本文是一篇软件工程论文,本文主要针对防御性深度学习模型的对抗性样本生成研究,提出了一种基于卷积神经网络的迭代训练攻击方法,设计了最易扰动损失函数和迭代训练方法。提出了一种基于多层感知机的对抗性补丁生成方法,一种基于Transformer自编码器结构的对抗性样本生成方法。
第一章 绪论
1.1 研究目的与意义
深度学习在传统机器学习算法解决的难题上提供了有效解决方案,越来越多的学者和研究人员提出了更为先进的网络架构如残差网络(ResNet)和注意力机制的结构Transformer等。深度学习在IOT和自然语言处理中的应用越来越频繁,尽管深度学习模型能够解决和预测复杂的问题,但深度学习的自身安全一直是人们担心的关键问题。深度学习容易受到对抗性样本的影响早在图像分类的机器学习任务上已经被证实,对抗性样本的攻击方法通过对深度学习神经网络模型的输入添加较小的扰动来欺骗目标深度神经网络,使其分类错误。
通过在原始图像上添加较小细微的扰动噪声而影响深度神经网络的攻击方法称为对抗性样本攻击,而添加了扰动噪声后的输入样本称为对抗性样本。对抗性样本包括但不仅仅限于图像分类、目标检测、文本翻译、图文转换和自然语言识别等。对抗性样本不仅仅能够影响深度神经网络的分类结果降低其分类的精确度,还可以使被攻击的深度神经网络输出固定的分类结果。对抗性样本也可以用来评估模型的可靠性和安全性,这使得深度神经网络在实际应用之前,可以使用对抗性样本来测试深度神经网络模型稳定性和神经网络的鲁棒性。同时,对抗性样本的欺骗性和攻击性给深度神经网络模型在应用上带来了一定的危害。例如,攻击者可以通过对抗性样本攻击方法生成物理的对抗性样本图像,来解锁智能手机的人脸识别。攻击者对物理世界的交通标志进行光线干扰和引入对抗性的噪声,从而影响无人驾驶的任务识别。
近期的研究表明了对抗性样本的攻击方法是可以被防御的,对抗性样本的防御方法是通过检测输入、加固深度神经网络本身和对输入进行重新构建相似类别输入等方法来减少对抗性样本对神经网络模型的影响。这些防御方法在一定的对抗性样本噪声范围内可以达到有效的防御性。通常它们的防御都是基于已知的梯度信息和攻击者的优化方法和损失函数,寻找对抗性样本和普通样本之间的差异。一些防御方法甚至能抵御一些未知的攻击策略,防御方法能够提高深度神经网络对对抗性样本的鲁棒性。
....................
1.2 对抗性样本攻击和防御的国内外研究与现状
本节介绍对抗性样本的研究现状,包括对抗性样本的攻击原理、对抗性样本的攻击发展现状、对抗性样本的防御发展现状和对抗性样本应用现状。
1.2.1 对抗性样本攻击原理
Szegedy[1]等人最先发现了一个有趣的现象,包括最先进的神经网络在内的几种机器学习模型容易受到对抗性样本的影响。在许多情况下,在训练集不同的子集上训练具有不同体系结构的各种模型都对同一个对抗性样本进行了错误的分类。这表明了对抗性样本揭露了神经网络模型训练中的基本盲点。起因是因为深度神经网络模型都是极端的非线性,与模型平均值不足和纯监督学习问题的正则化不足相结合。
对抗性样本的存在是由于模型的线性输出,在许多问题中,单个输入特征的精度是有限的,通常数字图像中每个像素只使用8位来表示,因此模型丢弃了数字信息上小于1/255之间的所有信息。因此,对抗性样本产生的原因是特征的权重精度是有限的,如果生成的对抗性样本的每个像素的扰动????都小于特征的精度,则分类器对正常输入????和对抗性样本的输入????′将会是相同的。
对抗性样本的另外一个分支是对抗性补丁,对抗性样本是针对全部图像进行攻击,而对抗性补丁则是在图像中局部的加入扰动来攻击模型分类。对抗性补丁是在原始图片中添加一些看似无害的、人类难以察觉的像素点或者区域,使得机器学习模型在对这些图片进行分类时产生错误的结果。攻击者的目的是针对特定的模型或者应用程序,在不知情的情况下对其进行攻击。对抗性补丁的生成过程通常基于生成对抗性样本的技术,这些样本可以使用多种技术生成,包括基于梯度的方法、进化算法、对抗性生成网络等。
..........................
