本文是一篇软件工程论文,本文是一篇软件工程论文,本文在获取到的轨道交通领域设计规范的基础上进行知识图谱的构建研究,着重研究了面向轨道交通领域的命名实体识别方法和关系抽取方法。
1 绪论
1.1 研究背景及意义
轨道交通工程建设是拉动国民经济增长的一项重要发展战略。国家“十四五”规划明确提出要重点推动轨道交通领域的工程建设,强调加强轨道交通工程技术的研发应用,以实现轨道交通领域的智能化、现代化[1]。近年来,我国的城镇化进程持续推进,轨道交通领域的工程建设需求日益增长,建设周期不断缩短。因此,强化对轨道交通领域的科技赋能,提升轨道交通领域信息化、智能化的建设速度已经成为刻不容缓的趋势。
轨道交通领域的工程建设周期包括规划、设计、施工、验收等多个环节,其中设计环节是保证工程建设质量的核心环节,轨道交通领域设计规范是约束此环节的重要文件。在轨道交通领域工程建设设计环节过程中,设计人员需要参考大量的设计规范,这些规范是我国经过多年经验沉淀和反复论证的成果,由轨道交通领域内的专家编写,其中包含了大量的专业术语。此外,工程验收工作也是极其重要的,传统的基于人工验收的方式存在主观性强、效率低下、漏项情况频发等众多问题。于是,引入自动合规性审查(Automated Compliance Checking,ACC)[2]成为提高工程建设质量和验收效率的重要手段。设计规范的结构化存储是实现设计要求和ACC的关键步骤,为设计和验收等阶段的任务执行提供了重要的信息化支撑。轨道交通领域设计规范作为轨道交通领域知识的重要载体,所以,对其进行结构化存储,构建一个高质量的领域知识库,是轨道交通领域信息化、智能化建设的重要前提。
.....................
1.2 国内外研究现状
1.2.1 知识图谱研究现状
基于图论和语义网络的理论基础,知识图谱以结构化、语义化的方式进行知识的组织和表示。近年来,知识图谱得到学术界及工业界的重点关注[12]。为了增强搜索引擎的能力并改善用户的体验,2012年5月知识图谱被谷歌公司提出[13]。知识图谱由节点和边组成,其中节点代表现实中存在的实体或概念,而边代表这些实体或概念之间的关系或属性,通常采用<头实体,关系,尾实体>或<实体,属性,属性值>三元组的存储形式描述海量数据中的事实知识。知识图谱在显示知识结构关系[14]等方面备受青睐,它以形式化的方式描述实体及其之间的关系,并可以对结构化知识进行可视化的展示,目前已经有大量的知识图谱投入到了实际的应用中。
在维基百科的官方词条中,知识图谱是Google用于增强其搜索引擎功能的知识库[15]。如今的知识图谱已被广泛用来指代各种大规模的结构化知识库。从知识图谱的应用覆盖范围来看,目前知识图谱主要分为两大类,一类是以大规模的常识为基础,对知识的覆盖面比较广的通用型知识图谱。国外的通用型知识图谱研究工作已经持续多年,例如有谷歌的FreeBase[16]、德国莱比锡大学和曼海姆大学的DBpedia[17]、德国马普所的YAGO[18]等;国内的有zhishi.me[19]、清华大学的XLore[20]、以及复旦大学知识工厂实验室的目前超过1700万实体、2.2亿关系的CN-DBpedia[21]等。另一类则是针对特定领域语料库所构建的领域型知识图谱,其构建过程需要由领域专家参与协作[22],例如IMDB[23]、MusicBrainz[24]等。目前,知识图谱在许多领域都取得了显著的研究进展,并广泛应用于信息检索[25]、智能问答[26]、个性化推荐[27]等众多下游任务。
...........................
2 相关理论研究
2.1 知识图谱构建概述
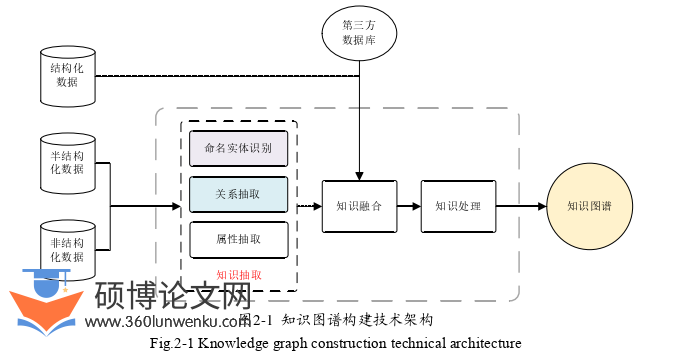
知识图谱是一种高效地进行数据组织和表示的手段,可应用于处理海量复杂数据。知识图谱具有两种构建方式,一种是通过自顶向下的方式进行构建,另一种则是以自底向上的方式进行构建。自顶向下的知识图谱构建方式依赖外部已有的知识库,通常由领域专家进行领域知识的归纳和总结,对本体建模形成知识图谱的概念框架[69],在此基础上通过对本体信息的提取进而进行知识图谱的构建。在知识图谱发展初期,这是一种简单而有效的方法。自底向上的知识图谱构建方式依赖于互联网的海量数据,实现知识的自动获取和加工,从而进行知识库的构建。该方式借助于近年来行之有效的知识获取方法和知识加工手段,已经成为现阶段知识图谱的常用构建方式。知识图谱构建技术架构如图2-1所示。
软件工程论文参考
.....................
