本文是一篇计算机论文,本文构建了一种学生学习行为分析模型,旨在运用现代信息技术促进教育教学发展,提高学习效率和学习效果。
第一章 绪论
1.1 研究背景与意义
1.1.1 研究背景
不断改进教育教学、提升人才培养质量是国家教育发展的核心任务。《国家教育事业发展“十三五”规划》提出:“全力推动信息技术与教育教学深度融合。”并鼓励学校利用大数据技术开展对教育教学活动和学生行为数据的收集、分析和反馈,为推动个性化学习和针对性教学提供支持。并且在《教育事业发展“十四五”规划(2021-2025)》中,明确指出要进一步推进智慧教育建设。
智慧教育也即教育信息化,是数字时代的教育新形态,旨在运用现代信息技术促进教育管理、教学、科研等领域的发展。近年来,随着信息技术的发展,各领域数据积累达到了前所未有的数量。校园一卡通详细数据、教务系统中的各科成绩、图书馆的借阅信息以及校园档案中心的学生个人信息等共同构成了庞大的教育数据[1]。同时,伴随着机器学习、云计算等数据分析技术的迅速发展,智慧教育重心已经逐渐由服务建设、数据积累向数据挖掘转变[2-4]。这一转变使得数据可以帮助学生、教职工更为精准的开展一系列工作,不断加深对学生学习、生活情况的了解,提高学习效率与质量,这也正是目前智慧校园需要解决的核心问题。
近年来,智慧校园建设逐步完善,学生在校学习、生活数据都可以被很好的记录下来。通过对这些行为数据进行挖掘,不仅可以获得学习者的特点、认知、学习风格等,还能一定程度反应学习状态,为个性化学习和针对性教学提供数据依据[5]。
.........................
1.2 国内外研究现状
随着教育视角从“以教为主”转变为 “以学生为中心”,学习行为分析这一课题被越来越多的学者所关注,通过课堂观察、录像分析、访谈等方式探究学生学习行为与学习质量之间的联系[7-10]。本文接下来对近年关于教育数据的国内外研究进行简要总结,为学生学习行为特征建模提供参考作用。
1.2.1 国外研究现状
对学生学习情况的研究,一直是世界各国教育学、教育技术、人工智能和统计学等领域的研究热点[11-13]。从教育信息科学与技术的视角来看,利用交互学习环境,可以更好开展学习分析与教育数据挖掘(Educational Data Mining, EDM)研究。
Adams J(2007)等学者通过探究得出学生的学习行为活动与他们的学习方式、生活习惯相关联[14]。Pistilli M (2010)等学者尝试利用美国普渡大学的学生数据构建学业预警机制。几年后,Arnold(2012)等人在普渡大学开发了Course Signal系统,利用学生基本信息、课程成绩、学习经历等方面的数据建立学业预警模型,并以email的方式对学生提供实时反馈,有效提高了学习成绩[15]。Lindsey(2014)通过挖掘学生的学业成绩,提出了一种根据预测学生所学专业必须的技能需求,以此来弥补学生在自我学习过程中的偏科与不足[16]。Grivokostopoulou(2014)等学者利用决策树算法,通过学生平时测试成绩对期末成绩进行预测,帮助老师了解学生学习质量[17]。Sweeney(2015)等学者利用K-means聚类算法、多元线性回归模型对学生是否存在学业危机和下一学期成绩进行预测[18]。Elbadrawy(2016)等学者则是利用个性化分析和矩阵分解的技术对学习成绩进行预测[19]。Almutairi(2017)等人基于协作过滤算法、矩阵分解和量分解等算法开展了成绩预测方面的研究,根据实际的密苏里大学的数据验证,对学生是否无法毕业进行早期预测[20]。Lei Pan(2020)等人利用RF(Random Forest)算法探究了作业分数与期末成绩之间的联系,并借助预测结果建立了学生干预框架,对有挂科风险的同学进行及时干预[21]。
...........................
第二章 相关理论介绍
2.1 多标签分类相关知识
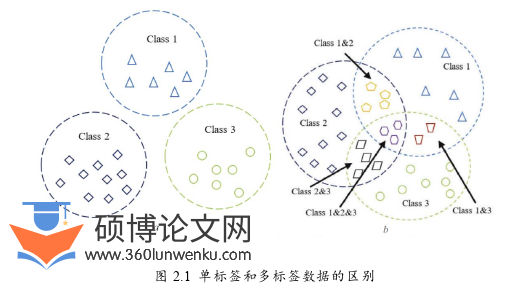
分类问题是机器学习中的经典问题,它是通过挖掘已知样本中蕴含的关系,构建分类模型以预测未知实例的所属类别。在传统的分类问题中,类别间具有互斥关系,一个实例仅属于一种类别。然而,随着信息技术的高速发展,数据所包含的信息内容不断丰富且划分越来越细,因此,对各种实例进行有效标注与处理成为了数据分析的重点。如图2.1(b)所示,当数据中需标记的实例可同时属于多个类别时,预测并标注这些类别就成为了一个多标签分类问题。
计算机论文怎么写
.........................