第二章 相关理论与技术
2.1 防御性深度学习模型

软件工程论文怎么写
深度神经网络在传统机器学习算法解决的难题中提供了解决方案。在硬件计算机的计算性能增长下,深度学习在机器视觉、自然语言处理和语音识别等方向上取得了重大突破。深度神经网络从一开始求解问题的不稳定性逐渐发展为到商业化的发展,例如人脸识别、ChatGPT和车牌识别等。深度神经网络的安全性也变得极为重要,对抗性样本的发展给深度神经网络带来了一定的危害,但也说明了神经网络的训练解决方案的盲点。因此对深度学习模型进行防御成为了至关重要的研究,防御性深度学习模型是指深度学习模型在使用对抗性防御方法的模型。防御性深度学习模型提高了抵御对抗性样本的能力,但往往也会下降损失部分精度。例如在ResNet上进行对抗性训练的PGD-AT方法,在CIFAR-10上,进行了梯度投影下降的对抗性训练的方法获得了ResNet模型。在Gowal的对抗性训练方法在Wide-Resnet上防御了大部分的梯度的对抗性样本攻击方法。Huang[35]等人在经验风险最小化的统计学原则下对WRN-34-10神经网络进行了加固训练并且能达到83.48%的精确度。DeepCloak[36]使DNN模型中在分类层之前插入掩码层,并将不必要的神经网络层掩码设置为零,从而有效的将对抗性样本过滤掉。
........................
2.2 数据集
数据集是深度神经网络学习任务的输入,也是模型参数的来源。使用公共的数据集有利于模型学习到样本特征,和公平性的对比模型的实验。本文旨在研究图像上的对抗性样本的防御和攻击方法。在图像上有ImageNet、 COCO、PASCAL VOC、CIFAR等数据集。其中MNIST、CIFAR-10和ImageNet是深度学习在机器视觉中使用最广泛的数据集。MNIST手写数字数据是图像中最小的数据集,它集包含60000个样本的训练集和10000个样本的测试集,MNIST图像的像素尺寸为28x28,图像只有单个通道,所以图像为灰度的。CIFAR-10是由Hinton的学生整理的一个用于识别普通常见图片的小型数据集。CIFAR-10和MNIST一样只有十个类别,图像的尺寸为32x32,且为3通道的彩色RGB图像。CIFAR-10与MNIST相比不仅噪声很大,且物体的比例、特征都各不相同。ImageNet是一个计算机视觉系统识别的项目,是目前世界上图像识别最大的数据库,ImageNet包含2万多个数据类别和至少一百万个图像,但在图像分类和语义分割的大多数的深度学习任务使用一千个类别。
...........................
第三章 针对对抗性训练防御的对抗性样本生成技术 ························ 18
3.1 引言 ··································· 18
3.2 研究动机 ····························· 18
第四章 针对输入重构防御的对抗性样本生成技术 ·························· 36
4.1 引言 ···································· 36
4.2 研究动机 ·························· 36
第五章 针对对抗性检测防御的对抗性样本生成技术 ······················· 52
5.1 引言 ··························· 52
5.2研究动机 ····················· 52
第五章 针对对抗性检测防御的对抗性样本生成技术
5.1 引言
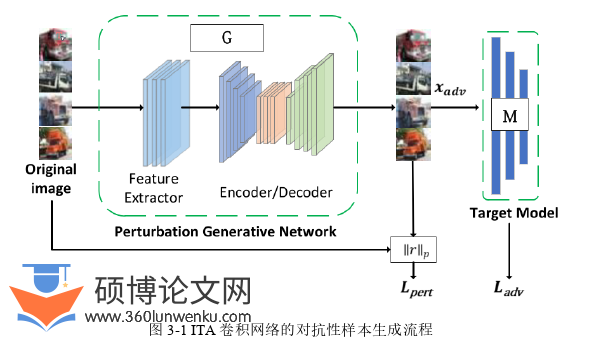
神经网络容易受到对抗性样本的影响,针对对抗性样本的梯度攻击方法的攻击原理,现有的研究已经有了很多针对对抗性样本的对抗性训练的防御方法。同时也出现了将深度神经网络二进制分类器训练为检测器,以将输入数据分类为合法干净的输入或分类为对抗性样本输入,这种方法被称为对抗性检测防御技术。检测器通过一个小而直接的网络预测二进制分类,对抗检测将机器学习模型中添加了一定的离群值,因此可以在不知道攻击者的原理的情况下,能够通过异常值来检测对抗性样本,并推断输出其可能是对抗性样本概率分布。
本章首先提出了基于Transformer的视觉对抗性样本生成算法。在训练方法上借鉴了第三章中的迭代训练算法,攻击方法基于Transformer的注意力机制的引入,损失函数中计算了对抗检测器的对抗性样本的检测范围,并对二分类神经网络检测器模型进行定向的欺骗攻击。最后生成满足对抗性样本的攻击扰动范围要求的对抗性样本,达到绕过对抗检测而攻击到目标机器学习模型的目的,以更好的攻击手段来评估模型的鲁棒性。
软件工程论文参考
..........................