2.2 深度学习相关理论介绍
2.2.1 Seq2Seq模型及注意力机制
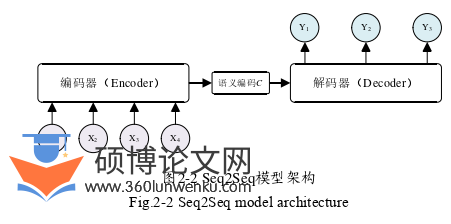
序列到序列(Sequence to Sequence,Seq2Seq)模型[70]是经典的编码器-解码器(Encoder-Decoder)模型,其基本思想是利用两个RNN分别充当编码器和解码器。Seq2Seq模型的编码器负责将输入序列编码成固定长度的上下文语义向量C,而解码器负责将编码器输入的C进行解码,进而生成指定的输出序列。该模型的优点是可以有效地处理可变长度的输入输出序列。
在Seq2Seq模型中,语义向量完全通过编码器生成。通常情况下,为了获得更多的编码器信息来生成准确的输出序列,解码器会通过对所有输入的隐藏状态进行线性变换来获得语义向量。但将固定长度的语义向量直接用作解码器的输入的效果不太理想,该方法可能会丢失输入序列的一些重要信息。Seq2Seq模型架构如图2-2所示。
软件工程论文怎么写
注意力(Attention)机制在NLP领域中最初用于Seq2Seq模型下的机器翻译任务[71]。该机制通过对序列中的每个词汇施加不同程度的注意力,从而使序列中的任意一个词汇能够通过收集其他词汇的信息来获取更多的上下文信息,收集信息的标准是其他词汇与该词汇的相关度。通过不同的权重分配,注意力机制使神经网络更加关注于重要性程度高的特征,从而减少对无关信息的学习。
..........................
3 面向轨道交通领域的命名实体识别方法 ........................ 17
3.1 模型概述 ......................................... 17
3.1.1 预处理层 ................................... 18
3.1.2 预训练层 ............................... 21
4 面向轨道交通领域的关系抽取方法 ...................... 35
4.1 模型概述 ................................... 35
4.1.1 编码层 .................................... 37
4.1.2 关系分类层........................... 38
5 轨道交通领域知识图谱检索系统的设计与实现 .............. 47
5.1 需求分析 ................................. 47
5.2 系统架构 .............................. 48
5 轨道交通领域知识图谱检索系统的设计与实现
5.1 需求分析
在搭建轨道交通领域知识图谱检索系统之前,需要针对该系统进行需求分析。搭建该系统的目的在于方便轨道交通领域相关从业人员进行知识检索,以图结构化的形式呈现相关实体信息及实体间的关系信息。经过对轨道交通领域使用场景的调研和总结后,提出如下需求:
(1)检索功能。系统应提供检索功能。系统中包含大量关于轨道交通领域的专业术语实体以及实体间的关系信息,用户应通过搜索可以快速找到所需知识及其相关资料。
(2)上传功能。系统需要提供上传接口,允许用户上传原始数据。上传接口应具备手动上传和批量上传功能。手动上传功能允许用户手动对轨道交通领域知识图谱增加实体和关系,而批量上传功能则支持用户使用Excel或其他标准格式进行数据的批量上传。
(3)编辑功能。考虑到轨道交通领域知识三元组的抽取过程中无法确保模型的准确率为百分之百,系统需要提供编辑功能。允许对已有实体和关系进行必要的编辑操作,包括修改、删除等常规操作。编辑操作时需要注意对相关联的实体进行更新。
(4)可视化界面。系统应提供可视化界面,以直观地展示轨道交通领域各个实体及其之间的关系,帮助用户对系统数据有更直观的理解。
(5)用户友好性。系统界面应简单友好,操作流程应简单易上手,以促进此轨道交通领域知识图谱检索系统的推广和使用。
(6)权限分级。为确保系统内数据的准确性和稳定性,系统需要设置权限分级机制,不同权限对应不同的功能范围,限制用户对该系统数据的随意更改。
............................
6 总结与展望
6.1 总结
本文的研究工作围绕面向轨道交通领域的知识图谱构建研究进行展开,主要完成了以下工作:
(1)本文构建了轨道交通领域数据集和轨道交通领域专业术语词典。轨道交通领域数据集主要分为三部分:1)500,000条轨道交通领域预训练数据集,用于大规模无监督的轨道交通领域适应预训练。2)4,000条带标注的轨道交通领域实体数据集,用于轨道交通领域的命名实体识别训练。3)4,000条带标注的轨道交通领域关系数据集,用于轨道交通领域的关系抽取训练。轨道交通领域专业术语词典共有5465条专业术语,主要用于提升轨道交通领域的数据分词效果。
(2)本文在第三章提出了面向轨道交通领域的命名实体识别方法。在构建了轨道交通领域数据集和轨道交通领域专业术语词典的基础上,针对中文命名实体识别任务中存在的输入序列冗余、实体边界模糊、实体嵌套等问题,提出了基于非展平网格嵌入和预训练的命名实体识别模型NFL-RTBERT-E。在NFL-RTBERT-E模型中,主要采用非展平网格嵌入方式,使用多头交互注意力机制对字符信息与词汇信息联合建模,通过大规模无监督的轨道交通领域适应预训练和基于Span的轨道交通领域命名实体识别任务训练后,进而分类得到准确的实体识别结果。本章提出的NFL-RTBERT-E模型在轨道交通领域实体数据集上可以达到79.64%的F1-score值。通过与其他模型进行对比实验,可以看到NFL-RTBERT-E模型的F1-score值相比于次好方法提升了4.02%,证明了本章提出的NFL-RTBERT-E模型的优越性。针对模型进行了详尽的消融实验,可以看到NFL-RTBERT-E模型中各个模块的有效性。
参考文献(略)