2.2 集成学习算法
在分类问题中,集成学习顾名思义,就是将多个独立的分类器集成起来的算法。在集成学习的思想下,已经生成了许多优秀的算法,如:XGBoost、随机森林和极端随机树等。
集成学习的核心理念是,综合多个基分类器以得到优于单个分类器效果。那么可想而知,集成学习对基分类器的选择是有一定要求的。首先,基分类器的分类准确率应不低于50%,以确保对最终结果的影响为正相关。其次,我们应确保基分类器间满足相互独立且不同,所谓“不同”是指选择基分类器要有足够的随机性,来保证个体之间的差异。试想如果每一个个体分类器都只能处理相同类型的数据,那么无论怎样优化集成策略,都会表现出较低的泛化能力。
基分类器若想要保证很好的分类性能,就会降低多样性,反之亦然。因此在不同算法中,侧重点也不尽相同,就拿本文涉及的两种集成学习算法为例,其中随机森林偏向于构造最优的基分类器以确保最终分类效果,而极端随机树则适当降低基分类器准确率来提高算法运算效率和泛化能力。如何平衡准确和随机这两个因素,也是集成学习算法研究的核心。
2.2.1 随机森林
随机森林(Random Forest)是一种著名的集成学习方法,融合了 Boosting和Bagging这两种算法的特点,在许多领域都取得了显著成效。
随机森林的构建核心主要有样本抽取和算法集成两部分,其中样本抽取过程利用Bagging的算法思路,对数据进行随机、有放回的抽取(抽取样本和属性,删除重复属性),形成新的数据集作为弱分类器的训练数据;集成则采用Boosting算法思路,用弱分类器结果提高其它弱分类器的识别率,减小最终结果的偏差,简单来说,就是收集每一个弱分类器的分类结果,然后通过投票规则来确定最终结果。随机森林算法在数据选取过程中引入随机性,可以有效降低过拟合,并且因其具备训练速度快、易并行等优点,能够有效缓解多标签分类计算量较大的问题。
.......................
第三章 基于簇状关系的层次多标签分类方法 ........................ 15
3.1 算法模型简介 ....................... 15
3.2 算法构建 ............................ 15
3.3 实验结果与分析 ........................ 18
第四章 自适应规模的极端随机森林分类算法 ....................... 23
4.1 极端随机树简介 ........................ 23
4.2 算法构建 ........................................ 23
4.3 实验结果与分析 .............................. 28
第五章 学生学习行为分析模型的构建与应用 .................... 33
5.1 模型设计 .................................. 33
5.2 模型构建 .................................... 34
5.3 模型应用 .......................... 37
第五章 学生学习行为分析模型的构建与应用
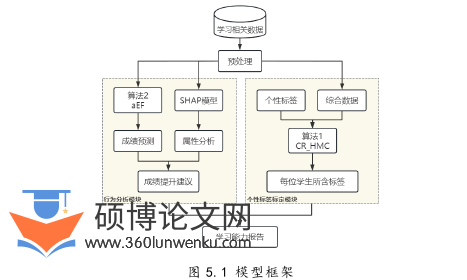
5.1 模型设计 为方便表述,本章用算法1指代第三章提出的“基于簇状关系的层次多标签分类算法”,算法2指代第四章提出的“自适应规模的极端随机森林分类算法”。
学生学习行为分析模型主要由行为分析模块和个性标签标定模块两部分组成。其中,行为分析模块将采用算法2和SHAP模型对学生成绩进行预测,并探究各个属性对成绩的影响,通过预测结果以及影响因素对学生学习行为进行指导建议。而在个性标签标定模块,则是利用算法1对学生学习特点进行挖掘,在这部分需要先根据数据内容建立学生个性标签库,然后进行标定,这里的个性标签往往是可以代表学生某行为的关键词。
模型通过两个模块分别对学习行为与成绩的关联以及行为本身进行分析,全方位展示学生学习情况和学习能力。最终,本文将构建学习行为分析系统,在系统内应用模型对数据库中学习行为数据进行分析处理,并利用可视化技术对结果进行展示,为教师管理和学生学习提供可靠的数据支撑。
学生学习行为分析模型框架如下图5.1所示:
计算机论文参考
...........................
第六章 总结与展望
6.1 总结
智慧教育是数字时代的教育新形态,旨在运用现代信息技术促进教育管理、教学、科研等领域的发展。近年来,随着信息技术的发展和智慧校园建设逐步完善,学生在校学习、生活数据都可以被很好的记录下来,如何通过这些数据,探究学习者的特点、认知、学习风格等,正是目前智慧校园需要解决的核心问题。
对于学校而言,运用数据挖掘技术对教育数据进行收集、分析,有助于缓解低师生比带来的教学影响,提高管理能力和管理效率;对于学生而言,利用数据分析结果了解自身的学习情况、学习状态将更加及时与准确,有助于发现学习中的薄弱点,自查自省。基于以上需求,本文主要做了如下工作:
(1)提出了一种层次多标签分类方法。针对目前多标签分类问题计算量大、标签间关系易被破坏和可解释性弱等问题,提出了一种基于簇状关系的层次多标签分类方法。该算法首先利用局部策略,对样本集中的标签进行多次聚类,形成带有层次关系的标签簇;然后对标签簇进行语义赋予代替原始标签,降低计算复杂性。接着通过标签簇划分数据,形成不同数据集对局部模型进行训练生成聚类树,最后利用集成思想将簇状聚类树构造为随机森林分类模型,提高算法性能和泛化能力。
(2)提出了一种极端随机森林分类算法。针对极端随机树基分类器准确率低、参数为经验选取的问题,提出了一种自适应规模的极端随机森林分类方法。该方法首先将准确率作为权值加入到的投票机制,提升了算法的拟合能力;然后加入自适应机制在默认参数周围探寻最优的参数选择,提高算法分类效果。
参考文献(略)