第六章 总结与展望
6.1 全文总结
随着深度神经网络应用的发展,深度学习的安全性越来越重要。深度学习在人脸识别、智能驾驶、医学影像、语音识别、车道线检测和车牌识别等应用越来越广泛,这使得人们迫切的需要确保深度神经网络的可靠性和安全性。特别是在对抗性样本精心和恶心的输入设计下,深度神经网络的性能往往非常脆弱。对抗性样本的影响导致了对抗性样本的防御策略在过去几年中显著增长。为了评估这些防御方法的可靠性和鲁棒性,大多数的攻击方法都针对了对抗性训练的防御方法来进行攻击。如果采用更加强大或更适应的攻击,这些防御方法能够被突破。对抗训练是迄今为止无法击败的少数防御方法之一,但它需要大量训练和已知对手的攻击方法。输入重构转换的方法让对抗性样本转换为相似的原始图像,从而过滤掉对抗性扰动。对抗性检测的防御方法是使用外部的神经网络来检测计算输入为对抗性样本的异常值或者概率分布,从而判断并过滤掉对抗性样本的输入。这些防御方法有效的防御了一些攻击方法,但防御性深度神经网络的安全性需要更强大的攻击方法来进行检测。基于以上的情况,本文结合了现有的对抗性样本攻击知识和对抗性样本防御方法,提出了一种针对对抗性训练的迭代攻击算法,针对输入重构转换的对抗性样本防御方法,提出了基于多层感知机的分块输入的对抗性补丁攻击方法。针对对抗性检测的防御方法,提出了基于Transformer结构的ADT攻击方法,并设计了优化对抗性扰动的损失函数。
本文的主要工作如下:
1. 由于对抗性训练的防御方法对于基于梯度的攻击十分有效,并且基于黑盒的对抗性样本攻击方法算法复杂。在基于自编码器的神经网络的生成对抗性样本中,他们训练模型来生成对抗性样本,这种方法攻击能力有限。因此本文提出了基于卷积神经网络的迭代训练攻击方法。该攻击方法在pytorch的机器学习框架和GPU硬件平台上进行了实验测试。为了对比公平性,迭代训练攻击还对比了同类基于神经网络的对抗性样本生成方法,并对对抗性训练的防御模型进行了攻击,在MNIST上的攻击实验,ITA迭代训练的攻击方法达到了最高。对于普通的不带防御的模型,迭代训练的方法也比同类方法的效率更高,在低于100次迭代的情况下,能达到攻击率为百分之白。
2. 为了提取不同邻域和相邻像素之间的扰动特征信息来躲避输入重构器的转换,提出了一种基于多层感知机的对抗性补丁生成。设计了AD-MLP的多层感知机结构,通过拆分输入图像块,将图像块线性全连接。损失函数优化对抗性扰动和目标重构器转换的防御模型输出的均方差的最小值。为了降低生成扰动的范围限制,提出了稀疏化对抗性补丁的方法,实验验证了稀疏化的方法。
参考文献(略)