情况,产量分别为6.51、7.30和8.30 t/ha。在土壤储水量中,在优化后的两种灌溉制度中整个灌溉期间40~80 cm根区的土壤水分保持在181 mm左右,处于田间持水量,但在灌溉量一致的情况下,意味着传统灌溉制度比优化后的灌溉制度造成更大的深层渗漏。在累积蒸腾量分别为481.40、468.45和469.57 mm和生物量为1489.71、1481.26和1461.31 kg/m2,表明三种灌溉制度对作物蒸腾和生物量积累的影响很小,由此棉花产量的差异是由基于等式的HI引起的。对比三种灌溉制度,优化模型在优化过程中的早期低灌溉量或长灌溉间隔产生了一定的水分胁迫,从而减少了冠层覆盖,HI提高0.03左右,从而使得产量提升。
参考文献(略)